Volume 12, No. 1, Art. 32 – Januar 2011
Das Datenkonzept von ATLAS.ti und sein Gewinn für "Grounded-Theory"-Forschungsarbeiten
Agnes Mühlmeyer-Mentzel
Zusammenfassung: Computerprogramme zur Unterstützung der Analyse qualitativer Daten sind sich in ihrer Grundfunktionalität sehr ähnlich. Unterschiedlich ist allerdings, in welcher Form die Ergebnisse der Analysetätigkeit gespeichert werden. Dieser Beitrag thematisiert die Passung zwischen der Grounded-Theory-Methodology (GTM) und einer netzwerkartigen Speicherung der Ergebnisse, wie sie in ATLAS.ti realisiert wird. Am Material eines Forschungsprojektes wird gezeigt, wie die unterschiedlichen Kodiertypen der GTM in ATLAS.ti ausgeführt und die Ergebnisse als ein Netz von Kodes abgespeichert werden. Herausgestellt wird, dass das Kode-Netz die entwickelte "Grounded Theory" als strukturierte, auf den Begriff gebrachte Information repräsentiert und in maschinenlesbarer Form anderen Forschenden zur Verfügung gestellt werden kann. Dieses Potenzial erweitert die Möglichkeiten der Qualitätssicherung und der wissenschaftlichen Kooperation zwischen qualitativ Forschenden.
Keywords: Grounded Theory; CAQDAS; computerunterstützte qualitative Datenanalyse; ATLAS.ti; XML; Datenstruktur; maschinelle Nutzung von Forschungsergebnissen
Inhaltsverzeichnis
1. Einleitung
2. Einführendes zu ATLAS.ti
2.1 ATLAS.ti – methodologische Einflüsse
2.2 ATLAS.ti – Datenkonzept
2.3 Interaktion mit ATLAS.ti
3. Das Forschungsprojekt
4. Umsetzung der methodischen Schritte der GTM in ATLAS.ti
4.1 Zum Begriff "Konzept"
4.2 Offenes Kodieren
4.3 Axiales Kodieren
4.4 Selektives Kodieren
4.5 Zusammenspiel von Kodierprozessen in der GTM und entstehendem Datennetz
5. Möglichkeiten und Grenzen der netzwerkartigen Datenstruktur von ATLAS.ti für GTM-Forschungsarbeiten
5.1 Störende Implikationen
5.2 Positive Implikationen
6. Zusammenfassung und Ausblick
Computerprogramme zur Unterstützung der Analyse qualitativer Daten sind sich in ihrer Grundfunktionalität sehr ähnlich. LEWINS und SILVER (2007) vergleichen praxisnah und komplex drei führende CAQDAS1)-Produkte entlang der Aufgaben, die i.d.R. bei qualitativen Forschungsarbeiten anfallen. Verglichen wird unter anderem, wie Modelle dargestellt und Konzepte zueinander in Beziehung gesetzt werden können. Dabei weisen die Autorinnen auf eine Besonderheit von ATLAS.ti hin: "Only ATLAS.ti automatically remembers the links made between two or more codes in subsequent maps where they appear. In other packages, maps are more like scribble pads" (S.184). Dieser Aspekt wird im Folgenden bezogen auf Forschungsarbeiten, in denen die Grounded-Theory-Methodologie (GTM) zum Einsatz kommt, vertieft. [1]
Wesentlich bei der Herangehensweise einer qualitativen Datenanalyse im Sinne der GTM (und zwar für die unterschiedlichen GTM-Varianten) ist die Grundannahme, dass die untersuchten Phänomene komplex sind. Zur Abbildung von Komplexität gehört, "daß eine Theorie ... konzeptuell dicht sein muß – also müssen viele Konzepte mit ihren Querverbindungen erarbeitet werden" (STRAUSS 1991, S.36). In ATLAS.ti werden die erarbeiteten Konzepte und deren Querverbindungen auf der Grundlage einer netzwerkartigen Datenstruktur gespeichert. Es entsteht ein Kode-Netz, von dem man sagen kann, dass es die entwickelte "Grounded Theory" als strukturierte, auf den Begriff gebrachte Information repräsentiert. [2]
Zentrales Anliegen meines Beitrages ist zu zeigen, wie diese netzwerkartige Datenstruktur und die GTM zusammenspielen und oben genanntes Kode-Netz entsteht. Dabei richtet sich der Fokus darauf, dass die technische Realisierung der Querverbindungen zwischen Konzepten über eine allein grafische Darstellung der Beziehungsstruktur – scribble, wie es LEWINS und SILVER (a.a.O.) ausdrücken – hinausgeht. Es wird dargelegt, warum diese Art der Datenorganisation in besonderem Maße geeignet ist, die Ergebnisse von GTM-Arbeiten festzuhalten. [3]
Im zweiten Abschnitt wird zunächst kurz in ATLAS.ti2) eingeführt. Im dritten Abschnitt wird ein noch laufendes Forschungsprojekt zum Thema "Rekonstruktion von gelungenen therapeutischen Prozessen aus Sicht der Klient/innen" vorgestellt, an dem Ingeborg SCHÜRMANN und ich arbeiten. Aus diesem Projekt stammen die Beispiele, anhand derer das Datenkonzept und sein Bezug zur GTM ausgeführt werden. Zentrum des Beitrags ist der vierte Abschnitt. Hier zeige ich, wie die methodischen Bausteine einer Datenanalyse nach der GTM in ATLAS.ti umgesetzt werden und welche besondere Rolle dabei die interne Strukturierung der Daten als Netz spielt. Mit Grenzen und Vorzügen des netzwerkartigen Datenkonzeptes und der Anschlussfähigkeit an aktuelle Entwicklungen im Bereich von Open Access zu Daten3), insbesondere der maschinellen Weiternutzung von Ergebnissen eines in ATLAS.ti bearbeiteten Projekts, befasst sich der fünfte Abschnitt. Anknüpfend an die Potenziale der maschinellen Weiternutzung von Ergebnissen wird im letzten Abschnitt auf die wünschenswerte Debatte zwischen Methodiker/innen und CAQDAS-Entwickler/innen eingegangen. [4]
2.1 ATLAS.ti – methodologische Einflüsse
ATLAS.ti wurde im Kontext eines interdisziplinären Forschungsprojektes unter Leitung von Heiner LEGEWIE an der Technischen Universität Berlin entwickelt, in dem Psycholog/innen, Linguist/innen und Informatiker/innen zusammenarbeiteten. Das geplante Programm sollte qualitative Sozialforscher/innen, Linguist/innen und auch potenzielle andere Nutzer/innengruppen bei der Textinterpretation unterstützen. Design und methodologische Konzeption wurden beeinflusst von Nutzer/innenbefragungen und ganz wesentlich "... by the ideas, terminology and methodological processes associated with 'grounded theory'" (MUHR 1991, S.351), denn die GTM war die vorherrschende Methode der im Forschungsprojekt engagierten Psycholog/innen (BÖHM & LEGEWIE & MUHR 2008 [1992]). [5]
2.2 ATLAS.ti – Datenkonzept4)
ATLAS.ti legt das Datenmaterial eines Forschungsprojektes und die Ergebnisse der analytischen Arbeit in sogenannten objects ab. Es gibt die folgenden Hauptobjekte (main objects): 1. Primary Docs (PDs), die Verweise auf das Datenmaterial enthalten5), 2. Quotations, die auf Zitate im Datenmaterial verweisen6), 3. Kodes, die Begriffe bzw. Stichwörter enthalten und 4. Memos für Textnotizen. Diese können auf zwei unterschiedliche Weisen gruppiert werden, als families und als networks. Anhand von families können main objects gleichen Typs klassifiziert und in Untergruppen aufgeteilt werden, z.B. eine Primary Doc family mit Interviewpartner/innen einer bestimmten Altersgruppe. Anhand von networks dagegen können main objects beliebigen Typs miteinander verbunden werden7). Dabei kann (fast) jedes Objekt mit jedem verknüpft werden. Mithilfe von networks können z.B. die während der Interpretation erarbeiteten Konzepte auf komplexe Art und Weise zueinander in Beziehung gesetzt werden. Hinter dieser Organisationsform steht folgende Idee:
"In contrast with linear, sequential representations (e.g., text), presentations of knowledge in networks resemble more closely the way human memory and thought is structured. Cognitive 'load' in handling complex relationships is reduced with the aid of spatial representation techniques. ATLAS.ti uses networks to help represent and explore conceptual structures" (MUHR & FRIESE 2003-2004, S.211). [6]
Die Kodierung und Annotierung des Datenmaterials, die Gruppierung zu Familien und die komplexe Verbindung der oben eingeführten main objects zu networks werden in ATLAS.ti mittels einer netzwerkartigen Datenstruktur realisiert. Dabei werden die main objects, d.h. die PDs (Datenmaterial), die quotations (Zitate), die Kodes (Begriffe oder Stichwörter) und Memos (Textnotizen) zu Knoten des Netzes, die miteinander verbunden bzw. (in der Terminologie von ATLAS.ti) miteinander "verlinkt" werden können. (Man sagt auch, es wird ein Link zwischen zwei main objects gesetzt.) Links zwischen zwei Kodes8) (im Gegensatz zu einem Link zwischen Kode und quotation und anderen Links) verfügen über ein zusätzliches Merkmal. Ein Link zwischen Kodes kann auf der Basis einer Liste von Relationen qualifiziert werden, d.h., dass der/die Forschende den Link dazu nutzen kann, die Beziehung (Relation), in der zwei Konzepte (Kodes) zueinander stehen zu explizieren. Kodes werden also nicht unspezifisch miteinander verbunden, sondern anhand einer Relation qualifizierend zueinander in Beziehung gesetzt. Dadurch werden dreistellige Statements möglich, z.B. "Wasser" "ist Bedingung für" "Pflanzenwachstum". In diesem Statement wurden die beiden Konzepte (Kodes) "Wasser" und "Pflanzenwachstum" durch "ist Bedingung für" (Relation) zueinander in Beziehung gesetzt. (Näheres dazu in Abschnitt 4.3.) [7]
