Volume 12, No. 1, Art. 21 – January 2011
CAQDAS and Qualitative Syllogism Logic—NVivo 8 and MAXQDA 10 Compared
Walter Schönfelder
Abstract: Qualitative research is a heterogeneous field comprised of different and sometimes competing analytical strategies. A growing number of researchers use computer programs to assist in the analysis of qualitative data. Some analytical tasks are common ground and will be performed by most researchers regardless of their methodological approach.
Software vendors try to accommodate an increasing demand for common and specific analytical needs and include an ever growing number of features in their products. Depending on the methodological point of departure, some functions provided in the current generation of CAQDAS packages may appear controversial because they invite the user to exceed the limits for the conclusions which can be drawn from qualitative analysis.
In this article the limits for drawing conclusions from qualitative data are discussed from a social constructivist, discourse analytical perspective. This is described with the concept of qualitative syllogism logic. Some tools provided by CAQDAS packages are used in most qualitative methodological frameworks. These are discussed before two CAQDAS packages, NVivo 8 and MAXQDA 10, are compared with regard to how intuitively they provide these basic tools along with those that appear controversial because they exceed the limits of qualitative syllogism logic.
Key words: CAQDAS; NVivo; MAXQDA; syllogism logic; qualitative methodology; social constructivism; discourse analysis; analytical generalization; quantification
Table of Contents
1. Introduction
2. Qualitative Syllogism Logic
3. Basic Features in a CAQDAS Package
4. CAQDAS and Discourse Analysis
5. NVivo and MAXQDA Compared
5.1 Starting up
5.2 The workspace
5.3 Adjusting the workspace
5.4 Handling and organizing data
5.5 Coding and retrieving data
5.6 Annotating
5.7 Retrieving data
6. Conclusion
Several scholars have provided overviews of the most common software packages for qualitative data analysis (CAQDAS) and how each of these supports particular aspects of qualitative analytical work (CARVAJAL, 2002; FIELDING & WARNES, 2009; KELLE, 1997, 2004; LEWINS & SILVER, 2007; SEALE, 2010). They provide valuable guidance for potential first time users in their discussion of the basic features provided by these programs, but remain somehow unsatisfying in that they refrain from discussing the obstacles novice users might encounter when learning software for the analysis of qualitative data. The illustrative volume of LEWINS and SILVER (2007) is the exception in this respect. It provides a detailed review of the most common CAQDAS packages including a step-by-step discussion of how various functions are supported in each program. However, all the CAQDAS packages discussed here have in the meanwhile been superseded by newer versions with new tools and, in some cases, new layouts of the program workspace. [1]
The question of what conclusions can be drawn from qualitative data analysis will be answered differently depending on the methodological framework used. All the mentioned overviews have in common that they discuss CAQDAS packages more in terms of technical aspects of the tools they provide than how they serve the needs of particular methodological frameworks. [2]
Conversely, software vendors of CAQDAS packages claim their products are suitable not only for a particular methodological approach, but for a number of research methodologies. The two programs I will review later in this article are both advertised as suitable for a wide range of methodologies. NVivo is claimed to be a tool for discourse analysis, grounded theory method, conversation analysis, ethnography, phenomenology, mixed methods research and more.1) MAXQDA is described as "methodologically multi-faceted" and designed for "hermeneutic text studies, grounded theory method and various mixed methods procedures."2) [3]
These methodologies differ with regard to their basic epistemological assumptions, analytical steps conducted and how qualitative data are displayed to sustain analytical conclusions. [4]
In the first part of this article I will discuss the possibilities and limits for drawing conclusions from qualitative data from a social constructivist, discourse analytical perspective. I describe this with the concept of a qualitative syllogism logic (Section 2). I will then discuss some basic tools provided by current generation CAQDAS packages to support analytical tasks performed across different qualitative methodologies. I will also discuss some that from my own methodological perspective appear controversial. Here I will also draw on my experiences as a teacher of CAQDAS for graduate and postgraduate students and the common pitfalls they encounter when learning a CAQDAS package (Section 3). Some authors describe the use of CAQDAS packages as limited for discourse analytical purposes. In Section 4 I argue that these limitations are based on the individual analytical approach rather than on principal methodological incompatibilities. After this general discussion of methodological aspects I will compare two of the leading CAQDAS packages, NVivo 8 and MAXQDA 103), in terms of how they provide the basic tools for qualitative data analysis and the tools that are more controversial because they can tempt the user to exceed the limits of qualitative syllogism logic (Section 5). [5]
Even though the comparison of the two CAQDAS packages is based on a particular methodological perspective and personal analytical needs, the discussion in this paper hopefully provides some useful guidance for first-time users with other methodological preferences for what to expect from a CAQDAS package in general and from NVivo 8 and MAXQDA 10 in particular. [6]
2. Qualitative Syllogism Logic
Introductory textbooks to social inquiry commonly distinguish broadly between qualitative and quantitative approaches without further discussion of variations between qualitative methodologies. For example DENSCOMBE (2007, p.248) describes this distinction in terms of a different focus on respectively words and numbers as the unit of analysis. Such a simplified presentation might to a certain extent be justified in an introductory textbook. It is however problematic because it glosses over the fact that different qualitative methodologies vary in the use they make of quantifications of information in qualitative data. Instead of a simplified distinction between qualitative and quantitative approaches the variety of qualitative methodologies should be acknowledged and the different approaches be placed on a continuum between using words or numbers to derive conclusions from qualitative data. Therefore, a discussion about the underlying logic of qualitative inquiry will depend on the particular methodological perspective of the proponents. My argument about the limits for drawing conclusions from qualitative data is informed by a discourse analytical perspective and its basic assumptions on the constructed nature of society. [7]
However, I will claim that regardless of the particular methodological framework chosen the very nature of qualitative inquiry allows certain generalized conclusions about the social phenomena in question, but also limits the possibilities to draw these on purely empirical grounds. The possibilities and the limits for drawing conclusions from qualitative data are what I want to call qualitative syllogism logic. One benchmark I will use later in my review of the two CAQDAS packages will be how these programs support this logic. [8]
I want to frame my argument for a qualitative syllogism logic with a point of departure in WEBERs (1972) "verstehende Soziologie." Here, qualitative analytical work is oriented towards the construction of ideal-typical categorizations and the description of a meaning giving frame of reference. Such frames might be labeled differently across methodological traditions as discourses, fields, systems, life worlds and so forth. Scholars like BLUMER—here quoted in CLARKE (2005, p.109)—have emphasized the fundamental importance of concepts and categories as both a precondition for and a means to interpret and relate data. Most qualitative methodologies share an approach to analysis where variations found in qualitative data are categorized into meaning bearing concepts, which in turn are used to describe and explain social phenomena. As ideal-typical constructs these concepts do not depend on a quantified distribution of values on variables. They are constructed in the interpretative analytical process and documented with quotes or excerpts from other kinds of data illustrating the intended meaning in a clear cut way. [9]
However, when looking at reports from graduate and postgraduate students, as well as experienced researchers, it is all too often evident that a research design based on a qualitative methodology does not prevent the author from quantifying qualitative data. Based on a sample not comprised according to statistical standards, such quantifications are highly problematic. Following BRYMAN (quoted in: SILVERMAN, 2010, p.144), I regard sampling in qualitative research as a process of purposive or theoretical sampling that allows generalizations to "theoretical propositions rather than to populations or universes." I agree with this perspective and will argue that "many more of my respondents said one thing instead of another" makes a weak argument at best and an invalid one at worst. This is because a sample of respondents that is neither selected randomly nor statistically representative in another way cannot provide the grounds for generalized conclusions to a population on a purely empirical basis. [10]
