Volume 12, No. 1, Art. 39 – January 2011
Using ATLAS.ti for Analyzing the Financial Crisis Data
Susanne Friese
Abstract: This article is part of a larger experiment where developers of CAQDAS (Computer Assisted Qualitative Data AnalysiS) packages, or those cooperating very close with them, analyzed data based on a common data set. The aim was to find out whether the use of software influences the ways we analyze data and if so how. My argument is that software has a greater influence when users lack methodological know-how. The greater the methodological expertise and confidence in using a certain methodology in the context of software, the lesser is the influence of software. Therefore the focus of my paper is on the methodological approach that I am using when analyzing qualitative data (see FRIESE, 2011). After outlining this approach, I illustrate how I have applied it in analyzing the financial crisis data with ATLAS.ti.
Key words: computer assisted NCT analysis; ATLAS.ti; methods of computer-assisted qualitative data analysis; coding; CAQDAS; influence of software
Table of Contents
1. Introduction and Underlying Assumptions
2. Outlining the Method of Computer-Assisted NCT Analysis
2.1 Noticing and collecting things
2.2 Thinking and some more noticing and collecting: Adding structure to the code list
2.3 Thinking about things
3. Analyzing the Financial Crisis Data
3.1 Approaching analysis
3.2 Limitations
3.3 Sampling
3.4 Noticing and collecting
3.5 Thinking and some more noticing and collecting: Developing sub categories
3.6 Doing some more collecting: Developing higher order codes
3.7 Thinking about things: Further data analysis
4. Results
4.1 Did views or arguments about the cause and prognosis of the economic crisis change between 2008 and 2009? (RQ1)
4.2 How do different actors identify the causes of the economic crisis? (RQ2)
4.3 How do different actors predict the future consequences of the economic crisis? (RQ3)
4.4 How do different actors justify their positions?
4.5 Pulling it all together
5. Reflection on the Influence of Software on Qualitative Data Analysis
1. Introduction and Underlying Assumptions
As part of an experiment for the KWALON conference in Utrecht in April 2010, I was asked to embark on a journey analyzing data about the financial crisis using ATLAS.ti as my tool. The aim of this experiment was to find out which role software plays in the ways users go about analysis. Would we all find more or less the same results or would software lead us in a particular way producing different results? [1]
At first I would like to position myself, so that the reader can better evaluate where I am coming from and why I work the way I work. I began to develop my analytic skills as a qualitative researcher by being introduced to social constructivism during my Master studies and by reading the book "Basics of Qualitative Research" by STRAUSS and CORBIN (1990). At about the same time, I began to work with John SEIDEL, a sociologist and developer of the first commercially available CAQDAS package THE ETHNOGRAPH. Apart from my first project, i.e. my Master thesis, I always used software for analyzing qualitative data. Thus, my way of going about analysis is influenced by the set of analytic procedures described in the various books on grounded theory and by using software as a tool. However, I am not a grounded theorist per se. Rather I have been developing my own method of analysis because most methods—including grounded theory—have been developed before the event of CAQDAS. The newer editions of qualitative data analysis books often do include a section on software, but this is an add-on rather than a description of a computer-assisted method for qualitative data analysis. The third edition of the Basics of Qualitative Research book for example shows screen shoots on how MAXQDA can be used to support the analysis process, but it does not present an integrated computer-assisted approach (CORBIN & STRAUSS, 2008). [2]
I was first trained in quantitative research methods and this, paired with personal characteristics, led me to strive for going about analysis in a systematic manner. Therefore, my aim always was to make qualitative data analysis more systematic and more transparent. Looking back, I was not successful in doing so all the time. Today I use my own dissertation research as an example for how not to do it. It took me quite a number of years, analyzing a number of projects on my own or in teams, and by serving as a consultant on many more projects to develop software-supported analytic procedures that present a systematic way of going about analysis. [3]
I started this experiment with the attitude that software does not have an influence on the analysis process assuming the application of similar packages. My claim is: One has to know ones method and the software and then apply the method within the possibilities the software provides. In support of my argument that methodological knowledge should exist before embarking on using a software package, I outline the basic steps of my analytic approach, which I labeled "Computer-assisted NCT analysis," before I describe the actual analysis that I have conducted using ATLAS.ti as a tool. For a more detailed description of the method, see FRIESE (2011). I end the paper with some reflections on the above stated claim on the influence of software. [4]