Auf der Grundlage der netzwerkartigen Datenstruktur werden zum einen die Kodierungen (als Verbindungen zwischen Kodes und quotations), die Annotierung von Datenmaterial (als Verbindungen zwischen Memos und quotations), die konzeptuelle Arbeit (die durch eine Relation qualifizierte Verbindung zwischen Kodes) und darüber hinaus auch die Verknüpfung dieser Ebenen gespeichert. Man erhält mit dieser Form der Speicherung eine Art Gesamtpaket, genauer ein Daten-Netz, das alles enthält: Verweise zum Datenmaterial und sämtliche Ergebnisse der analytischen Arbeit. [8]
Es können zwei Arbeitsebenen unterschieden werden: die Arbeit am Text und die Theoriebildungsarbeit im engeren Sinne. Für die Arbeit am Text steht der sogenannte HU-Editor9) zur Verfügung, mit dem das Datenmaterial kodiert und annotiert werden kann. Für die Theoriebildung steht ein sogenannter Network-Editor zur Verfügung. Im Network-Editor können Konzepte (Kodes) zueinander in Beziehung gesetzt werden, indem sie miteinander verbunden werden (Näheres dazu in Abschnitt 4.3). Darüber hinaus können im Network-Editor die Kodierungen und Annotierungen am Datenmaterial angezeigt (Näheres in Abschnitt 4.2) und die beiden Ebenen (Arbeit am Datenmaterial und Theoriebildung) miteinander verbunden werden. [9]
Wir nutzen ATLAS.ti in drei miteinander verknüpften Feldern, der Lehre, bei Abschlussarbeiten und im Forschungsprojekt "Rekonstruktion von gelungenen therapeutischen Prozessen aus Sicht der Klient/innen". Ziel des Forschungsprojektes ist es, herauszuarbeiten, was Nutzer/innen bei der Inanspruchnahme von professioneller Hilfe im psychosozialen Kontext als relevant erachten und was für eine positive Einschätzung der erhaltenen Hilfe ausschlaggebend ist. Zur Beantwortung dieser Frage wurden sowohl Interviews mit Nutzer/innen psychosozialer Einrichtungen (z.B. Beratungsstellen) geführt als auch Literatur mit Berichten über erhaltene professionelle Hilfe hinzugezogen. [10]
Bei der Analyse unserer Daten orientieren wir uns an der GTM nach STRAUSS und CORBIN (STRAUSS 1991; STRAUSS & CORBIN 1996; CORBIN & STRAUSS 2008). Grund für diese Entscheidung ist, dass das STRAUSSsche Paradigma zum einen eine klare Struktur vorgibt, zum anderen innerhalb dieser Struktur sehr allgemein gehalten ist, d.h. ein sowohl gehaltloser (MEY & MRUCK 2007) als auch pragmatischer (STRÜBING 2007) heuristischer Rahmen für konkrete Forschungsanliegen ist. Im Kontext der Beispiele, die das Zusammenspiel zwischen ATLAS.ti und GTM veranschaulichen, werden Forschungsteilfragen herausgegriffen und erste Ergebnisse vorgestellt. [11]
4. Umsetzung der methodischen Schritte der GTM in ATLAS.ti
Die GTM nach Anselm STRAUSS und Juliet CORBIN (1996) unterscheidet die Analysestrategien offenes, axiales und selektives Kodieren. Bevor ich mich diesen drei Kodiertypen und deren Umsetzung in ATLAS.ti im Einzelnen zuwende, stelle ich den Begriff "Konzept" vor, der mit dem Begriff "Kode" eng verbunden ist. [12]
Innerhalb der GTM-Literatur werden die Begriffe Konzept, Kategorie und Kode je nach Kontext teilweise (fast) synonym, teilweise (eher) differenzierend benutzt. Unbestritten hängen diese Begriffe eng miteinander zusammen. Ich orientiere mich bezüglich meines Verständnisses von "Konzept" am bilateralen Zeichenbegriff10), der vor allem durch Ferdinand De SAUSSURE (1967 [1931]) Bedeutung erlangt hat: "Er beschrieb das sprachliche Zeichen als Verbindung von Vorstellung (concept) und Lautbild (image acoustique)" (BERGENHOLTZ & MUGDAN 1979, S.30). Mit Konzept ist also die Bedeutungs-, Sinn-, oder Inhaltsseite eines sprachlichen Zeichens (z.B. eines Wortes) gemeint, während das Lautbild (oder Schriftbild) für die Ausdrucksseite eines sprachlichen Zeichens steht. Der bilaterale Zeichenbegriff geht davon aus, dass Konzept und Lautbild untrennbar miteinander verbunden sind und zusammen das sprachliche Zeichen ausmachen. [13]
Geht man mit diesem Verständnis z.B. an die Tätigkeit des offenen Kodierens (Abschnitt 4.2) heran, so lässt es sich in zwei Schritte zerlegen: Im ersten Schritt wird konzeptualisiert, d.h. es wird versucht, die Bedeutung einer spezifischen Textpassage (oder eines Bild- oder Videoausschnittes) zu erfassen, im zweiten Schritt wird versucht, den geeigneten Ausdruck, d.h. Kode, für diese Bedeutung zu finden. Da Bedeutung und Ausdruck untrennbar miteinander verbunden sind, steht hinter jedem Kode ein Konzept und umgekehrt benötigt jedes Konzept einen Konzeptnamen, den Kode. [14]
Was am Beispiel des offenen Kodierens verdeutlicht wurde, gilt für alle sprachlichen Zeichen. So stehen beispielsweise hinter den von GLASER (1978) formulierten "theoretischen Kodes" soziologische Konzepte der sogenannten grand theories, z.B. "Selbstbild", "Identität", "Sozialisation" und erkenntnistheoretische Konzepte (MEY & MRUCK 2007, S.27). [15]
Zur Terminologie in diesem Text: Als synonym werden verwendet "Konzeptname" und "Kode", "generelles Konzept" und "Kategorie", "Kategoriename" und "Kategorie-Kode". [16]
Das offene Kodieren umfasst folgende analytische Schritte: 1. den relevanten Textstellen Kodes zuordnen (d.h. textnahes Kodieren), 2. die Kodes zu (vorläufigen) Kategorien zusammenfassen und 3. die Kategorien anhand von Eigenschaftskonzepten dimensionalisieren. Zentrale Aufgabe der/des Forschenden ist, sich offen und Fragen stellend mit dem Datenmaterial auseinanderzusetzen und Konzepte unterschiedlicher Abstraktionsstufen zu erarbeiten, die helfen, die Daten bezogen auf das Forschungsthema konzeptuell zu beschreiben oder, wie es Juliet CORBIN und Anselm STRAUSS ausdrücken: "... we do believe that concepts of various levels of abstraction form the basis of analysis. Concepts provide ways of talking about and arriving at shared understandings among professionals" (2008, S.8). [17]
Ich zeige das textnahe Kodieren mit ATLAS.ti an einem Beispiel aus dem oben vorgestellten Forschungsprojekt. Das Beispiel basiert auf einer Frage, die ein ganz bestimmtes Interesse zusammenfasst, das im Dialog mit den Daten regelmäßig auftrat: "Was konkret führte zur Inanspruchnahme von Hilfe?" Gezeigt wird das Ergebnis aus zwei Dokumenten, einem Bericht über eine Verhaltenstherapie wegen einer Zwangsstörung (in den Abbildungen gekennzeichnet mit P1 = Klient) und einem Bericht über eine einmalige Beratung wegen eines Problems mit einem Mitglied der Wohngemeinschaft (gekennzeichnet mit P2 = Nick [Psyeudonym der Klientin]). [18]
Ich werde den HU-Editor vorstellen, in dem kodiert wird, die "sichtbaren" Produkte erläutern, die bei der Kodierung entstehen und dann zum zentralen Thema dieses Abschnitts kommen, nämlich wie textnahes Kodieren und netzwerkartiges Datenkonzept zusammenhängen.
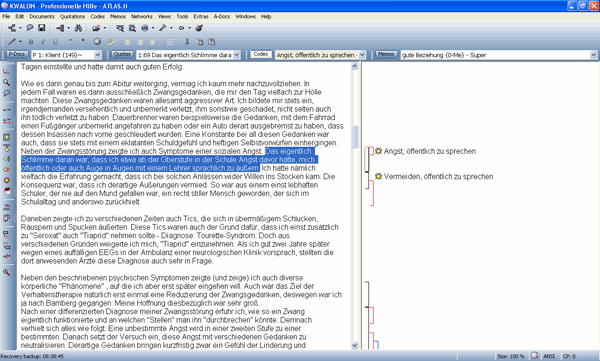
Abbildung 1: Hauptbildschirm von ATLAS.ti – der HU-Editor [19]
Der Hauptbereich des HU-Editors (Abb. 1) besteht aus zwei Teilen, links wird das zu kodierende Datenmaterial angezeigt, rechts die Arbeit des/der Forschenden am Text. Im rechten Rand werden z.B. die Kodes eingetragen, die einzelnen Textstellen zugeordnet worden sind. In diesem Beispiel ist eine kodierte Textstelle hervorgehoben und am rechten Rand der zugeordnete Kode "Angst, öffentlich zu sprechen" markiert. [20]
Durch das Kodieren entsteht einerseits eine Liste von Zitaten (Abb. 2) und andererseits eine Liste von Kodes (Abb. 3), wobei die zweite Liste aus der ersten hervorgeht.
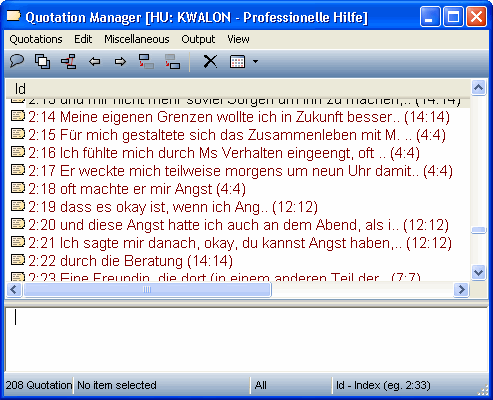
Abbildung 2: Liste der Zitate
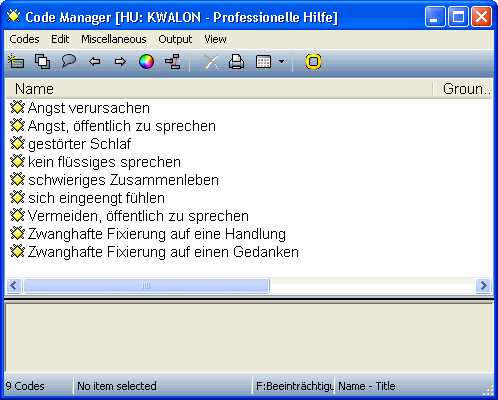
Abbildung 3: Liste der Kodes (Ausschnitt) [21]
Zitate und Kodes machen aber noch nicht die Kodierung aus. Eine Kodierung besteht aus einer Verbindung zwischen Zitat und Kode (siehe Abb. 4). Diese wird beim Kodiervorgang automatisch erstellt. Mithilfe des in Abschnitt 2.3 vorgestellten Network-Editors kann man sich die Verbindung ansehen.