This point of view is hardly a prerogative of methodological frameworks with explicitly stringent standards to qualitative syllogism logic. It is also emphasized in qualitative traditions with an outspoken eclectic attitude. For example, STRAUSS and CORBIN argue in their standard textbook on grounded theory method that the choice of a particular methodological strategy should not be approached as a question of principle, but as a question of how appropriate it is for a particular research interest. However, they also point out that "each mode of research must be given its due recognition and valued for its unique contribution" (1998, p.33). Following this argument, I want to emphasize that the analytical value of whatever methodological strategy is employed must be judged according to how stringent methodological standards are followed. [11]
Another school of thought that departs from a qualitative methodological perspective includes scholars who claim that the possibility to quantify qualitative data is an important feature of a CAQDAS package (FIELDING & WARNES, 2009, p.272). In fact, most of the leading software for the analysis of qualitative data provides fairly sophisticated solutions for such quantifications. [12]
Within some qualitative methodologies, such quantifications may be considered acceptable. In strands of grounded theory method they might even be considered a basic methodological feature. From my own methodological perspective I would argue against this and repeat that generalized conclusions to a population drawn from a sample, not comprised according to any accepted quantitative methodological standard, provides the basis for a weak argument at best and a not sustainable one at worst. Furthermore, such a research strategy exceeds the limits of most qualitative methodological frameworks and, as a general guideline, should be avoided. [13]
This argument could easily be misinterpreted. First, I do not imply that qualitative research should refrain from generalizations. Those can and should be made, but not on purely empirical grounds. Instead, generalizations based on qualitative inquiry should be argued for as analytical generalizations based on the link of qualitative data with theory. Whether this link is provided by an abductive process as CHARMAZ (2006, pp.103ff.) argues for in her version of grounded theory method, or by linking empirical findings to a meta-theoretical framework, as advocated for by FLYVBJERG (2006) and KVALE (1996, pp.233ff.) is less important. In both cases the power of a convincing argument based on qualitative inquiry is established by the link between empirical data with theory and not by quantifying qualitative data. [14]
Second, an argument to abstain from quantifications of qualitative data should not be confused with an argument against a mixed method approach to analysis. Advocates of mixed methods have repeatedly emphasized that these should be perceived as complementing strategies in order to allow for more comprehensive insights (CRESWELL & PLANO CLARK, 2007; TEDDLIE & TASHAKKORI, 2009). These authors emphasize that the strength of mixed methods is a result of combining stringent qualitative and stringent quantitative analysis. An argument against quantifying qualitative data is therefore not an argument against mixed methods, but against mixing methodological standards of one approach with standards of the other. [15]
Nevertheless, most CAQDAS packages provide at least some means for quantifications. In some CAQDAS packages these means even appear as a rather prominent feature in the layout of the programs side by side with the basic tools for qualitative data analysis that I will discuss later. Tools for creating charts or cross tabulations allow for a similar presentation of qualitative data to that used in quantitative research. However, condensing and displaying qualitative data this way is far from common in all qualitative methodological frameworks. [16]
The possibilities provided by modern CAQDAS packages to visualize and condense the amount of qualitative data are appreciated. While immersed in the analytical process such visualizations can help to clear the mind and to present work in progress to others. It is not necessarily problematic that these functions are provided in a CAQDAS package, but that they occupy a rather prominent position in the workspace where they not only allow, but actually invite, the user to use them whether or not appropriate. [17]
In an ideal world, CAQDAS packages would be used only by researchers with a firm grasp of their methodologies and an awareness of the possibilities and the limitations of each tool provided by a program. In my experience as a teacher of computer assisted qualitative data analysis, novice users tend to be easily tempted by such quantifying features. There is a tendency to argue for conclusions based on a numerical distribution of certain attributes among respondents cross-tabulated with other attributes, or on the frequency of appearance of certain codes. I have argued previously that I regard it as invalid in qualitative research to found an argument mainly on a numerical distribution. For example, it is irrelevant to derive a generalized statement from 25 nurses who said one thing as opposed to 5 who said another—as long as the sample of 30 nurses participating in the qualitative interview inquiry was not created with statistical generalizations in mind. Another example concerns the appearance of codes used to categorize qualitative data. Most CAQDAS packages supply their users with a frequency count of how often a code is used. Certain methodologies may make use of such information and will require the possibility to display a frequency count and to create tables, charts or the like. From a social constructivist perspective underpinning most discourse analytical and phenomenological work the reasoning is usually evidenced through the presentation of quotes from textual material. These are used to exemplify ideal typical categorizations of a variation; e.g., of opinions, feelings, or ways of interaction. Depending on the methodological framework, this variation will be categorized in relation to concepts such as subject positions, interpretative repertoires, segments of life worlds, systems, or other concepts. In these cases, for the construction of ideal typical categorizations in a Weberian sense the frequency of occurrence is irrelevant. Consequently the analytical value of features in a CAQDAS package designed to condense qualitative data by quantifications is quite limited. Therefore, for these methodological perspectives the tools for quantifying qualitative data should be kept in the background of the workspace of a well-designed CAQDAS package. Programs designed to serve the needs of qualitative researchers who might or might not base their analytical conclusions on quantified information should provide this kind of information as an optional, not a compulsory feature. To summarize, to me the possibility of creating flashy tables is much less important than the possibility of displaying data with or without quantifying features when reviewing, coding or annotating. [18]
Instead of the number of features a CAQDAS package provides, one benchmark in my review of NVivo and MAXQDA will therefore be how prominently functions for quantifying qualitative data appear in the workspace of the programs. Another benchmark will be the possibilities the programs provide to adjust the output of analytical steps according to the users' individual preferences. [19]
In the following section I will discuss the basic features that are provided by all major CAQDAS packages and that are used in most qualitative methodologies. [20]
3. Basic Features in a CAQDAS Package
Qualitative data are "messy"—an assertion that probably most qualitative researchers can confirm. Qualitative data also tend to rapidly grow from a few innocent pages of interview transcripts or field notes (or whatever kind of data used) into a huge pile of seemingly chaotic, inaccessible and unmanageable information. Those mature enough to remember the dark old ages of qualitative analysis will recall the cut-up parts of interview transcripts scattered all over the floor, the semi-successfully attempts of sorting into analytical categories and the permanent danger of a sudden draft from open doors or windows. If not for other reasons, researchers of my generation will truly appreciate the help CAQDAS has to offer more than those who take such programs for granted. What qualitative analysis is all about is to make order out of this "mess": to manage the recorded complexity, to structure and interpret the data, and finally to present results to the reader in a convincing way. Obviously, CAQDAS packages have to provide the tools for these tasks. Their primary functions have therefore been described as storing, managing, and analyzing (JACKSON, 2003, p.97). [21]
Storage and management are hardly controversial properties in a computer program designed for assisting qualitative analysis. In fact, each of the major CAQDAS packages available today allows easy storage and management in a safe and comfortable way. More problematic is the notion of CAQDAS packages analyzing qualitative data. It has repeatedly been pointed out that CAQDAS packages do not perform qualitative analysis, but that they provide a variety of tools to support it (KELLE, 1997; MacMILLAN, 2005; SEALE, 2010). [22]
Thomas MUHR, a representative for another leading CAQDAS package, ATLAS.ti, remarked in a recent forum discussion on the CAQDAS Networking project: "A tool's intuitiveness can be taken to impressive heights, but if a variety of methodologies and styles are to be supported, the increasing number of tool functions and workflows may conflict with this effort."4) [23]
Indeed, most CAQDAS packages available today offer a long list of features that by far exceed the needs of the average user. Modern CAQDAS packages are designed to deal with a wide variety of data. They have to comply with the demands of different methodological approaches and with the needs of individual researchers as well as research groups working on the same project. Thus, CAQDAS packages have to be complex to a certain extent and pose a learning challenge for the first-time user. [24]