2. Outlining the Method of Computer-Assisted NCT Analysis
At first sight, the analysis method1) I am proposing looks simple. It is however this simplicity that makes it so attractive. The basic steps can be understood very easily. It enables novices to work in a systematic manner instead of declaring software to be the method. With more experience, the cyclical nature of the basic steps becomes apparent and one learns to apply the method in a more sophisticated manner. In this paper, I explain the application of the method within the context of ATLAS.ti. However, the method can also be used when analyzing data with other software packages. [5]
When reading through the next couple of pages, you will notice that I am not reinventing the wheel. At times I draw on basic methodological principles that have been described for manual method of data analysis. The implementation of these principles, however, is different when using software. Using CAQDAS, analysis can be approached in a different manner because 1. there is more flexibility in modifying code names and coded data segments and thus coding can be approached in a different way, 2. software offers many more analysis options and thus allows researchers to ask different questions, 3. it makes it easier to combine qualitative and quantitative methods, which of course does not preclude a pure qualitative approach, 4. it allows researchers to work in teams even across geographical boundaries, and 5.) it allows qualitative researchers to move out of the black box of analysis and to make the entire analysis process more transparent, thus adding credibility, confirmability and dependability. Credibility involves establishing that the results of qualitative research are credible or believable from the perspective of the participant in the research. The criterion confirmability replaces the conventional criterion of neutrality and objectivity and refers to the degree to which the results can be confirmed or corroborated by others. This can be achieved by documenting the research process, the decisions made during a project and by the presentation of the end product. Dependability substitutes consistency or reliability, which can be for example achieved by a procedure called auditing (LINCOLN & GUBA, 1985; SEALE, 1999). This list is not exhaustive, but points out the major differences from my perspective. [6]
The model underlying the method is originally based on a paper by SEIDEL (1998). I was introduced to the model in 1992 and since then I continuously developed it further. The three basic components of the analysis process are Noticing things, Collecting things and Thinking about things, and hence the name: Computer-assisted NCT analysis. [7]
2.1 Noticing and collecting things
Noticing and collecting are two different yet related processes. There is no collecting without noticing, but often collecting immediately follows noticing. Depending on the analyst, there might be variations. Some may first go through some of the data or the entire data set on paper, mark data segments and scribble down notes; others may immediately sit in front of a computer screen, notice some interesting things in the data and begin to code. Both ways are encompassed by the method. [8]
Noticing refers to the process of finding interesting things in the data when reading through transcripts, field notes, documents or newspaper articles, viewing video material or images, or when listening to audio files. In order to capture this, the researcher may write down notes, mark the segments or attach first preliminary codes. Codes may be derived inductively or deductively. The term code, as I use it, is a technical device provided by the software. The software cannot distinguish between different levels of codes. Thus a code at some point needs to be turned into a methodological device2) by the researcher and it is the researcher that turns a code into a category or a sub category or a dimension by way of naming it in a specific way and by defining it. At this point, the level of a code does not play a role. It may be descriptive or already conceptual. What is important, is that one marks those things that are interesting in the data and names them. In the next section I will name several coding strategies fit for this stage, mentioned in methodological literature. [9]
Reading further, the researcher is likely to come across data segments that are similar to others that he or she has noticed before. The segments may even fit under an already existing code label. This is when the process of collecting data segments under a common code name starts. If a similar issue does not quite fit under the same heading, one can rename the code or subsume two codes. Even if the term is not yet the perfect code label, it does not matter. When continuing to collect more similar data segments and reviewing them later, it becomes easier to think of better, more fitting code labels that cover the substance of the material that has been collected. [10]