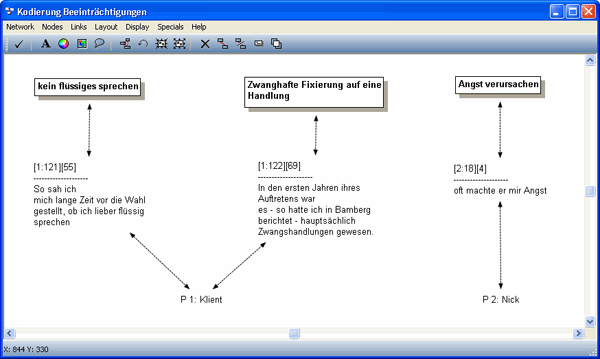
Abbildung 4: Kodierungen als Verbindungen zwischen Zitaten und Kodes [22]
Schauen wir uns das in Abbildung 4 genauer an: Am unteren Rand sind die Namen der Dokumente aufgeführt (P1: Klient und P2: Nick), aus denen die kodierten Zitate stammen. In der mittleren Zeile sehen Sie drei Zitate: "oft machte er mir Angst", "So sah ich mich lange Zeit vor die Wahl gestellt, ob ich lieber flüssig sprechen" und ein weiteres Zitat.11) Am oberen Rand stehen die Kodes "Angst verursachen", "kein flüssiges sprechen" und "zwanghafte Fixierung auf eine Handlung". Pfade, sogenannte Links, führen vom Kode zum Zitat und vom Zitat zum Primärdokument. Kodierungen werden basierend auf der netzwerkartigen Datenstruktur also gespeichert als eine Verbindung zwischen Dokumenten, Zitaten und Kodes. [23]
Mit dem textnahen Kodieren wird das Fundament einer Grounded Theory gelegt: Alle Textstellen, die kodiert wurden, sind potenzielle "Belege" der sich entwickelnden Theorie. Alle weiteren konzeptionellen Arbeiten stellen Bezüge zu diesem Fundament her und sind somit in den Daten verankert ("gegroundet"). [24]
4.2.2 Gruppierung von textnahen Kodes zu Kategorien
Der zweite analytische Schritt des offenen Kodierens ist die Identifizierung von Gemeinsamkeiten unter den textnahen, tendenziell detaillierten Kodes. Es werden generellere Konzepte erarbeitet und es wird nach passenden Bezeichnungen für diese Konzepte gesucht. Ergebnis dieses Schrittes sind vorläufige Kategorien mit ihren Kategorien-Kodes (STRAUSS & CORBIN 1996, S.47). Es gibt drei unterschiedlich arbeitende Tools (Werkzeuge) in ATLAS.ti, mit denen Kodes zu Kategorien zusammengefasst werden können: der "Network-Editor", der "Code-Family-Manager" und das "Query-Tool". [25]
Mithilfe des Network-Editors kann ein Kode-Baum erstellt werden, der die Kategorie (das generelle Konzept) mit ihren Mitgliedern repräsentiert. Im ersten Schritt wird für die Kategorie ein Kode12) definiert. Anschließend werden die zu bündelnden spezifischeren Kodes (also die während des textnahen Kodierens erstellten Kodes) mit diesem Kode (dem Kategorien-Kode) verbunden. Zur Qualifizierung der Verbindung werden i.d.R. hierarchische13) Relationen eingesetzt, also je nach Bedeutung der Beziehung zwischen Kategorie (generelles Konzept) und spezifischeren Kodes eine Oberbegriff-Unterbegriff-Relation oder eine Ganzes-Teile-Relation. [26]
Wenn noch vieles vorläufig ist oder sich die Idee zu einer Kategorie noch in der Anfangsphase befindet, können die spezifischeren Kodes auch zunächst mithilfe des Code-Family-Managers zu einer code family14) gebündelt werden. Vorteil dieser Variante ist, dass der zeitliche Aufwand, einen Kode einer Familie zuzuordnen, gering ist. Families können in ATLAS.ti allerdings nicht miteinander verbunden werden, sodass das axiale Kodieren (Abschnitt 4.3) nicht mit families durchgeführt werden kann. Diese Restriktion ergibt sich aus der technischen Umsetzung des ATLAS.ti-Familienkonzeptes (siehe auch MUHR & FRIESE 2003- 2004). Eine als family realisierte vorläufige Kategorie, die sich als relevant für die entstehende Theorie erweist, muss deshalb für den weiteren Forschungsprozess in einen Kode-Baum transferiert werden. Es gibt eine Programm-Option ("family/create network"), mit der dies zügig durchgeführt werden kann. [27]
In der Query-Tool-Variante werden die spezifischeren Kodes über die Formulierung einer Suchabfrage zu einer Kategorie gebündelt. Das bedeutet, dass die inhaltliche Bündelung durch einen Booleschen Operator (z.B. den oder-Operator) hergestellt wird. Der Suchabfrage wird ein sogenannter super code zugeordnet, der dann die Kategorie (das generellere Konzept) repräsentiert. Ein Beispiel: Ein Text wurde kodiert mit den Kodes "Hund", "Katze", "Maus" und "Pferd". Um diese Kodes unter dem generelleren Konzept "Säugetier" zusammenzufassen, wird im Query-Tool folgende Suchabfrage erstellt: Finde alle Zitate, die folgender Bedingung genügen: "Hund" oder "Katze" oder "Maus" oder "Pferd". Die Suchanfrage wird anschließend unter dem in ATLAS.ti als super code bezeichneten Namen "Säugetier" abgespeichert. [28]
In allen drei Varianten wird technisch eine Beziehung zwischen textnahen Kodes und Kategorie hergestellt. Durch den textnahen Kode erhält jede Kategorie eine Verbindung zum Datenmaterial. [29]
4.2.3 Beispiel: Realisierung einer Kategorie mithilfe des Network-Editors
Um die Realisierung einer Kategorie mithilfe des Network-Editors zu zeigen, möchte ich auf das oben vorgestellte Beispiel zurückkommen. Die Frage lautete: "Was konkret führte zur Inanspruchnahme von Hilfe?" – Um alle textnahen, spezifischen Kodes zu dieser Frage unter einer Kategorie zusammenfassen zu können, haben wir die textnahen Kodes und die zugehörigen Zitate untereinander verglichen und das gemeinsame Phänomen herausgearbeitet: dass sich die Klient/innen in ihrem Alltag so beeinträchtigt fühlten, dass sie sich entschlossen haben, professionelle Hilfe in Anspruch zu nehmen. Wir formulierten also das Konzept "Beeinträchtigung". Dieses generelle Konzept bzw. diese Kategorie bietet die Möglichkeit, eine Vielzahl von Behinderungen, Störungen, Krankheiten, etc. zusammenzufassen. Die nächste Abbildung 5 zeigt die Realisierung von "Beeinträchtigung" mithilfe des Network-Editors.