Still, some features are common ground and most qualitative researchers will probably expect to find them in a CAQDAS package. This would be regardless of the kind of data to be analyzed, methodological framework or whether the analysis is conducted by a single researcher or a research group. What are the basic features in a CAQDAS package then? [25]
Computer programs supporting the analysis of qualitative data can be described according to a basic "code-and-retrieve element" (SEALE, 2010, p.253); a function that allows the user to break up data into segments which can be categorized, organized in various ways, and retrieved for detailed review and in-depth analysis. Therefore, some of the basic functions provided by CAQDAS packages are those allowing the user to code data, to retrieve files or segments and to process them further. Another basic function concerns the possibilities provided to annotate specific parts of data and to create links between items included in a project file. I will discuss the tools that NVivo and MAXQDA provide to perform these basic analytical tasks in Section 5. [26]
Authors from various methodological communities, such as grounded theory method (CHARMAZ, 2006, pp.80ff.), discourse analysis (EDLEY, 2001) and others, have emphasized the importance of developing a personal working style for analyzing qualitative data. I generally regard this as a precondition for creative interpretative work and will compare the two programs in terms of the possibilities provided to adjust the workspace according to personal analytical preferences. [27]
The premises for evaluating the tools provided by a CAQDAS package vary according to personal preferences, but also the methodological perspective. Before I look closer at the features NVivo and MAXQDA have to offer, I want to discuss the analytical value of the tools described for my own methodological perspective. [28]
4. CAQDAS and Discourse Analysis
Qualitative analysis at its very core can be condensed to a close and repeated review of data, categorizing, interpreting and writing. The analytical tools applied are in some research traditions described in a sequential order. In their version of grounded theory method, STRAUSS and CORBIN (1998) distinguish between three stages of initial, axial and selective coding. Whereas CHARMAZ (2006) describes a consecutive process of initial and focused coding. Coding serves in both instances to develop analytical categories that are used to construct a general theory about the phenomenon in question. These authors also emphasize the crucial meaning of memo-writing as a means to constantly reflect about coding-scheme and data. [29]
Coding and annotating data are also used for discourse analytical purposes. However, discourse analysis is hardly a homogenous approach. It is often described as a highly contested field of competing methodologies, both with regard to the analytical focus and the methodological tools applied (ALVESSON & KÄRREMAN, 2000; BURR, 2003; GILL, 2000; JØRGENSEN & PHILLIPS, 2002, pp.173f, O'ROURKE & PITT, 2007). The main strands of discourse analytical thinking can be broadly distinguished into those focusing on the analysis of text and talk in social practices and those with a focus on the analysis of discourse as an expression of overarching systems of thought (FAIRHURST & PUTNAM, 2004; SCHÖNFELDER, 2008). Still, there are strong links between these two strands of thinking, not the least with regards to basic assumptions about the constructed nature of society and the relevance of discursive practice as a fundamental mechanism of meaning-making (WETHERELL, 1998). [30]
With a variety of approaches to analysis come different opinions among discourse analysts about the assistance CAQDAS packages can offer for analytical work. Authors like Clive SEALE claim that the use of CAQDAS is limited for the detailed scrutinizing of short data extracts as opposed to "the code-and-retrieve operations of grounded theorizing" (2010, p.259). Discourse analysts like MacMILLAN (2005) have described the value of CAQDAS packages as limited to the early stage of analysis. The limitations for an in-depth analysis of semiotics or rhetorical structures are here mainly explained by a lack of means to create a link between sound files and transcripts. This is a feature that is now provided by all major CAQDAS packages. Moreover, the necessity to provide such a link is not required in all discourse analytical strategies and depends largely on the level of detail of transcription that is used as the basis for analysis. [31]
An equally controversial notion is that discourse analysis represents an approach that as a matter of principle can or should not make use of basic tools for coding and annotating provided in a CAQDAS package. Personally I don't share this point of view. Following SILVERMAN (2010, pp.238ff.), I want to argue that coding on the contrary is a basic feature of discursive action used to make the world observable and reportable. Consequently, several authors with their methodological preference within discourse analysis have described coding as a fundamental element in their analytical approach. An illustrative account is given in HEPBURN and POTTER (2004) who describe in detail how they as an initial step in the analysis categorized 50 calls to a helpline for reporting concerns about child abuse. Furthermore they describe the crucial importance of annotating sequences of text, a function that is supported differently in the two CAQDAS packages I will review later. [32]
From a discourse analytical perspective, coding can be a task performed in an early stage before an in-depth analysis of data excerpts is carried out. In other discourse analytical strategies such as in WETHERELL and POTTER (1992) it can represent a permeating feature throughout the analytical process. [33]
As with other approaches to qualitative analytical work the question of whether or not the tools provided by a CAQDAS package can be used for discourse analytical purposes must be answered in terms of the needs of an individual working style rather than as a matter of principal methodological incompatibilities. Accordingly I will in the following comparison address how the basic functions of organizing, coding, annotating and searching data fit my own needs and how they support my understanding of qualitative syllogism logic. [34]
The premises for my following review of NVivo and MAXQDA are different since QSR software was a tool I knew well both as a user and teacher from the early versions of NUDIST to the later versions of NVivo.5) NVivo, especially in its later versions, was perceived as an increasingly less suitable tool for my analytical needs. As a possible alternative to NVivo, I utilized MAXQDA. Therefore the following review reflects my experiences as an experienced user of NVivo and as a novice user of MAXQDA Switching to another CAQDAS package for my own research purposes was a reluctant decision since it required considerable resources for re-training. Since I will include the reasons for changing from one program to the other, my review could be read as an overly critical view of NVivo. In addition, one should keep in mind that my comments are based on a particular methodological perspective and my own analytical needs. The reader should decide if my reasoning fits his or her own methodological and analytical needs. [35]
The performance of any computer program depends largely on the hardware used. To allow for comparisons, the laptop used for this review was equipped with an Intel dual core T7300 2 GHz processor with 2 GB RAM running Windows XP professional. This is well within the requirements specified by the software vendors.6) [36]
Both CAQDAS packages were evaluated using the same data from a research project about attitudes to interdisciplinary teamwork among practitioners from different health professions at a Norwegian rehabilitation clinic. Transcripts from 15 semi-structured interviews, a number of PDF files from government white papers, guidelines and background documents, and some pictures were imported into the project file. All files were tagged with codes and annotated with memos. The total size of these files was limited (altogether 22 MB) and the demands on the software for handling these data were rather modest. As should be expected from modern CAQDAS packages no instability problems with a project of such moderate size were encountered. [37]
My experience with QSR software dates back to 1997. Since the very early versions of NUDIST to the current version of NVivo, the frequent releases of new versions have been accompanied by some annoying stability problems. It sometimes seemed that new versions were launched as soon as the bugs in the old versions were finally fixed. Another annoyance with earlier versions of NVivo was the time required for installing, for performing analytical steps or simply for starting up. For example, in NVivo 8 it took the program 1 minute 12 seconds from double clicking the icon on the desktop to when the program gave the option to create a new project or to choose an existing one. The same operation in MAXQDA 10 took 15 seconds. This was also reflected when performing other basic operations like importing files, searching project items or saving the project before shutting down, NVivo needed considerably more time than MAXQDA. [38]
Both NVivo and MAXQDA run under Microsoft operating systems. When opened, the layout of both programs will seem familiar to most users of other MS Windows based programs. In both programs, the main menu and toolbars are located in the top window and functions for performing analytical tasks are accessed either through the main menu or shortcut icons on toolbars. The following two pictures show the workspace in respectively NVivo and MAXQDA.