The focus of this initial process of noticing and collecting can be manifold, depending on the underlying research questions and research aim. To name just a few of the various procedures, described in the literature3), which can be used during this stage: descriptive or topic coding (MILES & HUBERMAN, 1994; SALDAÑA, 2003; TESCH, 1990; WOLCOTT, 1994), process coding (BOGDAN & BIKLEN, 2007; CHARMAZ, 2002; CORBIN & STRAUSS, 2008), initial or open coding (CHARMAZ, 2006; CORBIN & STRAUSS, 2008; GLASER, 1978), emotion coding (GOLEMAN, 1995; PRUS, 1996), values coding (GABLE & WOLF, 1993; LeCOMPTE & PREISSLE, 1993, narrative coding (CORTAZZI, 1993; RIESSMAN, 2008) or provisional coding (DEY, 1993; MILES & HUBERMAN, 1994). [11]
The NCT analysis method encompasses the various ways of coding and suggests computer-assisted procedures for how to deal with them. Researchers may choose to follow just one of the suggested procedures or combine them in an eclectic way. The things you collect in your data may be themes, emotions and values at the same time. You may approach the process with a deductive framework in mind as used in provisional coding (DEY, 1993; MILES & HUBERMAN, 1994); or you may develop codes inductively as suggested by initial or open coding (CHARMAZ, 2006; CORBIN & STRAUSS, 2008; GLASER, 1978); or use a mix of deductively and inductively developed codes. Some researchers develop 40 codes, others a few hundred or even a few thousand codes. The NCT method of analysis provides answers for what to do with your codes within a software environment. Often there is lack of methodological understanding of what a code is. The software does not explain it; it just offers functions to create new codes, to delete, to rename or to merge them. The metaphor of collecting helps novice researchers to better understand that a properly developed code is more than just a descriptive label for a data segment and that it does not make sense to attach a new label to everything that one notices. Developing a lot of codes is clearly an adverse effect of using software. No one would ever come close to 1000 or more codes when using the old-style paper & pencil technique. But also when using software, too many codes lead to a dead end. There might be exceptions, but in most cases this hinders further analysis. [12]
This is the next step in the analysis process after the first phase of noticing & collecting. [13]
2.2 Thinking and some more noticing and collecting: Adding structure to the code list
When the researcher no longer notices new things, no new codes are added, and the analyst only applies already existing codes, the point of thinking about the code structure has arrived. A first point of saturation4) has been reached. As a rule of thumb, in an interview study, this point is reached after three to five interviews, depending on the length and diversity of the data. In coding shorter texts like newspaper articles, around 20 to 30 articles need to be coded to get to this point. These are just approximate numbers depending on the type and length of data, the diversity within it and across the sample. The researcher needs to develop a feeling for this first point of saturation as a matter of experience over time. A good indicator for this first point of saturation is when mostly already existing codes are applied. [14]
Depending on the focus of coding, analytical style and individual ways of thinking, some researchers may end up with 70 or 100 or even a few hundred codes after this first phase of noticing and collecting. At this stage I do not want to restrict anyone. Coding should be done in whatever way works best for the coder and in relation to the data and the research goal. The label at this point for most codes is not yet the final label. What needs to be done at this stage is to add more structure to the code list. This means to develop more abstract conceptual level codes and to order and (re)develop codes into categories and sub categories. [15]
As a rule of thumb5), CHARMAZ (2006, p.57) also mentions frequencies for deciding what might be a candidate for a category code. Evaluating numbers however need to occur within the context of the data, reading and reviewing them. The decision about which code might be developed into a higher or lower order code, i.e., category or sub category, is still made by the researcher and not by numbers produced by the software. [16]
Code labels that have been applied quite a number of times apparently show the ability to collect a number of similar items under its heading. Often these are candidates for developing sub categories, based on the content coded within them. Here the process of noticing and collecting is repeated within the smaller cosmos of the code. The researcher reviews the segments coded at this code (and those using software know how easy it is to do so) and the process of noticing sets in once again. This time the focus is on similar data segments within the code, which then can be collected under a new code label as a sub category code. This process continues until all data segments of codes with high frequency counts have been reviewed. Whatever cannot be determined at this point remains coded at the main category code. [17]