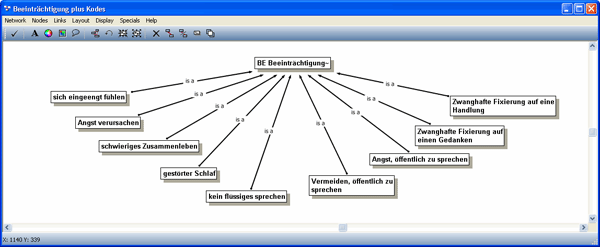
Abbildung 5: Kategorie "Beeinträchtigung" mit ihren Kodes [30]
Bei der Realisierung einer Kategorie durch ein Network werden die Kodes, die spezifische bzw. untergeordnete Konzepte repräsentieren, mittels einer hierarchischen Relation mit dem Kode, der das generellere bzw. übergeordnete Konzept repräsentiert, verbunden. Hier wurde mit der Relation "is a" eine Oberbegriff-Unterbegriff-Relation ausgedrückt. Eine Programm-Option ermöglicht, die Zitate zu den textnahen Kodes hinzuzufügen. Abbildung 6 zeigt, dass alle von den Forschenden kreierten Objekte, Kategorie-Kode, textnahe Kodes und Zitate netzwerkartig miteinander verbunden sind. Über diese Verbindungen ("Links") können sämtliche Textstellen zu einer Kategorie aufgefunden werden.15)
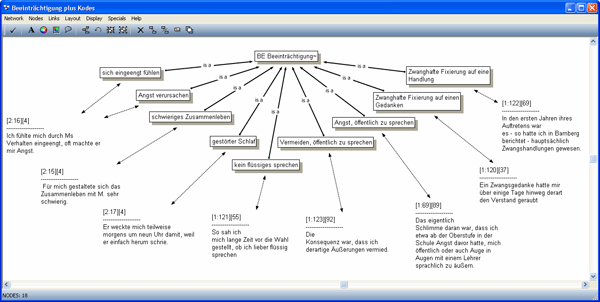
Abbildung 6: Kategorie "Beeinträchtigung" mit Kodes und Zitaten [31]
Und damit schlage ich wieder den Bogen zur GTM und der groundedness von Konzepten. Über Pfade oder "Links" kann in ATLAS.ti der Weg von generellen Konzepten (dem Kategorien-Kode) über die spezifischeren Konzepte (den textnahen Kodes) zu den Rohdaten (Zitate) zurückverfolgt werden. Generelle Konzepte sind also indirekt in den Daten begründet (gegroundet). [32]
Die zweite grundlegende Analysestrategie der GTM nach STRAUSS und CORBIN ist das axiale Kodieren16). Das axiale Kodieren dient zum einen der Verfeinerung und Differenzierung schon vorhandener Kategorien und zum anderem dem Herausarbeiten von Beziehungen (Relationen) zwischen den Kategorien "... und den damit in Beziehung stehenden Konzepten in ihren formalen und inhaltlichen Aspekten. Die Achsenkategorie wird in ihren zeitlichen und räumlichen Beziehungen, Ursache-Wirkungsbeziehungen, Mittel-Zweckbeziehungen, argumentativen, motivationalen Zusammenhängen ausgearbeitet" (BÖHM, LEGEWIE, MUHR 2008 [1992], S.54). [33]
So wie beim offenen Kodieren Fragen an das Datenmaterial gestellt und Textstellen verglichen werden, basiert auch das axiale Kodieren17) auf Fragen und systematischem Vergleichen. Beim axialen Kodieren wird jedoch nach der Art der Beziehung gefragt, die zwischen zwei Konzepten18) bestehen, die während des offenen Kodierens erarbeitet worden sind. [34]
Auch wenn es möglich ist, ohne theoretische Vorannahmen die Art der Beziehung zwischen zwei Konzepten zu erarbeiten, basiert das axiale Kodieren in der Regel auf spezifischen, auch als erkenntnisleitend bezeichneten Fragen19), die ausgehend von dem ins Zentrum gestellten Konzept (im obigen Zitat Achsenkategorie genannt) weiterführend an das Datenmaterial gestellt werden. Derlei "Hauptfragen" können je nach Fachdisziplin und Forschungsthema unterschiedlich sein. An Soziolog/innen und primär an Handlungen interessierte Forscher/innen gerichtet repräsentiert das von Anselm STRAUSS und Juliet CORBIN (1996) formulierte Paradigma ein interaktionales Handlungsmodell. Es besteht im Wesentlichen aus einer Zusammenstellung von Bedingungstypen und Handlungstypen, anhand derer das Datenmaterial analysiert wird: "Highly simplified, the model looks something like this: (A) causual conditions → (B) phenomenon → (C) context → (D) intervening conditions → (E) action/interaction strategies → (F) consequences" (S.99) [35]
Beim axialen Kodieren geht es also schwerpunktmäßig um die Kodierung von Zusammenhängen zwischen Konzepten, die während des offenen Kodierens erarbeitet worden sind. Bezug nehmend auf den in Abschnitt 4.1 thematisierten Konzept-Begriff kann nun im Kontext des axialen Kodierens der Begriff des relationalen Konzeptes eingeführt werden. Es handelt sich dabei um Konzepte, deren Funktion es ist, andere Konzepte zueinander in Beziehung zu setzen. Das Konzept der Bedingung in STRAUSS' und CORBINs Paradigma ist beispielsweise ein relationales Konzept. In dem Statement "Wasser ist eine Bedingung für Pflanzenwachstum" (siehe dazu auch Abschnitt 2.2) werden die beiden Konzepte "Wasser" und "Pflanzenwachstum" durch das relationale Konzept "ist Bedingung für" miteinander verbunden und zueinander in Beziehung gesetzt. Da ein wesentliches Ziel der GTM ist, Zusammenhänge aufzuzeigen, d.h. zu zeigen, unter welchen Bedingungen wie agiert wird, spielen relationale Konzepte eine bedeutsame Rolle20). [36]
4.3.1 Vorbereitende Arbeiten zum axialen Kodieren mit ATLAS.ti
Das axiale Kodieren wird in ATLAS.ti im Network-Editor durchgeführt. Dort können die während des offenen Kodierens erarbeiteten Konzepte bzw. Kodes miteinander verbunden und zueinander in Beziehung gesetzt werden. Um die Art der Beziehung bzw. die semantische Bedeutung der Beziehung ausdrücken zu können, steht der/dem Forschenden eine Liste von Relationen zur Verfügung (siehe Abschnitt 2.2). So wie beim offenen Kodieren entweder neue Kodes definiert oder schon definierte Kodes aus der Kodeliste benutzt werden, werden beim axialen Kodieren entweder schon erfasste Relationen benutzt oder neue definiert. [37]
Wie schon im vorangegangenen Abschnitt thematisiert, wird in der Regel auf der Basis erkenntnisleitender Fragen axial kodiert, d.h., dass die interessierenden Relationen zu Beginn des Projektes in der Relationenliste erfasst werden. [38]
Die Relationenliste erfüllt in ATLAS.ti also eine andere Aufgabe als die Kodeliste. ATLAS.ti-Kodes (Kodeliste) sind dazu gedacht, Phänomene des Untersuchungsfeldes konzeptionell festzuhalten, z.B. "Krankheit", "Schmerz", "Medikamenteneinnahme", "Schmerzlinderung", während in ATLAS.ti-Relationen (Relationenliste) die Konzepte erfasst werden, die hinter den Hauptfragen stehen, die die Untersuchung leiten. Das sind bei einer Grounded-Theory-Arbeit z.B. Relationen wie "is-condition-for", "is-strategy-for", "is-consequence-of", während in einer Analyse von Argumentationsstrukturen Relationen wie "is-evidence-of", "is-contradictory-of", "warrants" etc. geeigneter sind (MUHR & FRIESE 2003-2004, S.214). In Relationen wird also ein Teil des theoretischen Hintergrundes (theoretical framework) erfasst. Erst zusammen, anhand von Kodes und Relationen, werden theoretische Aussagen über das Untersuchungsfeld möglich. [39]
Es ist dennoch nicht so, dass zur Repräsentation des theoretischen Hintergrundes zwingend die Relationenliste von ATLAS.ti verwendet werden muss. Man könnte (in einer GTM-Arbeit) auch einen Kode "Ursachen der Schmerzsymptomatik" definieren und alle gefundenen Ursachen von Schmerz diesem Kode unterordnen. Was spricht dagegen und warum und wann ist die Verwendung der Relationenliste die bessere Wahl? [40]
Ein Beispiel von Jörg STRÜBING (2004, S.28) thematisiert den Aspekt von Beziehungen (Relationen) zwischen Konzepten:
"Für die Schmerzsymptomatik eines Patienten mögen die inkompetenten handwerklichen Leistungen eines jungen Assistenzarztes ... kausal sein, während sie in Bezug auf die Analyse der Beziehung zwischen der Chefärztin und ihrem Assistenten eine der resultierenden Konsequenzen sein mag (... zu wenig Anleitung ...)". [41]
Die "inkompetente handwerkliche Leistung des Assistenzarztes" ist für sich genommen weder eine ursächliche Bedingung noch eine Konsequenz. Sie ist Bedingung und Konsequenz in Bezug auf ein anderes Konzept: "ursächlich" in Bezug auf "Schmerzsymptomatik" und "Konsequenz" in Bezug auf "zu wenig Anleitung". [42]
Die im STRAUSS' und CORBIN'schen Paradigma aufgeführten Konzepte causual conditions, context, intervening conditions und consequences sind also keine Kategorien, die Phänomene des Untersuchungsfeldes konzeptualisieren, sondern Konzepte, die Beziehungen zwischen Phänomenen ausdrücken. Diese relationalen Konzepte werden aus meiner Sicht in ATLAS.ti am besten mithilfe des Programmkonzepts der Relationenliste repräsentiert. [43]
Ein ganz anderer Konzepttyp sind die im STRAUSS' und CORBIN'schen Paradigma aufgeführten Konzepte action und interaction. Beobachtungen im Feld – wie arbeiten, spielen, bauen, diskutieren etc. – sind durchaus für sich genommen "Handlungen" und "Interaktionen". Handlungen und Interaktionen könnten also auch durch einen Kategorien-Kode repräsentiert werden. Dennoch werden sie in einer Grounded-Theory-Studie besser durch die Relation is-strategy-for repräsentiert. Warum? Der Umstand, dass es sich bei arbeiten, spielen, bauen etc. um Handlungen handelt, interessiert nicht so sehr. Sie werden bedeutsam dadurch, dass sie strategisch eingesetzt werden, um etwas ganz Bestimmtes zu erreichen, in der Regel die Bewältigung eines Problems, d.h. die Handlungen beziehen sich auf das gerade im Fokus der Analyse stehende Phänomen. [44]
Wird nach STRAUSS' und CORBINs Paradigma analysiert, werden in der Relationenliste die im Paradigma zusammengestellten erkenntnisleitenden Konzepte als Relationen erfasst. Relationen fungieren in dieser Weise als relationale Kodes, mit denen axial kodiert wird. Anhand eines Beispiels, der Bewältigung von Schmerz (in Analogie zum Beispiel in STRAUSS & CORBIN 1996)21), wird in der nachfolgenden Abbildung gezeigt, wie das Ergebnis einer axialen Kodierung in ATLAS.ti aussieht.
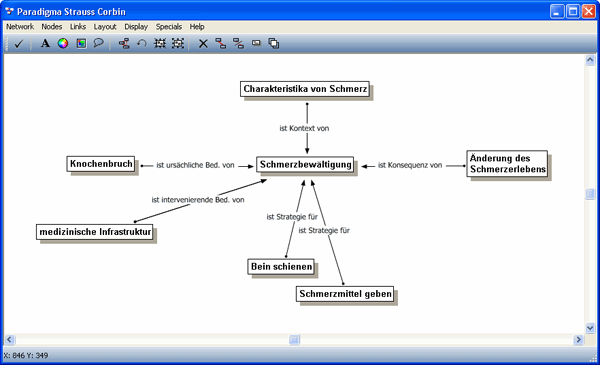
Abbildung 7: Paradigmatisches Modell nach STRAUSS und CORBIN (1996) am Beispiel von Schmerz [45]
4.3.2 Vorgehensweise beim axialen Kodieren
Ich zeige zunächst die Vorgehensweise beim axialen Kodieren an einem Beispiel aus dem skizzierten Forschungsprojekt (Abschnitt 3) und werde abschließend auf die Beziehung zwischen axialem Kodieren und der netzwerkartigen Datenstruktur eingehen. Es handelt sich bei diesem Beispiel um eine axiale Kodierung auf der untersten Abstraktionsstufe, den textnahen Kodes. [46]
Aufgabenstellung
In dieser Phase des Projektes setzten wir uns mit bewertenden Aspekten in den Berichten und Interviews auseinander. Die Nutzer/innen sprachen wertend über die Professionellen, über das Setting eines Gesprächs und Erfolge und Misserfolge der Therapie. Wir griffen den Aspekt Erfolge und Misserfolge der Therapie heraus und fragten uns, was Nutzer/innen für förderlich bzw. hinderlich hielten für den Therapieerfolg. Wir formulierten folgende Forschungsteilfrage: "Wie wird das Zustandekommen eines Therapieergebnisses oder Zwischenergebnisses von dem/der Nutzer/in begründet?" Zur Beantwortung dieser Frage suchten wir nach Textstellen, die Auskunft über ein Therapieergebnis, ein Zwischenergebnis oder einen Teilerfolg gaben, kodierten sie und stellten die weiterführende Frage an den Text, nämlich, was der/die Nutzer/in über das Zustandekommen bzw. Nicht-Zustandekommen eines Ergebnisses sagte. [47]
Ablauf der Kodierung anhand eines konkreten Beispiels
Als Beispiel sei die folgende Textstelle hinzugezogen:
"Wenn es mir dagegen gelang, mich über eine gewisse Zeit (die meistens leider viel zu kurz war) davon [Anmerkung: dem Zwangsgedanken] zu lösen, so war das Gefühl der Befreiung gleichermaßen phänomenal." [48]
Wir kodierten die Textstelle mit zwei Fragen "im Hinterkopf": Was wurde erreicht? Wie wurde das Erreichte bewertet? Das führt zu den Kodes: "sich lösen vom Zwangsgedanken" und "Hochgefühl". Die weiterführende Frage an den Text führte zu Textstellen, die wir mit "aufklären über Funktionsweise eines Zwangsgedanken", "hinweisen auf Musterunterbrechung", "Vermeidungsverhalten erkennen" und "eigene Lösungsstrategie entwerfen" kodierten. Wenn alle Textstellen kodiert waren, öffneten wir den Network-Editor für das axiale Kodieren. [49]
Wie Sie Abbildung 8 entnehmen können, ist der Network-Editor zunächst leer. Wir importieren nun alle Kodes, die wir im HU-Editor erstellt haben, per Drag and Drop in das Fenster des Network-Editors. Es ist wichtig zu wissen, dass durch "importieren" keine Kopie eines Kodes erstellt wird, sondern dass mithilfe des Network-Editors aus einer anderen Perspektive auf die Kodes geblickt wird, nämlich aus der Netzwerk-Perspektive. Der Network-Editor ermöglicht, einen "Blick" auf das Datennetz zu werfen. Der/die Forschende bestimmt, welche Netz-Objekte er/sie sehen will. Aktuell benötigen wir die Kodes – sie sind Knoten im Netz – zum axialen Kodieren.