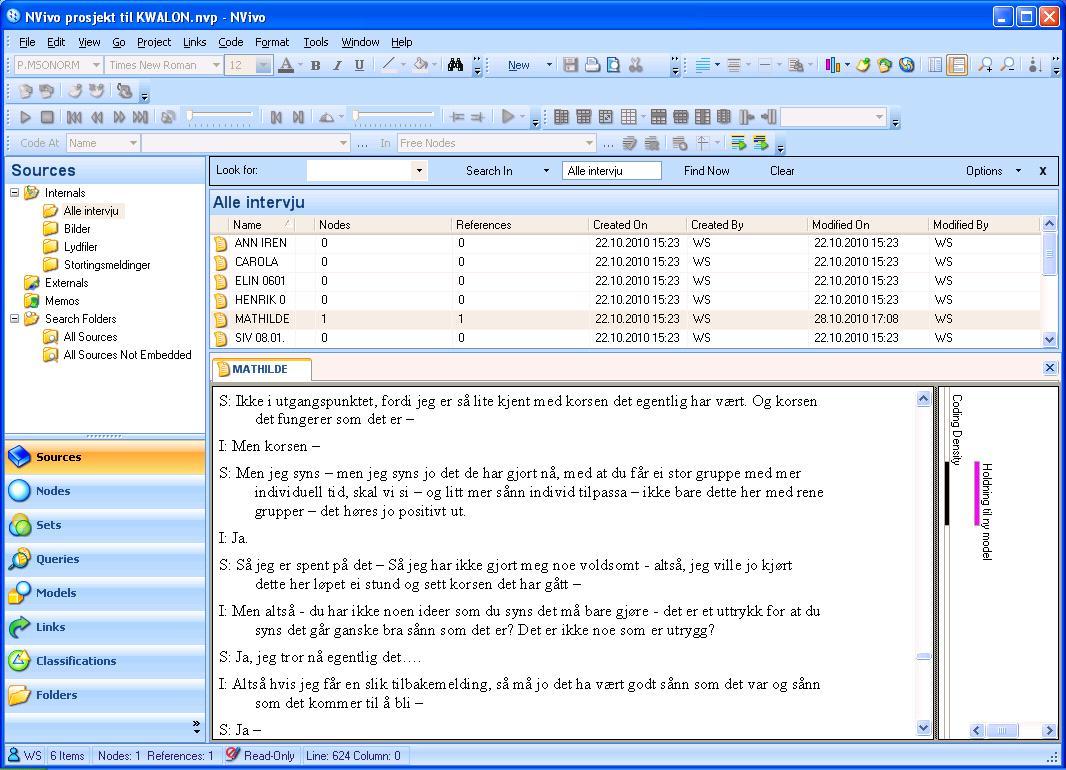
Illustration 1: Workspace in NVivo 8 (enlarge this figure here)
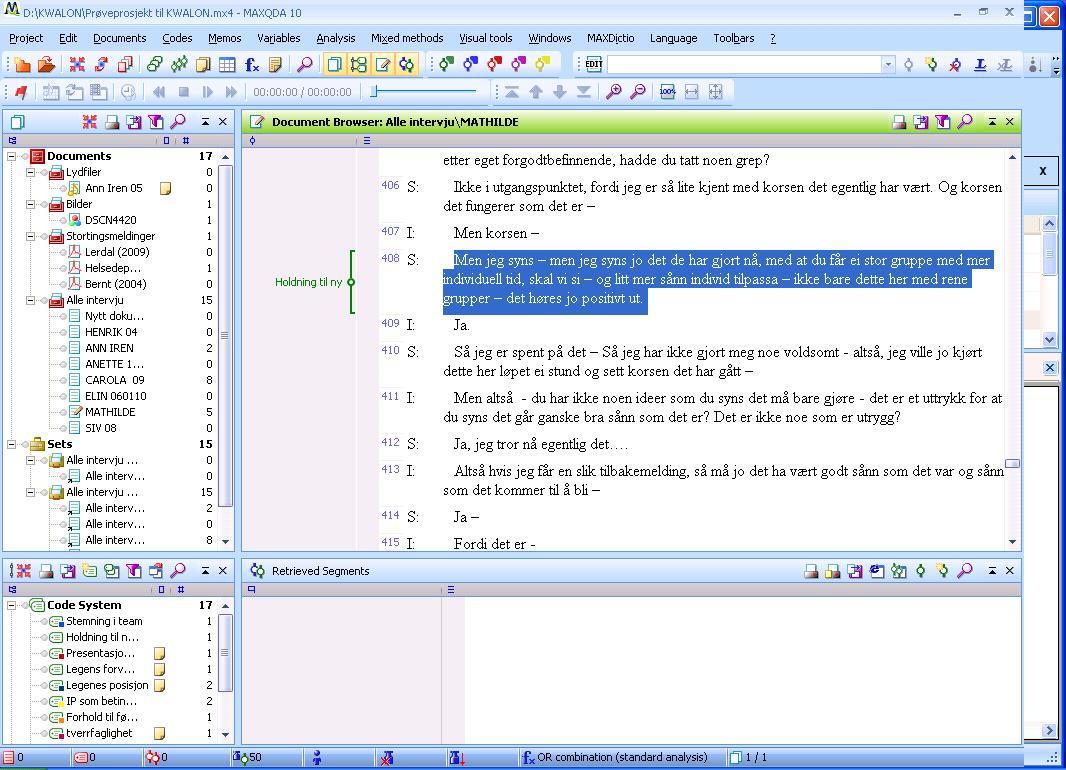
Illustration 2: Workspace in MAXQDA 10 (enlarge this figure here) [39]
Both NVivo and MAXQDA divide the main workspace into four windows, but with different emphasis on access given to the folder systems of documents, codes, search results and more. [40]
In NVivo this is uniformly done through the bottom left window where the user chooses what is to be displayed in the upper left window. The contents of each folder chosen here are displayed in the upper right window. In the picture above there is the option "Sources" chosen. All sources are therefore displayed in a folder system in the upper left window and the content of the folder (in the picture labeled as "Alle intervju" [all interviews]) is listed in the upper right window. The interview "Ann Iren"7) itself is opened in the lower right pane. [41]
The menu buttons in NVivo require some getting used to since the program from Version 7 onwards operates with sometimes different labels for established terms. "Codes" are for instance labeled as "nodes," "searches" as "queries" and more. For novice users this somehow idiosyncratic language requires some effort to get used to. The reason for deviating from established terms is not convincingly explained. However, in one respect I will follow the terminology of NVivo. Instead of "documents" I will use the term "sources" in my text because both NVivo and MAXQDA not only allow the handling of documents, but to a certain extent also multimedia files. [42]
In MAXQDA the two windows on the left are dedicated to listing the coding system in the lower and the sources included in a project file in the upper left. As already mentioned, MAXQDA allows importing text files and pictures. Somewhat confusingly, all sources are labeled as "documents." As in NVivo, double clicking a source opens it in the document browser in the upper right window pane. A fourth window, "Retrieved segments" is reserved to display results of searches. [43]
Personally I appreciate that the menu-buttons in MAXQDA are labeled mostly with established terms. Users familiar with the general logic of such programs will have few problems in recognizing the basic functions. A confusing exception in this respect is the "Analysis" button, which contains search and retrieve functions. The scope of analysis in qualitative analytical work by far exceeds the scope of various search options. At the very least, functions such as coding and memo-writing, which are placed in their own menu-buttons, should be regarded as analytical steps as well. [44]
I have already pointed out that qualitative research is a quite heterogeneous field of inquiry regarding both the methodology applied and the personal style of working. To accommodate different analytical needs a well designed CAQDAS package should provide the possibility for the user to adjust the workspace according to personal preferences. Both NVivo and MAXQDA allow users to show, hide and move toolbars on the screen. This is also possible with windows like the model functions, or the MAXQDA memo manager (a function not provided in NVivo).8) NVivo on the other hand gives the option to undock the contents of the source browser. This allows for instant comparisons by displaying several sources simultaneously. In MAXQDA this option is not possible since none of the main windows of the workspace can be undocked. With researchers increasingly enjoying the luxuries of an extended desktop by using multiple screens for their work, the possibilities for adjusting the workspace to the researchers' personal preferences are more limited in MAXQDA than in NVivo. [45]
According to the list of basic features I expect a CAQDAS to perform flawlessly I have mentioned the management of data, coding, annotating and searching them. These basic features at the very least should be introduced to the user in an intuitive way. They should be easily accessible without interrupting the work flow by unnecessarily forcing the user to spend much time on consulting handbooks or online help. [46]
5.4 Handling and organizing data
Most operations in NVivo and MAXQDA can be performed via the main menu, but basic tasks like importing, opening, copying, organizing data in folders and subfolders are most comfortably done by the mouse. For users of NVivo and MAXQDA the days are gone when documents first had to be converted to RTF or TXT format that are readable by all word processors. Text9) and PDF documents along with pictures10) can now simply be dragged and dropped into a project file with the mouse. [47]
It is equally convenient to organize and reorganize items by dragging them into folders and subfolders in the "sources" and "document" window. For further analytical purposes it is often meaningful to generate temporary sets of sources, for instance when reviewing all interviews conducted with a particular respondent or all members of an organizational unit. In MAXQDA sets are stored in the document window, whereas in NVivo they are placed under their own menu button. Apart from the different locations in the program workspace, in both programs sets contain shortcuts and not the actual documents. Deleting a document from a set has no further impact on the project file which makes it easy to use them actively and temporarily for conducting specific analytical steps. They can also be deleted when the operation is done to avoid drowning in a multitude of search results and the like. [48]
A nice feature in MAXQDA is that any part of the project can be readily exported to file formats that are readable by other programs. Code system, coded parts of texts (including coding stripes), memos, or tables like the memo manager, list of attributes and so on can easily be included in presentations or shared with co-workers who do not have access to a full version of MAXQDA. In NVivo much of the same is possible, but can sometimes require tedious detours and with not always satisfying results. If for example a document is to be printed with coding stripes, the latter appear on a separate sheet instead of (as in MAXQDA) together with the document. A hard copy is often used to get a better overview than is possible on the limited size of a computer screen. To have text and coding stripes printed on separate sheets is not only a waste of time and paper, but defies somehow the purpose of a hard copy. Moreover, it is annoying when a printout first has to be restacked before it can be passed on for comments by a supervisor, colleagues, or co-workers. [49]
In cases where not every participant of a research team has a full version of MAXQDA, VERBI software provides a free version under the name MAXQDA Reader. This freely downloadable program allows other users to review and display a project file created with a full version, but not to edit it. [50]
Audio and video analysis is a relatively new achievement in the current generation of CAQDAS packages. Documents and pictures can be imported into a project file. Audio and video files must be handled differently. Both programs provide the possibility to create transcripts (including time stamps) from externally stored audio and video files. These transcripts can then be coded and annotated within a project file, while maintaining the link to the audio and video files. Software vendors are not exactly known for being shy of stretching the limits of what can be done with their products. In terms of audio and video analysis the developers of MAXQDA showed a refreshingly pragmatic attitude to the limitations of their product in a recent contribution to the discussion forum of the CAQDAS project: "MAXQDA10 will be […] dealing with audio- und video files […] Although—if you really want to do video analysis, I would recommend to look at a professional tool for video analysis like Transana."11) It inspires respect when a software vendor acknowledges the limits of its own product and at the same time gives credit to a competitor. [51]
The means to transcribe audio and video files are provided in both NVivo and MAXQDA, but beyond that the analytical possibilities for multimedia files are quite limited. NVivo allows the importing of sound and small video files of up to 30 MB into a project file. For working with good quality video this is nowhere near any practical length of film. MAXQDA does not allow importing audio and video files. In both programs these files are better stored externally with links to a transcript inside the project file. [52]
Documents can either be imported or they can be created within the project file. The options for editing text in MAXQDA are limited to changing fonts, size, color and appearance and paragraph adjustment. The possibilities provided in NVivo exceed this considerably. Among other options, NVivo allows users to insert bulleted and numbered lists, tables and to change paragraph indentation. [53]
Besides documents with filename extensions TXT, RTF, DOC and DOCX, both CAQDAS packages also allow importing PDF documents. Researchers who in their work intend to do a content analysis of PDF documents should look closely at what each program can deliver, since the possibility for importing a document without a loss of information will be an important quality. In this respect there are significant differences between NVivo and MAXQDA. Firstly, NVivo needs considerably more time for importing PDF documents than MAXQDA. Second, the size limit of PDF documents that can be imported into an NVivo project file is rather limited. A file size of 2.15 MB (corresponding to 170 pages) appeared to be more than the program could handle, while the same file was imported fast and without problems into MAXQDA. Third, the loss of information by importing PDF documents varies considerably. The following illustrations show how the same PDF file appeared after being imported into each program.