Next, one looks for code labels that have only been used a few times. These codes are likely to be descriptive and thus refer to specific data segments but do not have the ability to unite a lot of data segments. Such codes are candidates for a closer examination to either merge them with similar codes under a higher order conceptual label, or to evaluate whether they already present sub categories, which can then be collected under a new common category label. Noticing and collecting thus also plays a role when developing codes on an aggregate level. [18]
The aim of the above outlined process of developing categories and sub categories is to add structure to the previously loose list of codes, forcing the researcher to rethink the initial codes and to further develop them conceptually. This avoids drowning into what I call the code swamp, i.e., creating too many codes that look like codes in the software but have not yet reached methodological status. [19]
For the software a code is just an object, for the analyst it is a handle to open little containers that contain data. Creating too many containers that only hold a few items or too few that hold a flood of information both create analytic problems in the long run. Hitting the right level and knowing when a code is a proper code, thus has reached methodological status, is a matter of experience. You become better at it with every project you analyze. This is independent of software and I don't think that software has either a positive or negative influence on learning how to develop a code methodologically. The analyst needs to come up with the right ideas and labels. Software only facilitates the process of handling the data, creating and applying codes, renaming and modifying them.6) But it does not teach you about good and bad labels and when or when not to apply a code (see also LEWINS & SILVER, 2007). [20]
After the structured code list has been developed, the researcher continues with coding the remaining, or newly collected data. This second phase of coding serves as a way to validate the code list. If the code list has been developed well, very few new codes will be added at this stage. If the coder has problems applying the codes to additional data, the noticing and collecting process needs to be continued. A code list probably never reaches 100% perfection, small modifications like refining a code label or adding more sub categories to already existing category codes are normal occurrences. The purpose of the code list for an NCT analysis is to be able to access the data in a systematic manner. A well-developed NCT code list describes what is in the data. It does not necessarily represent a theoretical framework or the elements of a theory. This is only the case, if it has been the outset to do so. If theory development is the aim, then this occurs when writing memos using the codes as devices to query and access the data content. [21]
At some point all data is coded and the analyst enters the next analysis phase. Until now, he or she was immersed in the data. The aim of the next phase is to look at the data again, and specifically from the perspective of the research questions. This is like stepping aside, taking a different point of view by approaching the data from a different angle. This means asking questions using the various analysis tools software provides. Accompanying the process of querying is writing what I call research question memos. [22]
Writing memos is useful throughout the entire process of analysis and different types of memos can be attributed to different phases of the analysis process. However, I often come across projects where the memo function provided by software is used very little or not at all. Often the memo function is misused as a comment function and users drown in a large number of "memos" that really are not memos (see for example CORBIN & STRAUSS, 2008; DEY, 1993; GIBBS, 2005; MORSE, 1994; OKELEY, 1994). This does not mean that software users never write memos, but many do so in a word processor. This is a pity, because then they are a step away from the data and miss out on the opportunity of linking memos to data, see LEWINS and SILVER (2007). [23]
Within the context of a software package, I make a clear distinction between comments/annotations and memos. The danger of writing in the context of software is that you write bits and pieces all over the place. You notice something and you write it down wherever the software provides an editor window for it. What is often forgotten is the process of collecting. Frequently, memos in software do not even have a proper title. Therefore, I suggest creating a number of memos at the beginning of the analysis by thinking about issues one wants to write about like the research process, to-do's, ideas for further analysis, issues related to the coding schema or the research questions one wants to find answers for. And throughout the analysis process one collects everything that fits under a certain theme within the memo. Further memos are likely to be added during the analysis process if other issues are noticed and one wants to collect them under a common theme in form of writing (for a more detailed explanation see FRIESE, 2011). [24]