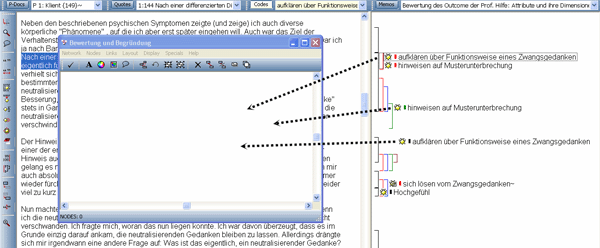
Abbildung 8: Network-Editor überlagert Hauptbildschirm [50]
Dann beginnt das axiale Kodieren. Wir wollen einen Teil der Kodes miteinander verbinden und so die Zusammenhänge zwischen den Kodes zeigen. Hier greifen wir auf die Relationenliste22) zu.
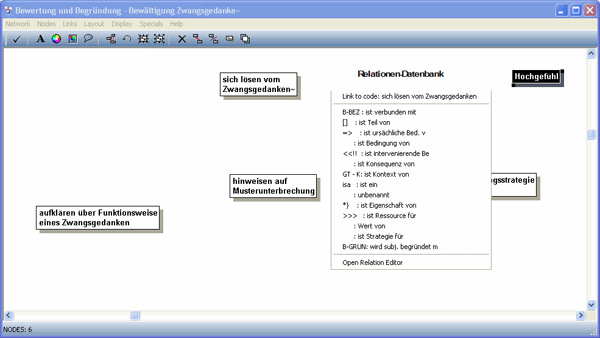
Abbildung 9: Network-Editor mit überlagerter Relationenliste [51]
Wir haben für unser Projekt sowohl die Konzepte des Kodierparadigmas nach STRAUSS und CORBIN (1996) erfasst als auch die Relationen "wird subjektiv begründet mit" und "ist Ressource für". Bei der Relation "wird subjektiv begründet mit" handelt es sich um eine Spezifizierung der "ist ursächliche Bedingung von" im Sinne von STRAUSS und CORBIN. Die Relation "ist Ressource für" repräsentiert die ressourcentheoretische Perspektive, die wir an das Datenmaterial herangetragen haben, und nimmt Bezug auf die Ressourcentheorie von HOBFOLL (2001). [52]
Unter Einsatz der Relationenliste verbinden wir die Kodes zu folgendem Netzwerk:
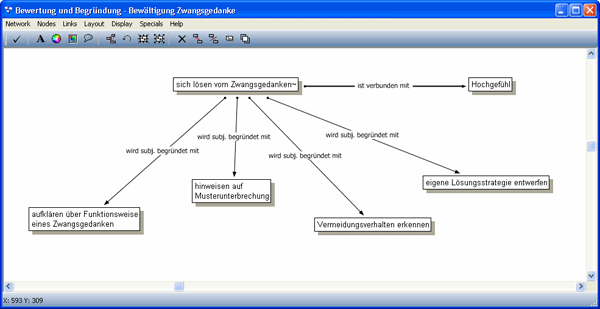
Abbildung 10: Kode-Netzwerk [53]
Das Ausgangszitat hatten wir mit den Kodes "sich lösen vom Zwangsgedanken" und "Hochgefühl" kodiert. Um die Nähe zwischen diesen beiden Konzepten auszudrücken, definierten wir eine weitere Relation: "verbunden mit". Bei dieser Relation handelt es sich um eine vorläufige Relation, die wir eingesetzt haben, wenn wir zu einem Ereignis ein begleitendes Gefühl zum Ausdruck bringen wollten. Solche Gefühlsäußerungen weisen i.d.R. auf Wertungen hin. [54]
4.3.3 Speicherung der axialen Kodierung
Axiale Kodierungen werden in ATLAS.ti auf der Grundlage der netzwerkartigen Datenstruktur als durch Relationen qualifizierte bzw. typisierte Links (Verbindungen) zwischen zwei Kodes gespeichert. Die axiale Kodierung ist Bestandteil des wachsenden Datennetzes und besteht aus: Kode – typisierte Verbindung – Kode. Die typisierte Verbindung bleibt erhalten, solange sie nicht von der/dem Forschenden aktiv getrennt wird. Sämtliche Visualisierungen oder andere Ausgaben zur axialen Kodierung greifen auf diese Speicherung (das Datennetz) zu.23) Wie bereits erwähnt: "Only ATLAS.ti automatically remembers the links made between two or more codes in subsequent maps where they appear" (LEWINS & SILVER 2007, S.184). [55]
Das selektive Kodieren ist der letzte analytische Schritt der GTM, in dem die während des offenen und axialen Kodierens entwickelten Hauptkategorien – das sind die Kategorien mit dem höchsten Niveau der Generalisierung, denen alle anderen entwickelten Konzepte untergeordnet werden konnten – zu einem Ganzen zusammengefügt, d.h. integriert werden (CORBIN & STRAUSS 2008, S.263). Innerhalb dieser das Forschungsprojekt zu einem Ende bringenden Phase werden alle bisherigen Ergebnisse geprüft, vertiefend durchdacht und es wird versucht, das zentrale Phänomen abschließend zu bestimmen, das, worum sich letztendlich alles dreht. Ergebnis dieses Prozesses ist die Formulierung und Prüfung der Kernkategorie. Im Zuge dieses Prozesses werden mithilfe des Paradigmas alle Hauptkategorien mit der Kernkategorie verbunden. Das selektive Kodieren ist in diesem Sinne axiales Kodieren auf einem höheren Niveau der Generalisierung. [56]
4.4.1 Ein Beispiel zum selektiven Kodieren
Das Diagramm in Abbildung 11 zeigt ein Zwischenergebnis während der Phase des selektiven Kodierens innerhalb unseres Forschungsprojektes. Unsere Fälle umfassen ein weites Spektrum professioneller Hilfetypen und damit verbunden unterschiedliche Nutzer/innen-Typen. Alle Klient/innen verfolgten das Ziel, "besser leben zu wollen" (Kernkategorie). In Abhängigkeit von der Art, "sich beeinträchtigt [zu] fühlen", bedeutete "besser leben" für sie etwas Unterschiedliches. Generell ließen sich zwei Typen unterscheiden: die, die "anders leben wollen" und die, die "wieder am Leben teilhaben wollen". Wir fokussierten bei der Integration der Kategorien in einem ersten Schritt auf den Nutzer/innen-Typ "anders leben wollen".