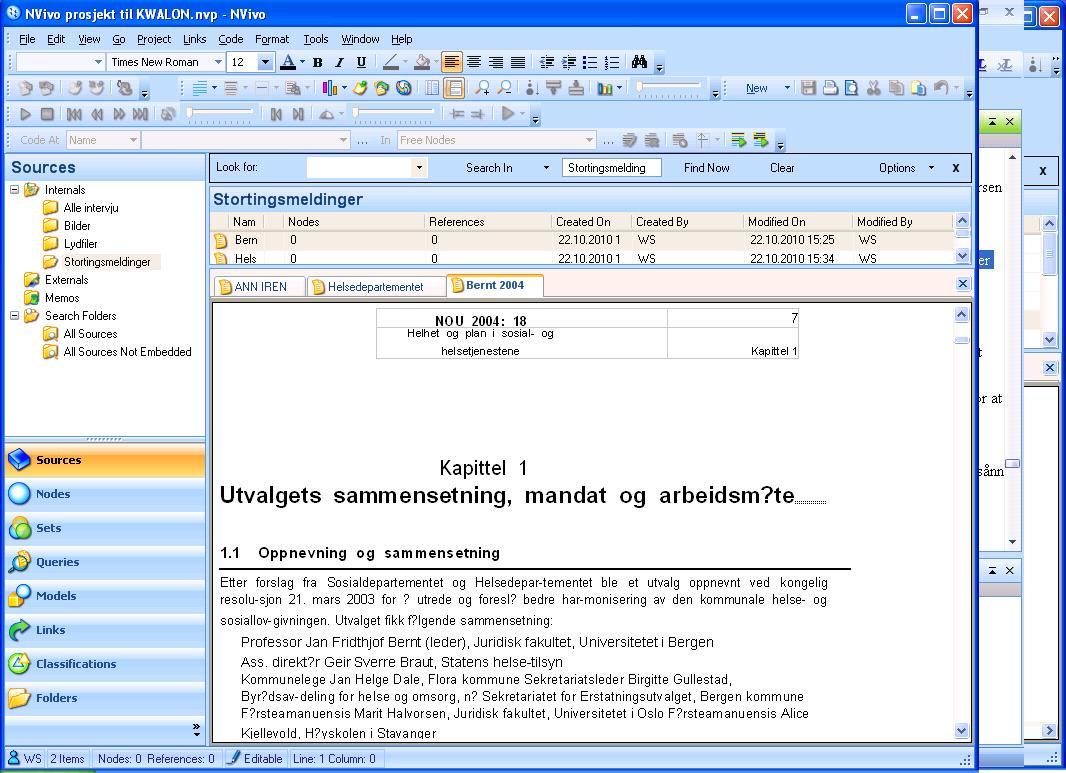
Illustration 3: PDF file imported in NVivo 8 (enlarge this figure here)
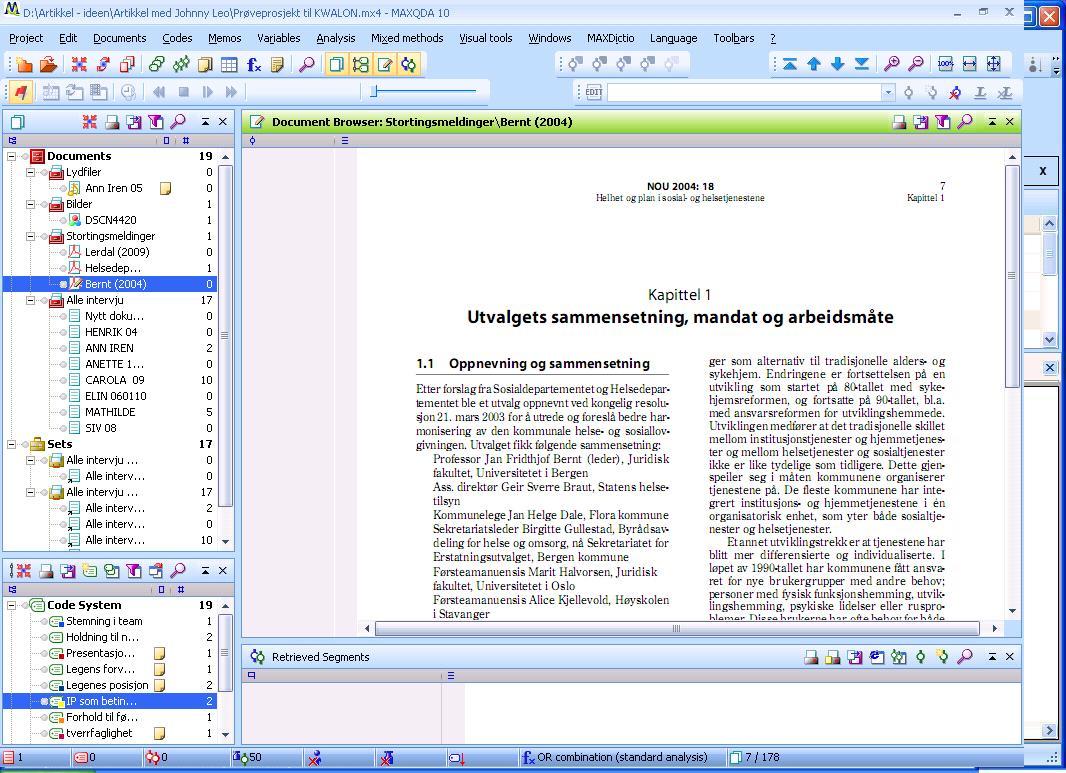
Illustration 4: PDF file imported in MAXQDA 10 (enlarge this figure here) [54]
It is obvious that importing the PDF document into NVivo has caused the loss of much information: For example, in the Norwegian text displayed in illustrations 3 and 4, mutated vowels have been replaced by question marks; columns have disappeared along with page numbers and so forth. In MAXQDA, PDF documents are displayed just as "the real thing"; that is including all linguistic features, pictures, tables, columns and so on. PDF documents can immediately be coded, searched and managed just as other items integrated in the project file. [55]
Nevertheless, even if PDF documents are kept in their original layout they must be handled differently from other documents. This is not so much caused by the way MAXQDA handles this type of file, but by the nature of PDF documents. MAXQDA documents are structured in paragraphs and displayed with paragraph numbers. The same is true for NVivo, even if paragraph numbers are not displayed in the text (there is, however, an option to include these in a printout of the document). In PDF documents imported into MAXQDA each page represents a separate unit and must therefore be handled as a single paragraph. Consequently, PDF documents must be navigated differently from other documents. Instead of using the side scrollbar, first a document bar must be activated from the toolbars drop-down menu in order to be able to move from page to page. Another particularity of dealing with PDF documents in MAXQDA is that they have to be coded differently. While the segments of text documents can comprise any part of the source document, PDF documents can only be coded within the text page currently displayed in the document browser. That means it is not possible to code segments across a page break. [56]
For researchers who often work with PDF documents, MAXQDA's quite impressive solution for handling such files exceeds considerably what is offered by NVivo. The ability to import PDF documents without the loss of linguistic features like mutated vowels will be especially appreciated from researchers working in other languages than English. [57]
Sooner or later every first-time user of a computer program will encounter obstacles and much depends on the support the software vendor offers to avoid unnecessary frustrations. For these instances, both programs provide a help menu button with access to support on different levels. Firstly, both give access to online help including tutorials, a list of FAQ and an open discussion forum hosted by the software vendors. Both forums gave excellent support. Questions posted there on several occasions all received exhaustive answers within 24 hours, and sometimes within the hour. Secondly, each program is supplied with integrated help functions that can be accessed independently from Internet access. Here the support that is provided for users of NVivo clearly exceeds what is offered in MAXQDA. NVivo gives help to program functions through an index of keywords and a glossary of terms. There is no printable version of the whole content, but the individual topics can be printed out. Compared to NVivo, the integrated help functions in MAXQDA leave much to be desired. The "MAXQDA manual" is accessible from the help-icon on the toolbar and links to a PDF file with the manual for the 2007 edition of the program (with quite a different program layout and a partly different use of terminology). The help menu further contains a link to a file entitled "New functions in MAXQDA 10" which is obviously meant to be used in conjunction with the 2007 manual. Both new and experienced users would benefit significantly from an updated and integrated manual, which should also include a searchable index of key words and functions. The absence of such a manual is especially hard to understand since the makers of MAXQDA actually provide an illustrative and easy-to-understand online-tutorial for their new version. This tutorial is only of limited help since it neither contains a keyword index nor can it be downloaded and searched. While learning MAXQDA this resulted in a frustrating disruption in the work flow because it made rather time-consuming repeated reading of lengthy sections necessary. [58]
5.5 Coding and retrieving data
Coding, the possibility to break up a source into sequences and to tag them with analytical categories, has been described as the dominant paradigm in qualitative research (FIELDING & WARNES, 2009, p.278). The common theme and variations in the process of coding and sub-coding in different methodological frameworks have been discussed in detail in SALDAÑA (2009). With coding at the heart of most CAQDAS packages, the developers of NVivo and MAXQDA have put significant effort into providing comfortable solutions for executing this core function. Both programs offer several options and each user will have to determine which one best suits their individual style of working. [59]
Codes in MAXQDA are displayed uniformly in the "code system" window. NVivo follows a more stringent grounded theory based approach with a distinction between initial coding (e.g. used to code data word for word, line-by-line or from incident to incident) and focused coding of the themes identified in the first process (see for instance CHARMAZ, 2006, pp.48ff.). NVivo supports this by displaying codes (in the program's own terminology: nodes) in separate windows for "free nodes" and "tree nodes." For other methodological approaches (including my own), the development of a structured conceptual framework of categories is a permeating process from the very start of the analysis. Instead of a sequential order of initial and focused coding, an emerging coding tree structure will be used from the start to keep an overview of the codes already created, of missing categories and codes that are thematically related. [60]
Coding sequences of text or other sources is in both programs done in a similar way. Codes can be assigned by dragging a marked passage onto the appropriate code in respectively the "code system" or "nodes" window or by right clicking on the marked text. The latter gives the option for choosing between an existing code or creating a new one. Coded passages in a document can be displayed in the document browser with colored and interactive coding stripes that make it easier to keep an overview of the work done. In NVivo coding stripes can be chosen as an optional feature with an automatically assigned color. In MAXQDA they are automatically displayed in the document browser and colors can be assigned from a wide color spectrum. [61]
Opened documents can in NVivo be searched for specific words or phrases. MAXQDA provides a function for searching each of the four main windows in the workspace. In NVivo, all text sequences coded with a particular code can be retrieved immediately simply by double-clicking on the code in the "nodes"-window. Other search functions are gathered in a menu for "queries." This contains options for simple text searches, word frequency counts, retrieving coded sequences, an intercoder comparison and so forth. In MAXQDA similar options are provided in the "analysis" menu button in the main menu. MAXQDA provides also a simple and efficient option for reviewing coded passages by activating selected documents and codes in the "document" and "code system" windows. The results are displayed in the default "retrieved segments" window and can be stored, displayed or exported immediately. [62]
Apart from the options for immediate searches, the sophisticated features for retrieval require some getting used to in both programs. Once acquainted with them, they appear in both cases to be powerful tools for retrieving and comparing items included in a project file and the analytical work done with them. [63]
Since my very first encounter with a CAQDAS package one of the most attractive features for my own analytical work has been the possibility to annotate documents with analytical thoughts and ideas. My personal reasons for looking for an alternative to NVivo were, among others, motivated by a limitation in the program structure for annotating data. [64]