When writing research question memos, I borrow from standard procedures on how to write up quantitative research findings. Instead of a hypothesis, I begin the memo by typing the research question to be examined. This may be a research question that was already known at the beginning of the project or may be one that was developed during the process of analysis. The next step is to think about how an answer to this question can be found, based on the coded data. In order to make this thinking process transparent, the query should be written down. This can be a simple retrieval based on one code, a retrieval based on code combinations, a cross-tabulation of codes, code queries combined with variables and the like. The purpose of this is to tell fellow researchers and other interested parties what was done so that they can evaluate the quality of the results and the research project as a whole. Qualitative data analysis procedures often remain opaque. Writing a short entry into a memo about which codes were queried does not take much time but adds a lot to the transparency of the research process. [25]
Next, the analyst runs the analysis, reads or looks through the data and writes down his or her thoughts and interpretation. While reviewing the data and writing about them, the analyst is likely to come across data segments that illustrate very nicely the interpretation written up in the memo. The memo can then be linked to these data segments and later retrieved as quotes for the research report. The content of a research question memo may begin at a descriptive level but over time and with further analysis it is likely to become more conceptual and theoretical. [26]
The aim of writing research question memos might be straight forward, such as finding answers to questions, or more elaborate, like finding patterns and relations in the data seeking to find out how the various aspects of the findings can be integrated. The goal is to develop a comprehensive picture of the phenomenon studied. When beginning to see how it all fits together, the visualization tools such as the network view function in ATLAS.ti, or modelers and maps in other programs, can be used. The visual depictions assist in further exploration of data, though in a different way. It can also be used as a means of talking with others about a particular finding or about an idea to be developed. Thus, throughout the research process, a number of diagrams like network views maybe drawn, redrawn, deleted and newly created. [27]
3. Analyzing the Financial Crisis Data
For this experiment, I started with the data without prior literature search or knowledge in the area of banking and finance. Thus, an inductive approach was used. With a background in consumer economics, I have some basic knowledge on economic systems and economic theory. However, I have no overview of current academic discussions, research papers and the like about the financial crisis. [28]
The data set consisted of a large number of HTML, PDF, audio and video documents extracted from the Internet in June 2008 and June 2009. The common theme was "reports on and around the financial crisis." Being faced with this somewhat overwhelming data set and due to time constraints, I only used a sub set of the provided documents (see the section on sampling below). This, however, does limit the explanatory power of this experiment. My conviction is that it would have been better for the sake of this experiment to provide a smaller data set, allowing fewer choices and requiring all of us to analyze exactly the same documents. [29]
Another limitation in terms of comparing the findings, as I see it, is the different backgrounds we bring to the data set. We enter this experiment with different methodological know-how and different backgrounds. The financial sector is, for example, not my area of expertise. As an economist, I probably would have developed different codes or emphasized different issues. I approached the data as a social scientist with nearly 20 years of experience in qualitative computing. [30]
My first step was to select a sub set of data that was provided. My selection criteria were as follows:
data from the two years 2008 and 2009,
data from various countries (US, UK and Germany),
different media types7) (HTML files converted to rich text format [RTF] or PDF, audio and video files). [31]
The purpose of this selection was on the one hand to be able to compare the views and arguments over time and across countries and media types. On the other hand, I wanted to show how ATLAS.ti can be used to analyze such data. The sample consisted of 11 documents (see the Appendix):
|
Criteria |
Group |
Number |
|
Year |
2008 |
5 |
|
|
2009 |
6 |
|
Country |
Germany |
3 |
|
|
UK |
4 |
|
|
UK global |
2 |
|
|
USA |
2 |
|
Media |
RTF |
1 |
|
|
|
7 |
|
|
audio |
1 |
|
|
video |
2 |
Table 1: Sample and sampling criteria [32]
In ATLAS.ti, the documents that have been added to a project can be viewed in a window called the primary document manager. In order to be able to compare and contrast in ATLAS.ti various groups of documentssuch as articles from the different countries and years, so called primary document families are created. The primary document families function like dichotomous variables (see Figure 1). The labels are written in a specific syntax that turns families into nominal variables when exporting them as Excel table. For instance, all families starting with "country::" are turned into one variable called country with the characteristics Germany, UK, UK global and USA.