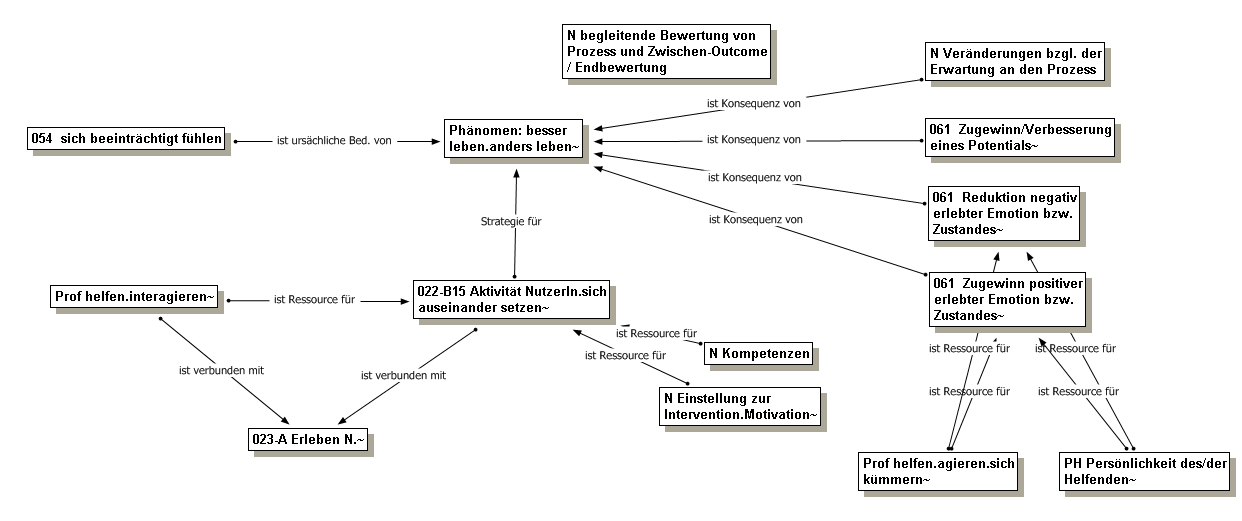
Abbildung 11: Mit der Kernkategorie verbundene Hauptkategorien (dimensionalisiert) [klicken Sie hier für eine Vergrößerung] [57]
Im Zentrum der Abbildung steht der Kode "besser leben. anders leben"24). Verursacht wird das zentrale Phänomen "besser leben (wollen)" durch "sich beeinträchtigt fühlen" (links oben im Bild). Unterhalb von "besser leben. anders leben" befindet sich der Kode "Aktivität NutzerIn. sich auseinander setzen". Hiermit werden die Strategien konzeptionalisiert, die sich auf die (Teil-) Kern-Kategorie "besser leben. anders leben" beziehen. Die Hauptkategorie "Aktivität NutzerIn. sich auseinander setzen" umfasst innere Auseinandersetzungen wie z.B. etwas nachempfinden, nachdenken, abschätzen etc. und äußere Auseinandersetzungen wie sich austauschen, neue Handlungsweisen ausprobieren usw. [58]
Links daneben in der Abbildung findet sich der Kode "Prof helfen. Interagieren". Diese Kategorie wurde konzeptualisiert als Ressource für "Aktivität NutzerIn. sich auseinander setzen". Wir haben unter den Kodes zur Kategorie "Professionelles helfen" zwei Typen ausmachen können: Einerseits der Typus von Aktivitäten der professionell Helfenden, der Aktivitäten der Nutzer/innen nach sich zog, und anderseits ein Typus, der sich auf die Stimmung des Nutzers/der Nutzerin auswirkte. Wir vergaben für diese beiden Typen die Kodes "Prof helfen. interagieren" und "Prof helfen. agieren. sich kümmern". Verbunden durch die Relation "ist verbunden mit" ist unterhalb der Kodes "Prof helfen. Interagieren" und "Aktivität NutzerIn. sich auseinander setzen" der Kode "Erleben N." zu sehen. Mit diesem Kode werden temporäre Stimmungen und Gefühle der Nutzer/innen konzeptionalisiert, die in den Erzählungen zum Ausdruck gebracht wurden, wenn über die Interaktion mit den Helfenden gesprochen wurde. Rechts vom Kode "Aktivität NutzerIn. sich auseinander setzen" sind die Kodes "Einstellung zur Intervention. Motivation" und "N Kompetenzen" zu sehen. Sie wurden als Ressourcen für die Auseinandersetzung des Klienten bzw. der Klientin mit der Therapie konzeptualisiert. [59]
Rechts des Kodes "besser leben.anders leben" sind Kodes aufgeführt, die als Konzepte für Veränderungen stehen, dazu gehören: "Veränderungen bzgl. der Erwartung an den Prozess", "Zugewinn/Verbesserung eines Potentials", "Reduktion negativ erlebter Emotion" und "Zugewinn positiv erlebter Emotion". Die "begleitende Bewertung von Prozess und Zwischen-Outcome" wartet hier noch auf eine Verbindung. Veränderungen können als Zwischenergebnisse während oder auch am Ende des Hilfeprozesses auftreten. [60]
In der Abbildung rechts unten finden sich die beiden Kategorien-Kodes "Persönlichkeit des Helfenden" und "Prof helfen. agieren. sich kümmern". Beide sind neben dem Erreichen positiver Veränderungen Ressourcen für ein gutes Befinden der Klient/innen, d.h. für die "Reduktion negativ erlebter Emotion" und den "Zugewinn positiv erlebter Emotion". [61]
Wie das Beispiel zeigt, bedient man sich für die Umsetzung des selektiven Kodierens in ATLAS.ti der gleichen Mittel wie beim axialen Kodieren, d.h., es wird ein Kode für die Kernkategorie definiert und anschließend werden im Network-Editor Kernkategorie und Hauptkategorien anhand der Relationen aus der Relationenliste miteinander verbunden. Man benötigt für das selektive Kodieren bzw. die abschließende Integration der Hauptkategorien in ATLAS.ti also keine zusätzlichen Programm-Komponenten. [62]
4.5 Zusammenspiel von Kodierprozessen in der GTM und entstehendem Datennetz
Das auf der netzwerkartigen Datenstruktur basierende Kode-Netz, das durch offenes, axiales und selektives Kodieren entsteht, gleicht einer Pyramide. Während des offenen Kodierens werden mehrere Teilnetze über Generalisierungen in die Höhe geknüpft. Dabei kommen hierarchische Relationen zum Einsatz. An der Spitze der Teilnetze stehen als Ergebnisse der Generalisierungsprozesse die Hauptkategorien. Auf jeder Generalisierungsstufe, auch schon auf der Ebene der textnahen Kodes, kann axial kodiert werden. Durch das axiale Kodieren werden Bezüge zwischen den Teilnetzen hergestellt. Es entsteht die für eine Grounded Theory so wichtige Dichte. Nach oben hin wird das Netz schlanker. Idealtypisch steht an der Spitze der Pyramide als Ergebnis des selektiven Kodierens die Kernkategorie, unter der alle Hauptkategorien integriert werden. An der Basis der Pyramide stehen die Zitate. Über die netzartigen Verknüpfungen ist die Kernkategorie an der Spitze mit den Zitaten an der Basis verbunden und die alles umfassende Kernkategorie in den Daten verankert (gegroundet). [63]
5. Möglichkeiten und Grenzen der netzwerkartigen Datenstruktur von ATLAS.ti für GTM-Forschungsarbeiten
Auch wenn das Datenkonzept von ATLAS.ti die Ergebnisse der unterschiedlichen, im Rahmen der GTM zu leistenden Kodierarbeiten überzeugend unterstützt, weist es in der täglichen Arbeit auch Grenzen auf, die im Folgenden dargestellt werden. [64]
5.1.1 Strukturierung der Kodeliste
ATLAS.ti speichert Kodes sequenziell in einer Kodeliste ab. Da während des offenen Kodierens schnell eine umfangreiche Kodeliste entsteht, kann die Suche nach einem spezifischen Kode mühsam werden. Es ist daher notwendig, eine Ordnung in die Liste zu bringen und diese auch konsequent einzuhalten, z.B. indem thematisch ähnliche Kodes in einer Liste untereinander aufgeführt werden25). Dies erfordert Zeit, die eingeplant werden muss. Hierarchisch organisierte Kodesysteme sind auf jeder Hierarchie-Ebene kürzer und werden häufig als organisierter empfunden, was die Einordnung eines neuen Kodes in die Kodeliste und die Suche nach einem Kode leichter macht. Vor- und Nachteile von hierarchischen und nicht-hierarchischen Kodesystemen werden in LEWINS und SILVER (2007, S.94) diskutiert. Dass durch unterschiedliche Kodesysteme tendenziell unterschiedliche Arbeitsstile angeregt werden, thematisieren BOSCH und MÜHLMEYER-MENTZEL (2010). [65]
5.1.2 Hierarchisierung von Kodes
Auch in ATLAS.ti können Kodes hierarchisch geordnet werden, wenn dies erforderlich ist. Als Beispiel kann die Realisierung einer Kategorie mit dem Network-Editor dienen (siehe dazu Abschnitt 4.2.3). Die Hierarchisierung von Kodes erfolgt in ATLAS.ti durch die manuelle Verbindung von Kodes zu einem Kode-Baum durch den/die Forschende. Dies ist ein Verfahren, das im Verhältnis zu Programmen mit hierarchischen Kodesystemen zeitaufwendiger ist. In hierarchisch (vor-) organisierten Kodesystemen können Kodes von dem/der Forschenden schnell hierarchisiert werden. [66]
5.1.3 Nur ein Link zwischen Kodes möglich
In ATLAS.ti können zwei Kodes nur auf der Basis einer Relation miteinander verbunden und so zueinander in Beziehung gesetzt werden. Es entstehen jedoch Situationen, in denen man sich wünscht, zwei oder auch mehr Beziehungen auszudrücken. Manchmal sind Beziehungen noch vorläufig und man möchte mit verschiedenen Varianten "experimentieren" oder eine Variante für die spätere Dokumentation "aufheben". [67]
Den skizzierten Nachteilen stehen zwei Aspekte gegenüber, die ich in den vorangegangenen Abschnitten ausgeführt habe und die ich hier noch einmal bündeln und vertiefen möchte, und zwar 1. das Gesamtkonzept der Datenorganisation und dass ein Kode 2. mit beliebig vielen anderen Kodes anhand einer Liste von Relationen in Beziehung26) gesetzt werden kann. Ich schließe mit einem 3. Aspekt, und zwar der Möglichkeit der maschinellen Weiternutzung der Ergebnisse einer Analyse. [68]
5.2.1 Gesamtkonzept der Datenorganisation
ATLAS.ti trennt zwischen der Speicherung der analytischen Arbeit (Speicherung der Inhalte) und der Darstellung der analytischen Arbeit (Darstellung der Inhalte). Die gesamte analytische Arbeit, d.h. die Ergebnisse des textnahen Kodierens, des Kategorisierens, des axialen und selektiven Kodierens, die Verweise auf das Datenmaterial27) und Memos werden in Objektelisten (z.B. Kodelisten, Quotationlisten) und auf der Grundlage der netzwerkartigen Datenstruktur gespeichert (z.B. die Kodierungen, Annotierungen und die Verknüpfung von Kodes), und es entsteht so ein zusammenhängendes Datennetz. Im HU-Editor und im Network-Editor werden die Inhalte erarbeitet. Sämtliche Arbeit an den Inhalten, z.B. die Aufnahme neuer Kodes oder neuer Zitate, Änderungen z.B. an Kodenamen oder Verbindungen zwischen Kodes oder das Löschen von Kodes oder Kodierungen findet in den jeweiligen Objektelisten und am Datennetz statt. Wird z.B. im Fortschreiten der Analyse für eine Kategorie eine Bezeichnung gefunden, die aussagekräftiger ist als die bisherige, dann wird der Kategorien-Kode von dem/der Forschenden nur einmal umbenannt. Diese Änderung wird in der Kodeliste gespeichert. Dies gilt auch für Beziehungen zwischen Kodes. Stellt man fest, dass z.B. nicht A der Grund für B, sondern B der Grund für A ist, so ändert der/die Forschende dies nur einmal, die Änderung wird im Datennetz festgehalten. Alle Darstellungen der Inhalte in Form von Ausgaben, z.B. Druckausgaben oder HTML-Ausgaben, oder in Form von Anzeigen am Bildschirm greifen auf die Objektelisten und auf das Datennetz zu, und der/die Forschende erhält den jeweils neuesten Stand der Analyse. Mit dieser Vorgehensweise, der Trennung von Speicherung und Darstellung der Inhalte, wie sie auch bei Content-Management-Systemen praktiziert wird, sorgt ATLAS.ti für die technische Konsistenz der Daten, was insbesondere bei (auch) induktiv arbeitenden Verfahren wie der GTM hilfreich ist. [69]