In most qualitative work, coding is used to categorize sequences of data according to conceptual ideas about the thematically "what." In my own discourse analytical work, coding has a dual purpose. It is used to categorize data according to the thematically "what," but also to mark sequences of text according to the operational "how" of discursive practice (HOLSTEIN & GUBRIUM, 1997). Annotating text with memos has a similar dual function. Annotations are used for capturing interpretative thoughts about theoretical concepts that will be used to describe the topic of the research project. They are also used for analyzing the discursive tools used in a source. For the latter, memos often include longer sequences of raw text that is analyzed for example according to the rhetorical tools used by respondents and interviewer or the subject positions described. This fine-grained analysis of the operational "how" often leads to refining the coding system of the conceptual "what." [65]
For annotating thoughts about the thematically "what" and the operational "how," memos start rather unspecific and impressionistic much like uncommitted "post-it notes." As the analysis progresses, they may turn into more worked out parts of the text that is eventually presented to the reader. Therefore, memos have an important function in the analytical process that far exceeds being just notes to data. As noted by SALDANA "memos are data; and as such they, too, can be coded, categorized, and searched" (2009, p.33). To serve my analytical needs the memo function in a CAQDAS package must allow users to annotate sources and parts of sources with an unlimited number of memos. It must also support easy organizing and let the memos be coded, searched, and linked to other project items. [66]
NVivo and MAXQDA both offer substantial support for annotating and for linking project items, but both also have their limitations. [67]
5.6.1 Annotating in NVivo
Since Version 7, NVivo has provided different options for creating links between project items. All options can be accessed either through a dedicated "links" button in the main menu, or while working in an open document, by right clicking. Of these options, memo links create a link between a memo and either a source document (or parts of it), a code or another kind of file. These memos are documents like other source documents and, like them, can be coded, searched and processed further. They can also be created as free memos independently from a source document. Besides memos, NVivo provides an option for linking annotations to a source. Unlike memos, annotations do not link to a separate file, but remain embedded in the source—much like comments in a MS Word document. The content of annotations can be included in searches, but they cannot be coded. In addition, NVivo allows the creation of a network between project items by so called see also links. For instance, these can link a sequence in a source document to another document, a code, model and so forth. Finally it is also possible to insert hyperlinks to external sources. [68]
For my analytical purposes as described before, the logical choice would be to use annotations for capturing first volatile impressions. Since only memos can be coded, these would be used for annotating any analytical thoughts that, at a later stage of analysis, might be made subject to categorize excerpts from the raw data material included in the memo and the interpretation of them. Up to NVivo Version 2, the software allowed exactly that: the user could attach an unlimited number of fully codeable memos to a text. The later versions of NVivo 7 and 8, however, only allow the user to attach one memo to any given source. [69]
In spite of considerable efforts it was not possible to find out the reasons for this limitation. A personal inquiry to the QSR support desk yielded a rather laconic answer: "You can only link one memo to a source file; this is how it was designed. To work around this limitation you can use the 'See also link' which acts the same as memos." [70]
"See also links" can be used to create a link between a sequence in a document and another project item. In order to be able to link several memos to a document the user will first have to create free memos and then add see also links from text sequences to these free memos. Since a "see also link" works one way only, it is not possible to toggle between memo and source document. As a substitute for the old memo function provided in NVivo 2 this leaves much to be desired. The reason for separating memo links from annotations in the newer versions of NVivo may be to support the analytical needs of a particular methodological framework. For other methodological approaches to analysis, including mine, this is hardly a practical solution for annotating data. [71]
5.6.2 Annotating in MAXQDA
Memos in MAXQDA are certainly one of the program's distinguishing features. By placing a dedicated "memo" button in the main menu, the user is encouraged to use this function actively. Any number of memos can be attached to any document in the project. The size limit of 32 pages for each memo will be enough for most practical purposes.12) [72]
Memos can be reviewed in the memo manager where they are displayed in a table with information about the source they are attached to, title, date of creation and more. A nice feature is the option to tag each memo with symbols such as question or exclamation marks, color codes and more. These tags allow memos to be grouped together; for example those containing open questions, analytical thoughts, conclusions and so on. Examples of these tags can be seen in the first column on the left in the following screen shot:
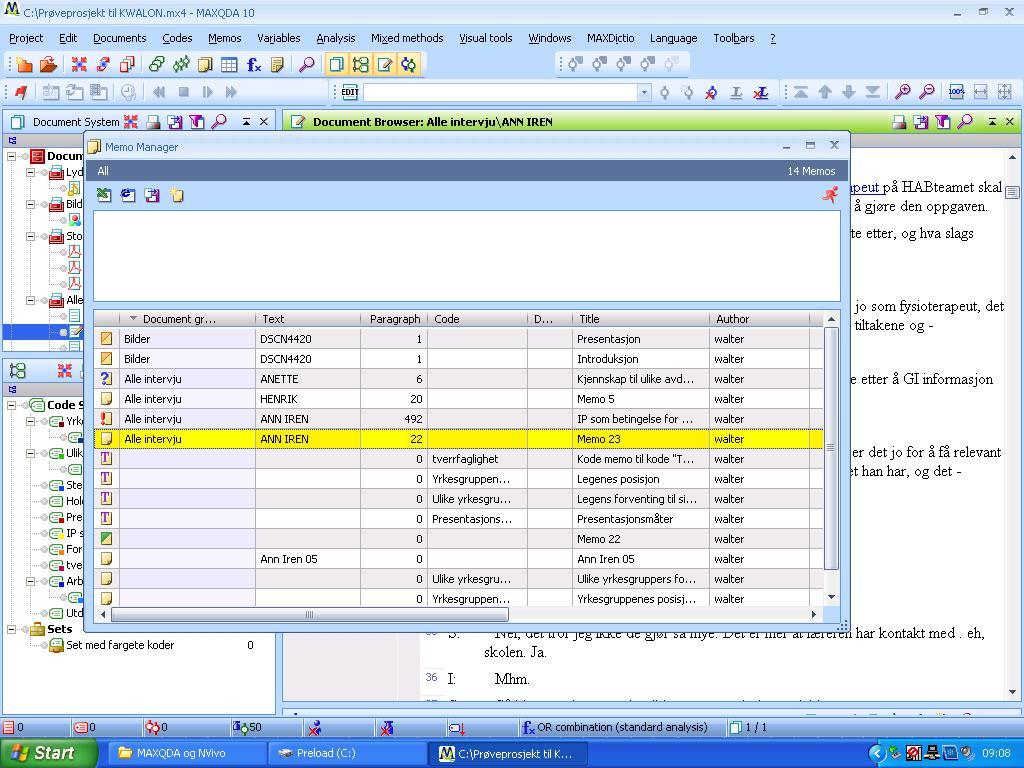
Illustration 5: Memo manager in MAXQDA 1013) (enlarge this figure here) [73]
The memo manager makes it quite easy to structure and keep an overview of a frequently growing multitude of memos. However, the memo function in MAXQDA has some particularities that limit its use for my analytical purposes. Firstly, memos as such cannot be coded. To code or process a memo further it has to be first converted into a document. By converting it, the link between the former memo and its source of origin is removed. It can, however, be reestablished by inserting a text link between the former memo and the original document. Unlike "see also links" in NVivo, text links in MAXQDA can only be established between sequences of text in the same or different documents. They cannot be used to link document files with each other. Text links work both ways and allow users to toggle back and forth between linked text sequences. Similar to the memo manager, MAXQDA has the option to display all text links for selected or all sources in a table. Secondly, the memo function in MAXQDA can be perceived as somehow problematic when a source document is deleted since the attached memos are deleted together with their source of origin. To preserve the memos these must either be copied into another document or the text must be copied into a free memo. In case of the latter, copy and paste is not supported by the mouse, but must be done using the shortcuts ctrl + c and ctrl + v. Personally I find working with keyboard shortcuts somehow cumbersome and outdated compared to navigating with a mouse. It is definitely desirable to provide the user with a choice of which way to perform these tasks and this will hopefully be included in an update of the program. [74]
The memo function in MAXQDA is clearly one of the program's distinguishing features that, exceeds the possibilities provided by NVivo but it is also necessary to invest some time in order to become acquainted with it. Arguably, coding memos could be more straightforward, even if text links in MAXQDA work better for my purposes than "see also links" in NVivo. [75]
In addition to text links, MAXQDA, just as NVivo, allows embedding hyperlinks to external sources. As an additional feature it is also possible in MAXQDA to insert geo links via Google Earth. [76]
5.7 Quantifying features in NVivo and MAXQDA
After reviewing the basic analytical functions of NVivo and MAXQDA, how do they live up to the second benchmark for assessing a CAQDAS: the features for quantifying qualitative data that may come into conflict with qualitative syllogism logic? [77]
5.7.1 Quantifying qualitative data in NVivo
I have already mentioned the "queries" tool in NVivo. It gives access to search for text strings, word frequency counts or coding work done in selected sources. The results are displayed in table form and can be stored, printed or exported. For those whose methodological framework allows them to make use of this information, the "queries" tool provides a variety of options. [78]
In addition, NVivo contains a separate module for creating charts to illustrate graphically and numerically the analytical steps conducted in qualitative data.