5.2.2 Semantische Beziehungen zwischen Konzepten
Wie in Abschnitt 4.1 ausgeführt, machen Inhalts- und Ausdrucksseite zusammen das sprachliche Zeichen aus und sind untrennbar miteinander verbunden. In ATLAS.ti können sowohl Kodes als auch Relationen so definiert werden, dass sie sprachlichen Zeichen (Begriffe) entsprechen. Der Name des Kodes und der Name der Relation stehen für die Ausdrucksseite der jeweiligen Konzepte, die entsprechenden Kommentarfelder, die es zu jedem ATLAS.ti-Objekt gibt (z.B. Zitate, Kodes, Links oder Relationen), stehen für die Inhaltsseite der Konzepte. In den Kommentarfeldern können die Konzepte definiert oder beschrieben werden. Einmal von dem/der Forschenden in dieser Weise festgelegt, werden Kodes (Konzepte des Untersuchungsfeldes) und Relationen (erkenntnisleitende Konzepte 28)) wie Wörterbucheinträge benutzt. Anhand der in der Relationenliste erfassten (erkenntnisleitenden) Konzepte können Zusammenhänge zwischen Konzepten des Untersuchungsbereichs kodiert werden, d.h., dass auch die Beziehungen zwischen Konzepten sprachlich, d.h. konzeptuell durch Begriffe repräsentiert werden. [70]
5.2.3 Maschinelle Nutzung von Forschungsdaten
Ein ATLAS.ti-Projekt kann umfassend im XML-Format29) ausgegeben werden. (MUHR 2000, Par.44). So hat der/die Forschende die Möglichkeit, anderen Programmen und anderen Forscher/innen sämtliche Forschungsinformationen, sowohl zum Datenmaterial als auch zu den Forschungsergebnissen, in maschinenlesbarer Form zur Verfügung zu stellen. Damit sind ATLAS.ti-Projekte anschlussfähig an aktuelle Open-Access-Initiativen30), und der/die Forschende verfügt über die technische Ressource (das ist hier die XML-Datei zum ATLAS.ti-Projekt), um die sich derzeit entwickelnde Infrastruktur für den freien Zugang zu Datenzu nutzen. [71]
Ein besonderes Augenmerk möchte ich auf die mögliche maschinelle Weiternutzung von Ergebnissen einer Analyse und damit auf die "Kode-Pyramide" (siehe Abschnitt 4.5) richten. Die "Kode-Pyramide" mit der Kernkategorie an der Spitze repräsentiert die entwickelte Grounded Theory als strukturierte Information, die als Ganzes maschinenlesbar ist. Durch die Art und Weise, wie Kodes und Relationen und die Verbindung der Kodes anhand dieser Relationen in ATLAS.ti gespeichert sind, und die damit verbundene konsequente Trennung von Inhalt und Darstellung können die Ergebnisse einer Analyse mit entsprechender Information versehen ausgegeben und von anderen Programmen "sinnvoll" weiterverarbeitet werden. "Sinnvoll" meint hier, dass andere Programme erkennen können, bei welchen Daten es sich um Kodes und damit um Konzepte des Untersuchungsfeldes und bei welchen Daten es sich um Relationen und damit um erkenntnisleitende Konzepte handelt, und welche Konzepte des Untersuchungsfeldes (Kodes) durch welche erkenntnisleitenden Konzepte (Relationen) miteinander verbunden sind. Die Möglichkeit, Ergebnisse weiterzunutzen, sei es, um sie zu prüfen (Qualitätssicherung), sei es, um darauf aufzubauen, sei es, um sie mit anderen Ergebnissen zusammenzuführen, ist ein ausbaufähiges Potenzial für die qualitative Forschung. [72]
6. Zusammenfassung und Ausblick
Drei Merkmale machen ATLAS.ti für Forschungsarbeiten unter Nutzung der GTM besonders interessant:
Konzepte können anhand von Kodes und anhand von Relationen erfasst werden. Mit Kodes werden Phänomene des Untersuchungsfeldes konzeptionalisiert, während erkenntnisleitende Konzepte mit Relationen erfasst werden. Beide können den Wörtern einer Sprache ähnlich definiert werden. Diese Konzeption ermöglicht, dass im Untersuchungsfeld gefundene Zusammenhänge begrifflich gefasst werden können. Zusätzlich unterstützt diese Konzeption Forschende darin, Konzepte des empirischen Feldes und erkenntnisleitende Konzepte auseinanderzuhalten.
ATLAS.ti trennt zwischen der Speicherung der Inhalte eines Forschungsprojektes und der Darstellung der Inhalte. Durch diese Trennung sorgt das Programm (technisch) für die Konsistenz der Inhalte, was insbesondere bei (auch) induktiv arbeitenden Methoden unterstützend ist.
Ein ATLAS.ti-Projekt kann im XML-Format ausgegeben werden. Dadurch können sämtliche Forschungsinformationen, sowohl Datenmaterial als auch Ergebnisse, anderen Forscher/innen maschinenlesbar zur Verfügung gestellt werden. Für Methoden, deren Ziel die Entwicklung von Theorien ist, ist die Möglichkeit, Forschungsergebnisse zur Verfügung zu stellen oder umgekehrt, Ergebnisse anderer Forschungsarbeiten in maschinenlesbarer Form zu erhalten, ein Gewinn, da es die Möglichkeiten der Qualitätssicherung von Ergebnissen, der Nutzung von Wissen und der Kooperation erweitert. [73]
Auch wenn die maschinelle Weiterverwendung von Ergebnissen (noch) nicht zum Alltag qualitativ Forschender gehört, ist sie doch bereits jetzt ein wichtiges Potenzial computerunterstützter qualitativer Datenanalyse und könnte zu einem relevanten Teilgebiet im Themenfeld "Open Access zu Daten" werden. Über dieses Potenzial zu reflektieren, kann die Diskussion um die computerunterstützte qualitative Analyse innerhalb der Community erweitern und den Blick für IT-Disziplinen öffnen, die sich mit digitalem Wissensmanagement und Wissensrepräsentationen auseinandersetzen (BENJAMIN et al. 1994; NOY & McGUINESS 2001). Gemeinsame Themen zu erkennen eröffnet die Möglichkeit, sowohl von diesem sich rasant entwickelnden IT-Feld zu profitieren als auch Wissen in dieses Feld hinein zu tragen. Die wünschenswerte Debatte zwischen Methodiker/innen und CAQDAS-Entwickler/innen kann über die Weiterentwicklung von CAQDAS-Produkten hinausgehen und Gemeinsamkeiten zwischen qualitativ Forschenden und IT-Spezialist/innen, die sich traditionell eher fremd sind, sichtbar werden lassen. [74]
1) Computer Assisted Qualitative Data Analysis Software (CAQDAS) <zurück>
2) Alle Ausführungen beziehen sich auf ATLAS.ti 6.0. <zurück>
3) Open Access zu Daten: freier Zugang zu Forschungsdaten. <zurück>
4) "Daten" meint hier nicht das Datenmaterial des Anwenders/der Anwenderin, sondern alles, was gespeichert werden muss: das Datenmaterial, die Zitate, die Kodes und vieles mehr. <zurück>
5) Ein primary doc in ATLAS.ti verweist auf die Datei, in der ein Text oder Bild, kurz ein zu analysierendes Dokument, abgespeichert ist, d.h. das primary doc enthält nicht das Datenmaterial selbst, sondern den Zugriffsort und Namen des Dokumentes. Zur Organisation des Datenmaterials in ATLAS.ti siehe MUHR und FRIESE (2003-2004). <zurück>
6) Eine quotation in ATLAS.ti verweist auf das Zitat im Datenmaterial, d.h. die quotation enthält nicht das Zitat selbst, sondern die Information, wo im Datenmaterial ein Zitat beginnt und wo es endet. <zurück>
7) Als einen ersten Zugang stelle ich hier nicht alle Möglichkeiten der Vernetzung vor, sondern beschränke mich auf die Vernetzung der sogenannten main objects. <zurück>
8) Das gleiche gilt für einen Link zwischen zwei quotations. Die Funktion von qualifizierten Links zwischen quotations ist nicht Thema dieses Beitrags. <zurück>
9) Das Kürzel HU steht für "Hermeneutische Einheit". <zurück>
10) Der bilaterale Zeichenbegriff ist m.E. gut geeignet, um die Beziehung zwischen den oben genannten Begriffen zu bestimmen. <zurück>
11) Bei den Zahlen direkt oberhalb der Zitate handelt es sich um sogenannte "Zitat-Identifier", die vom Programm automatisch vergeben werden. Aus dem Identifier geht hervor, aus welchem Primärdokument das Zitat stammt und das wievielte Zitat es ist. <zurück>
12) In ATLAS.ti kommen die Begriffe Kategorie bzw. Kategorien-Kode nicht vor. Konzepten, ob spezifisch oder generell, werden Kodes zugeordnet. In ATLAS.ti werden Kodes als abstract codes bezeichnet, wenn sie mit keiner quotation (Zitat) verbunden sind. So sind Kategorien-Kodes häufig abstract codes und zwar dann, wenn sie nicht zum textnahen Kodieren verwendet werden. Sobald man einer Textstelle einen Kategorien-Kode zuordnet, gehört er in ATLAS.ti nicht mehr zur Gruppe der abstract codes. <zurück>
13) Relationen, die untergeordnete Begriffe mit übergeordneten Begriffen verbinden, wie z.B. die Unterbegriff-Oberbegriff-Relation oder Teile-Ganzes-Relationen wie "Komponente von", "Mitglied von" "gehört-zu" u.ä., fasse ich unter dem Sammelbegriff "hierarchische Relationen" zusammen. <zurück>