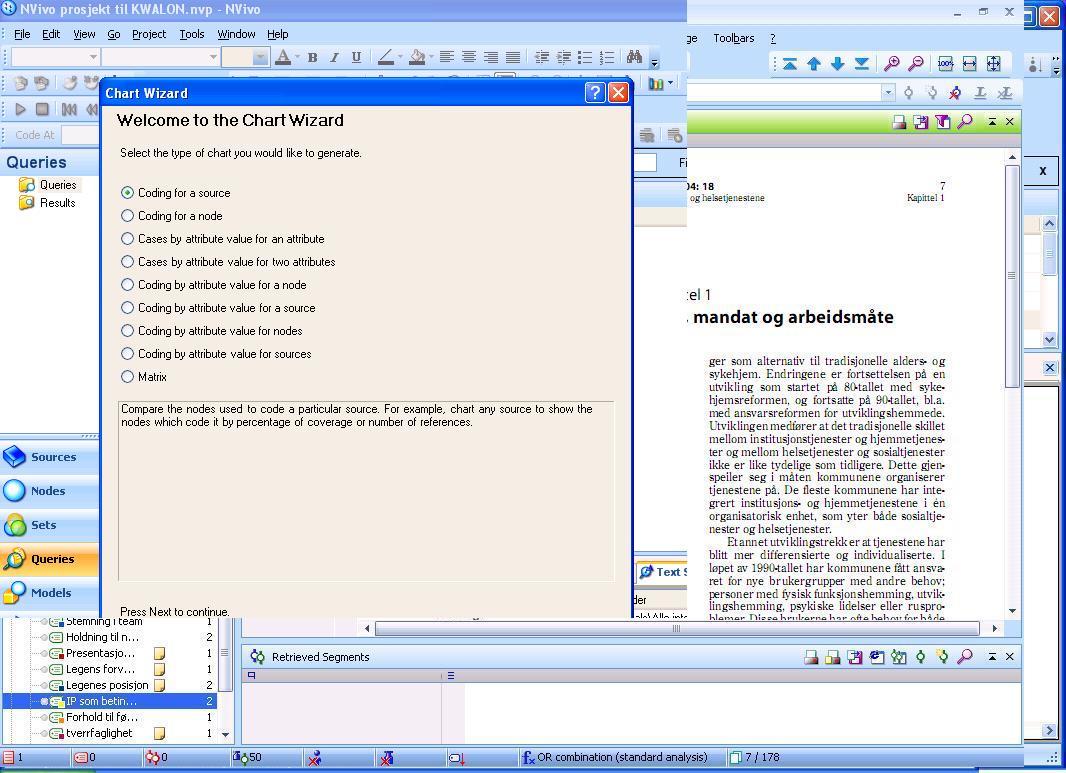
Illustration 6: Chart module in NVivo 8 (enlarge this figure here) [79]
I have in my argument for a qualitative syllogism logic pointed out that tools for creating tables and charts can make for a certain temptation to condense analytical steps in a way that is definitely not covered by all qualitative methodologies. Ultimately, the responsibility for using them or not must be placed with the user and not the program. In other ways, NVivo does not offer a choice of whether or not quantified information is included in the display of qualitative data. For instance, a query performed to display all sequences coded with a particular code results in a report including information about a "%-coverage"; meaning the volume of data that in each source is categorized by that particular code. This information does not only take up valuable space and makes the report harder to read, but also has a rather questionable analytical value for purposes like my own. Previously I have described how coding in my own analytical work is used for an initial categorization of topics in relation to a research question. Examples from often quite lengthy coded sequences are then annotated with a detailed analysis of the discursive work displayed in the coded parts. This myopical work often leads to the construction of modified or more specific sub-codes. In such a cyclic approach to analysis, the volume of data coded with a certain code can hardly be taken as an indicator for its relevance. [80]
The same applies to information about the frequency of occurrence of codes, which in NVivo is displayed as a compulsory part of the coding system. This frequency has for my analytical purposes no bearing at all as an indicator for the importance of this particular code. On the contrary, initial codes are usually broad categories that tag large portions of text. They need to be broken down into fine-grained, more meaning-bearing sub-codes or categories as the analysis proceeds. In social constructivist methodologies, not only in a discourse analytical approach, the frequency of occurrence or the "%-coverage" are rather meaningless and distracting pieces of information. NVivo, however, imposes this regardless of individual analytical preferences and the methodological framework employed. This leaves the user powerless to suppress quantified information. [81]
5.7.2 Quantifying qualitative data in MAXQDA
Just like NVivo, MAXQDA is presented to the qualitative research community as a tool usable within different methodological frameworks. Specifically it is advertised as a tool for mixed methods approaches. The main menu in MAXQDA includes a dedicated "mixed methods" button where several options for a quantified, condensed display of analytical steps can be chosen from the drop-down menu. Also included is an option for cross tabulating coded text sequences. The latter is not only a handy tool for mixed method research, but for strictly qualitative analysis as well, for example to compare accounts about the same situation given by different respondents. [82]
Additional functions for quantifications are located in the add-on module MAXDictio. If purchased, this is accessed through a button in the main menu and provides the necessary tools for quantitative content analysis; including creating a dictionary of terms, displaying word-frequencies and coding of search terms. [83]
Unlike NVivo, MAXQDA does not include an option for creating charts. In fact, not only for purely methodological reasons there is hardly any justification for including a chart option. MAXQDA is a MS Windows based program and most users will have access to spreadsheet programs like MS EXCEL, which include a sophisticated chart module. What's more, MAXQDA 10 allows the export of most parts of the project to statistic and spreadsheet programs where those inclined to do so can display condensed information from their qualitative analysis in a wide variety of charts and graphs. Personally I appreciate the absence of a separate chart module in MAXQDA for two reasons. First, because it encourages the user to a certain extent to ground conclusions within the limits of qualitative syllogism logic. Second, because fewer menu buttons make it easier for new users to get acquainted with the basic functions for qualitative data analysis which in MAXQDA are easily accessible and intuitively arranged. With its integrated options for exporting into other programs the absence of a dedicated module for creating charts means that less is more in this respect. [84]
MAXQDA does not include information about a "%-coverage" of a given code in a source. On the other hand, MAXQDA allows assigning a measurement of relevance to a code. This "weight factor" does not appear on screen, but is a compulsory part of all print-outs and exported reports. As in NVivo, reports of coded passages across documents appear somehow inflated by including a feature with doubtful analytical value. [85]
By default, MAXQDA includes information about a coding frequency in the "code system" window. This is, however, optional and can be deactivated along with other features to personalize the workspace. This gives the user a certain degree of control over adjusting and displaying project items and analytical results on screen and in reports with or without quantified information. [86]
As with all major CAQDAS packages today, NVivo and MAXQDA provide features far beyond the scope of this review. The programs accommodate a wide variety of tools to serve different methodological and analytical needs, not all necessarily compatible with each other. For users looking for information about functions serving particular research needs, the presented review will yield little new. I have focused my discussion on two aspects. First on the possibilities in NVivo and MAXQDA for adjusting the program workspace according to individual preferences and the solutions for performing basic analytical tasks used within most approaches to qualitative inquiry. Second the features in the two programs designed to quantify qualitative data and my perception of how intruding this quantified information is imposed on every user regardless of whether or not their own methodological framework allows them to make use of it. [87]
In terms of the first, both programs provide comfortable solutions for performing analytical tasks like coding, retrieving and annotating qualitative data. Coding is in both CAQDAS packages easy and intuitive to handle. Both programs offer various options for searching and retrieving, but are in both cases quite sophisticated and complex, and need some getting used to. Once acquainted with them most users will find a suitable solution for most tasks from a simple retrieval of words and phrases to a structured content analysis. Regarding the possibilities for annotating data NVivo was perceived as more restrictive than MAXQDA. The latter makes it easier to organize and keep an overview over memos and their contents. It also has more practical solutions for linking text sequences with each other. [88]
In terms of the second, both programs impose some quantified information on every user. For a wide range of qualitative methodologies, including discourse analytical, phenomenological, hermeneutical and ethnographical approaches, this kind of quantified information of qualitative data has very limited analytical value. It would be desirable for CAQDAS packages to include more options for adjusting the workspace according to individual preferences, but even more to give the user a choice between displaying quantified information of qualitative data or not. In this respect NVivo restricts the user more than MAXQDA, but both programs have considerable need for improvement. [89]
Different methodological needs result in various potential markets for vendors of CAQDAS packages. They will of course attempt to attract as many new customers as possible. However, the existence of features in a CAQDAS package does not mean that these should nor will be used in all kinds of qualitative analytical work. It appears that new features in both NVivo and MAXQDA are focused mainly on combining qualitative and quantitative research and on possibilities to quantify qualitative data. Much less emphasis is given to improving the possibilities for adjusting program workspace and for displaying analytical results according to individual preferences. [90]
Most social constructivist approaches to social inquiry aim at analytical generalizations by combining ideal typical categorizations of empirical findings with a theoretical framework. My argument is that the possibilities and limits for drawing conclusions from qualitative data analysis in a variety of methodologies are based on qualitative syllogism logic that is independent from quantifications. It is to be hoped that the further development of CAQDAS packages like NVivo and MAXQDA leads to more options for adjusting the program workspace and for displaying analytical results according to individual preferences and different analytical needs. [91]
I want to thank Dr. Johnny Leo JERNSLETTEN at the Centre for Sami Studies, University of Tromsø for his comments on an earlier draft of this paper. I also want to express my gratitude to the staff at QSR-Software and VERBI-Software for their kind permission to use screenshots from their homepages. Not the least I want to thank Dr. Katja MRUCK and my anonymous two reviewers for thorough reading and constructive comments.