14) Eine code family in ATLAS.ti darf nicht mit den von GLASER (1978) vorgeschlagenen code families gleichgesetzt werden: Das Familien-Konzept von ATLAS.ti ist ein Programmkonzept, d.h. ein technisches Instrument zur Bündelung von main objects, z.B. auch der Bündelung von Kodes. So können beliebige Kodes nach Maßgabe des/der Forschenden zu code families gebündelt werden. Die von GLASER (1978) vorgeschlagenen code families sind dagegen eine thematische Zusammenstellung spezifischer formaler und inhaltlicher Konzepte auf hohem Generalisierungsniveau, die eine von ihm intendierte spezifische Funktion erfüllen, nämlich das theoretische Kodieren anzuleiten (MEY & MRUCK 2007, S.26). Ein Teil dieser Konzepte, z.B. Elemente der C-Familie, werden in ATLAS.ti eher nicht mit Kodes, sondern durch Relationen repräsentiert (siehe dazu Abschnitt 4.3). <zurück>
15) Hier kommt das ATLAS.ti Query Tool zum Einsatz. Näheres dazu siehe bei MUHR und FRIESE (2003-2004). <zurück>
16) Dem axialen Kodieren bei STRAUSS ähnlich ist das "theoretische Kodieren" bei GLASER. GLASER hat eine Liste soziologischer und erkenntnistheoretischer Konzepte in code families zusammengestellt, die das theoretische Kodieren leiten sollen (MEY & MRUCK 2007, S.26). <zurück>
17) CORBIN und STRAUSS bezeichnen in "Basics of Qualitative Research" (2008) jede Art von Konzeptverknüpfung als "axiales Kodieren", auch die Verknüpfung von spezifischeren Konzepten mit einem generelleren Konzept (Kategorie) im Zuge des offenen Kodierens. Ich verwende hier den Begriff "axiales Kodieren" ausschließlich für die Erarbeitung der Beziehung zwischen den im Zuge des offenen Kodierens erarbeiteten Konzepten. <zurück>
18) Da das axiale Kodieren auf jeder Generalisierungsstufe durchgeführt werden kann, verwende ich in diesem Abschnitt den Begriff "Konzept" stellvertretend für "Kategorie" (generelles Konzept) und "textnahe Kodes" (spezifischere Konzepte). <zurück>
19) Das sind die Hauptfragen, die eine Untersuchung leiten. Sie leiten sich aus dem Erkenntnisinteresse einer wissenschaftlichen Disziplin ab und sind gebunden an den jeweiligen auch wissenschaftstheoretischen Hintergrund. <zurück>
20) Jede Sprache verfügt über Mittel, mit denen Zusammenhänge zwischen den Dingen ausgedrückt werden können (wenn A vorliegt, dann kann auch B ... / weil A passiert ist, muss jetzt B ... / obwohl A vorlag, hat B ...). Sämtliche Konjunktionen einer Sprache weisen auf allgemeine Zusammenhangskonzepte hin. Darüber hinaus gibt es eine Vielzahl von theoretischen Konzepten, bei denen es sich implizit um Zusammenhangskonzepte handelt. Der Ressourcenbegriff beispielsweise impliziert ein "Wofür". Er konzeptualisiert den Zusammenhang zwischen einem Mittel und einem Ziel, z.B. Geld ist Ressource für Lebensgestaltung. Schlussendlich können Konzepte relational verwendet werden, z.B. "Das Kind fährt Fahrrad". Hier verbindet das Konzept "fahren" "Kind" mit "Fahrrad". <zurück>
21) In die Umsetzung des axialen Kodierens mit ATLAS.ti einführend wird hier bewusst kein Beispiel unseres Forschungsprojektes, sondern ein bekanntes Beispiel aus der Literatur gewählt. <zurück>
22) Die Relationenliste enthält voreingestellte Relationen: Eine Oberbegriff-Unterbegriff-Relation wird beispielsweise mit is-a, eine Ganzes-Teile-Relation mit is-part-of oder eine Ursache-Wirkungs-Relation mit is-cause-of repräsentiert. Beliebig viele "eigene" Relationen zur Repräsentation von Beziehungen zwischen Konzepten können von dem/der Forschenden ergänzt werden. <zurück>
23) Auf die Trennung zwischen Speicherung von Informationen, z.B. der axialen Kodierung und Visualisierung der Information, wird in Abschnitt 5.2.1 näher eingegangen. <zurück>
24) Zur Kode-Notation. Haben wir eine Kategorie dimensionalisiert, so wählen wir als Kodenamen für die Untertypen den Kategorienname, gefolgt von einem Punkt und einer Typisierung, z.B."besser leben. anders leben". <zurück>
25) Kodes erscheinen in einer Kodeliste hintereinander, wenn sie beispielsweise denselben Präfix haben: E_ Emotion, E_Freude, E_Trauer, E_ usw. <zurück>
26) Zur Begrifflichkeit "Beziehung zwischen Konzepten (Kodes)" siehe Abschnitt 2.2. <zurück>
27) "Daten" meint hier nicht das Datenmaterial des/der Anwender/in, sondern alles, was gespeichert werden muss: das Datenmaterial, die Zitate, die Kodes und vieles mehr. <zurück>
28) Zum Begriff "erkenntnisleitende Fragen" siehe Abschnitt 4.3 Es handelt sich um die Hauptfragen, die eine Untersuchung leiten. Sie leiten sich aus dem Erkenntnisinteresse einer wissenschaftlichen Disziplin ab und sind gebunden an den jeweiligen auch wissenschaftstheoretischen Hintergrund. <zurück>
29) XML ist ein Standard zum Informationsaustausch zwischen Computeranwendungen. <zurück>
30) Siehe bereits früh die Budapest Open Access Initiative. <zurück>
Benjamin, Perakath, C..; Menzel, Christopher P.; Mayer, Richard J.; Fillion, Florence; Futrell, Michael T.; deWitte, Paula S. & Lingineni, Madhavi (1994). Information integration for concurrent engineering. IDEF5 Method Report, http://www.idef.com/IDEF5.htm [Zugriff: 11.11.2010].
Bergenholtz, Henning & Mugdan, Joachim (1979). Einführung in die Morphologie. Stuttgart: Kohlhammer.
Böhm, Andreas; Legewie, Heiner & Muhr, Thomas (2008 [1992]). Kursus Textinterpretation: Grounded Theory, http://www.ssoar.info/ssoar/View/?resid=2662 [Zugriff: 22.12.2010].
Bosch, Reinoud & Mühlmeyer-Mentzel, Agnes (2010). Het code-managementsysteem bij kwalitatieve data-analysesoftware. KWALON, 15(3), 54-60.
Corbin, Juliet M. & Strauss, Anselm L. (2008). Basics of qualitative research (3. Aufl.). Thousand Oaks, CA: Sage.
Glaser, Barney G. (1978). Theoretical sensitivity: Advances in the methodology of grounded theory. Mill Valley, CA: Sociology Press.
Hobfoll, Stefan (2001). The influence of culture, community, and the nested-self in the stress process: Advancing conservation of resources theory. Applied Psychology: An International Review, 50(3), 337-421.
Lewins, Ann & Silver, Christina (2007). Using software in qualitative research: A step-by-step guide. London: Sage.
Mey, Günter & Mruck, Katja (2007). Grounded Theory Methodologie – Bemerkungen zu einem prominenten Forschungsstil. In Günter Mey & Katja Mruck (Hrsg.), Grounded Theory Reader (S.11-42). Köln: Zentrum für Historische Sozialforschung.
Muhr, Thomas (1991). ATLAS/ti – A prototype for the support of text interpretation. Qualitative Sociology, 14(4), 349-371.
Muhr, Thomas (2000). Increasing the reusability of qualitative data with XML. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 20, http://nbn-resolving.de/urn:nbn:de:0114-fqs0003202 [Zugriff: 22.12.2010].
Muhr, Thomas & Friese, Susanne (2003-4). Users manual for ATLAS.ti 5.0 (2.Aufl). Berlin: Scientific Software Development.
Noy, Nataly F. & McGuinness, Deborah L. (2001). Ontology development 101: A quide to creating your first ontology. Stanford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880, http://www.ksl.stanford.edu/people/dlm/papers/ontology-tutorial-noy-mcguinness-abstract.html [Zugriff: 15.1.2011].
Saussure, Ferdinand de (1967 [1931]). Grundfragen der allgemeinen Sprachwissenschaft. Berlin: de Gruyter.
Strauss, Anselm (1991). Grundlagen qualitativer Sozialforschung. Weinheim: Wilhelm Fink Verlag.
Strauss, Anselm L. & Corbin, Juliet M. (1996). Grounded Theory: Grundlagen qualitativer Sozialforschung. Weinheim: Beltz.
Strübing, Jörg (2004). Grounded Theory. Zur sozialtheoretischen und epistemologischen Fundierung des Verfahrens der empirisch begründeten Theoriebildung. Wiesbaden: Verlag für Sozialwissenschaften.
Strübing, Jörg (2007). Glaser vs. Strauss? Zur methodologischen und methodischen Substanz einer Unterscheidung zweier Varianten von Grounded Theory. In Günter Mey & Katja Mruck (Hrsg.), Grounded Theory Reader (S.57-173). Köln: Zentrum für Historische Sozialforschung.
Agnes MÜHLMEYER-MENTZEL, Dr. phil, Dipl. Inf. ist wissenschaftliche Mitarbeiterin im Arbeitsbereich Klinische Psychologie und Psychotherapie an der Freien Universität Berlin. Ihre Arbeitsschwerpunkte sind: Grounded-Theory-Methodologie aus der Perspektive von Wissensrepräsentation; Computergestütztes qualitatives Forschen; Support bei GTM-Qualifizierungsarbeiten, Schulungen und Support zur qualitativen Analyse-Software ATLAS.ti
Kontakt:
Agnes Mühlmeyer-Mentzel
Freie Universität Berlin
Arbeitsbereich Klinische Psychologie und Psychotherapie
Habelschwerdter Allee 45
D-14195 Berlin
Tel.: +49 (0)30 838 55723
E-Mail: muehlmey@zedat.fu-berlin.de
URL: http://www.ewi-psy.fu-berlin.de/einrichtungen/arbeitsbereiche/klinische_psychotherapie/auckenthaler/mitarbeiter/agnes/
Mühlmeyer-Mentzel, Agnes (2011). Das Datenkonzept von ATLAS.ti und sein Gewinn für "Grounded-Theory"-Forschungsarbeiten [74 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 32, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101325.

Creative Commons Attribution 4.0 International License