1) See http://www.qsrinternational.com/FileResourceHandler.ashx/RelatedDocuments/DocumentFile/499/QSR_Company_Brochure.pdf [Accessed: July 8, 2010]. <back>
2) See http://www.maxqda.com/nine-great-reasons-to-use-maxqda [Accessed: July 8, 2010]. <back>
3) Since the new version 10 of MAXQDA had been released at the time of writing, this version was used for the review. NVivo has been reviewed in its Version 8, but has in November 2010 been superseded by a Version 9. All references to NVivo and MAXQDA refer therefore to respectively Version 8 and 10. <back>
4) See https://www.jiscmail.ac.uk/cgi-bin/webadmin?A2=QUAL-SOFTWARE;Ib02yw;20100321232319%2B0100 [Accessed: March 30, 2010]. The CAQDAS network is an independent network committed to promote the development of computer assisted qualitative data analysis. It is hosted by the University of Surrey, UK. <back>
5) QSR International is the company marketing NVivo and its predecessor NUDIST. <back>
6) See http://www.maxqda.com/products/system-requirements and http://www.qsrinternational.com/products_previous-products_nvivo8.aspx [Accessed: July 7, 2010]. <back>
7) Fictional name of interviewee. <back>
8) The model function is not discussed further in this review. It provides in both programs a tool for visualizing relations between elements included in a project file. The memo manager in MAXQDA is discussed in more detail in Section 5.3.2. <back>
9) With filename extensions TXT, RTF, DOC and DOCX. <back>
10) With filename extensions BMP, GIF, JPG, JPEG, TIF, TIFF. <back>
11) See https://www.jiscmail.ac.uk/cgi-bin/webadmin?A2=ind1002&L=QUAL-SOFTWARE&F=&S=&X=49A40F5E48622CF32A&Y=walters%40sv.uit.no&P=2995 [Accessed: July 7, 2010]. <back>
12) See http://www.maxqda.com/max10/index-inhalt.html [Accessed: June 23, 2010]. <back>
13) See http://www.maxqda.com/max10/index-inhalt.html [Accessed: May 23, 2010]. <back>
Alvesson, Mats & Kärreman, Dan (2000). Varieties of discourse: On the study of organizations through discourse analysis. Human Relations, 53(9), 1125-1149.
Burr, Vivian (2003). Social constructionism (2nd ed.). London: Routledge.
Carvajal, Diógenes (2002). The Artisan's tools. Critical issues when teaching and learning CAQDAS. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 14, http://nbn-resolving.de/urn:nbn:de:0114-fqs0202147 [Accessed: April 7, 2008].
Charmaz, Kathy (2006). Constructing grounded theory. A practical guide through qualitative analysis. London: Sage.
Clarke, Adele E. (2005). Situational analysis: Grounded theory after the postmodern turn. Thousand Oaks, CA.: Sage.
Creswell, John W. & Plano Clark, Vicki L. (2007). Designing and conducting mixed methods research. Thousand Oaks, CA: Sage.
Denscombe, Martyn (2007). The good research guide for small-scale social research projects (3rd ed.). Maidenhead: Open University Press.
Edley, Nigel (2001). Analysing masculinity: Interpretative repertoires, ideological dilemmas and subject positions. In Margaret Wetherell, Stefanie Taylor & Simeon Yates (Eds.), Discourse as data. A guide for analysis (pp.189-228). London: Sage.
Fairhurst, Gail T. & Putnam, Linda (2004). Organizations as discursive constructions. Communication Theory, 14(1), 5-26.
Fielding, Nigel & Warnes, Richard (2009). Computer-based qualitative methods in case study research. In David Byrne & Charles C. Ragin (Eds.), The Sage handbook of case-based methods (pp.270-288). Los Angeles: Sage.
Flyvbjerg, Bengt (2006). Five misunderstandings about case-study research. Qualitative Inquiry, 12(2), 219-245, Doi 10.1177/1077800405284363.
Gill, Rosalind (2000). Discourse analysis. In Martin Bauer & George Gaskell (Eds.), Qualitative researching with text, image and sound: A practical handbook (pp.172-190). London: Sage.
Hepburn, Alexa & Potter, Jonathan (2004). Discourse analytic practice. In Clive Seale, Giampietro Gobo, Jaber F. Gubrium & David Silverman (Eds.), Qualitative research practice (pp.180-196). London: Sage.
Holstein, James A. & Gubrium, Jaber F. (1997). Active Interviewing. In David Silverman (Ed.), Qualitative research. Theory, method and practice (pp.113-129). London: Sage.
Jackson, Kristi (2003). Blending technology and methodology: A shift toward creative instruction of qualitative methods with NVivo. Qualitative Research Journal, Special issue, 96-110.
Jørgensen, Marianne W. & Phillips, Louise (2002). Discourse analysis as theory and method. London: Sage.
Kelle, Udo (1997). Theory building in qualitative research and computer programs for the management of textual data. Sociological Research Online, 2(2), http://www.socresonline.org.uk//2/2/1.html [Accessed: August 18, 2004].
Kelle, Udo (2004). Computer-assisted qualitative data analysis. In Clive Seale, Giampietro Gobo, Jaber F. Gubrium & David Silverman (Eds.), Qualitative research practice (pp.473-489). London: Sage.
Kvale, Steinar (1996). Interviews: An introduction to qualitative research interviewing. Thousand Oaks, CA: Sage.
Lewins, Ann & Silver, Christina (2007). Using software in qualitative research: A step-by-step guide. Los Angeles: Sage.
MacMillan, Katie (2005). More than just coding? Evaluating CAQDAS in a discourse analysis of news texts. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(3), Art. 25, http://nbn-resolving.de/urn:nbn:de:0114-fqs0503257 [Accessed: December 18, 2005].
O'Rourke, Brendan K. & Pitt, Martyn (2007). Using the technology of the confessional as an analytical resource: Four analytical stances towards research interviews in discourse analysis. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 8(2), Art. 3, http://nbn-resolving.de/urn:nbn:de:0114-fqs070238 [Accessed: November 28, 2010].
Saldaña, Johnny (2009). The coding manual for qualitative researchers. Los Angeles: Sage.
Schönfelder, Walter (2008). The limits of analyzing rhetoric in the analysis of organizational discourse. In Lotte Dam, Lise-Lotte Holmgreen & Jeanne Strunck (Eds.), Rhetorical aspects of discourse in present-day society (pp.393-411). Cambridge: Cambridge Scholars Publishing.
Seale, Clive (2010). Using computers to analyse qualitative data. In David Silverman, Doing qualitative research: A practical handbook (pp.251-267). London: Sage.
Silverman, David (2010). Doing qualitative research: A practical handbook (3rd ed.). Los Angeles: Sage.
Strauss, Anselm L. & Corbin, Juliet M. (1998). Basics of qualitative research. Techniques and procedures for developing grounded theory (2nd ed.). Thousand Oaks, CA: Sage.
Teddlie, Charles & Tashakkori, Abbas (2009). Foundations of mixed methods research: Integrating quantitative and qualitative approaches in the social and behavioral sciences. Los Angeles: Sage.
Weber, Max (1972). Wirtschaft und Gesellschaft. Grundriss der verstehenden Soziologie (5th ed.). Tübingen: J.C.B. Mohr (Paul Siebeck).
Wetherell, Margaret (1998). Positioning and interpretative repertoires: Conversation analysis and post-structuralism in dialogue. Discourse & Society, 9(3), 387-412.
Wetherell, Margaret & Potter, Jonathan (1992). Mapping the language of racism: discourse and the legitimation of exploitation. New York: Harvester Wheatsheaf.
Walter SCHÖNFELDER is senior researcher at Valnesfjord Rehabilitationcentre, Norway. His research interests include medical sociology, mental health care, rehabilitation, interprofessional relationships, organizational theory, social work, community organization and restorative justice. Methodological preferences are within discourse analysis and mixed methods. He also teaches computer assisted qualitative data analysis for graduate and postgraduate students.
Contact:
Walter Schönfelder, PhD
Valnesfjord Rehabilitationcentre
Research Department
Østerkløft, 8215 Valnesfjord, Norway
Tel.: +47-75602503
Fax: +47-75602555
E-mail: walter.schonfelder@vhss.no
URL: http://vhss.no/?a_id=1127&ac_parent=117
Schönfelder, Walter (2011). CAQDAS and Qualitative Syllogism Logic—NVivo 8 and MAXQDA 10 Compared [91 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 21, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101218.
Revised: 2/2011

Creative Commons Attribution 4.0 International License