Figure 1: Document manager in ATLAS.ti and variable view (enlarge this figure here) [33]
After assigning the data to ATLAS.ti and reading them, I began with the process of noticing and collecting. For this particular project, I used descriptive and initial coding (MILES & HUBERMANN, 1994; SALDAÑA, 2009; TESCH, 1990). This means I developed codes inductively and very close to the data. The code labels were still very descriptive or even taken directly from the data. When using a code word that matches the text, most software packages provide an option that is called "code in-vivo." When using a computer-assisted approach, it is mostly just that—using a range of characters that occur in the text as a code label. This is not the same as the meaning of an in-vivo code as implied by grounded theory, and I would not even call it a proper code. It is just a technical device that needs to be developed further into a code, most likely being renamed during this process. One has to be very careful in equating the terminologies used by CAQDAS with specific methodological approaches. ATLAS.ti uses for example the menu label "open coding." The term open coding is generally linked to grounded theory and is defined as: "Breaking data apart and delineating concepts to stand for blocks of raw data. At the same time one is qualifying those concepts in terms of their properties and dimensions" (CORBIN & STRAUSS, 2008, p.195 In ATLAS.ti, though, the menu label "open coding" simply means creating a new code. This process of descriptive and initial coding resulted in 78 codes (see Figure 2).8)

Figure 2: Code list after the first phase of coding (enlarge this figure here) [34]
3.5 Thinking and some more noticing and collecting: Developing sub categories
The numbers behind the codes in ATLAS.ti indicate the frequency and the linkages to other codes. "Consequences of financial crisis (26-0)" means that I used this code 26 times for coding and it is not yet linked to other codes. A few codes in the list show high frequencies indicating that I have collected quite a number of quotations under these code labels. Therefore they are good candidates for a closer examination in order to develop sub categories. Below I demonstrate this process using the code "consequences of financial crisis." [35]
To review the coded segments, one double clicks on a code in the Code Manager, this window lists all codes. By going through and reading the coded segments, I realized that the mentioned consequences can be divided into various aspects like economic, financial, governmental and political issues and I began to develop sub codes. This meant adding new empty codes to the list. As the code list in ATLAS.ti is sorted in alphabetic order, it is best to work with prefixes so that all codes belonging to a category show up as a group. In addition, I renamed the initial code "consequences of financial crisis" to "CO_CONSEQUENCES,"9) in order for it to appear as main category label on top. I prefer using capital letters for main category codes as visual aid. In addition I use the code color option to give all codes belonging to one category a uniform tint.
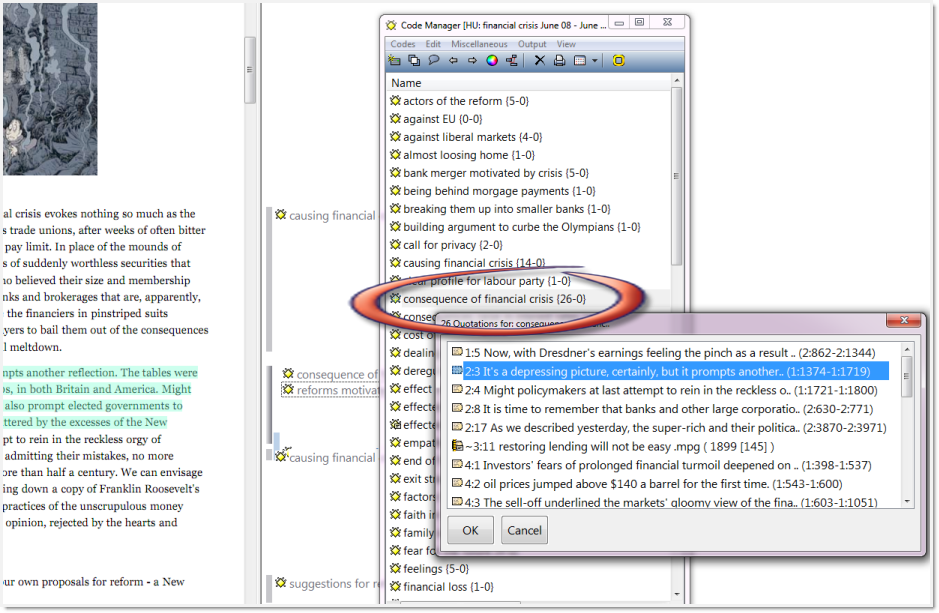
Figure 3: Building sub categories (enlarge this figure here) [36]
Next, I went through the data, adding content to the sub category codes. In the interest of on-screen space, I replaced the main category code with the fitting sub category code. If needed, the contents of all sub category codes can be collected later by means of creating a so-called Code Family.
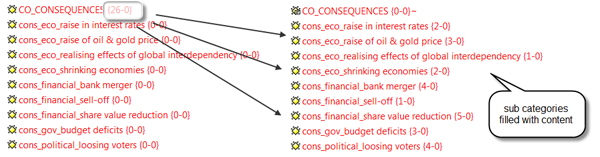
Figure 4: Filling sub categories with content [37]
I repeated this process for all initial codes that showed a rather high frequency. Then I looked at those codes with a low frequency paying attention which of these can be summarized. The next section will describe that process. [38]
3.6 Doing some more collecting: Developing higher order codes
A number of the descriptive codes with low frequencies referred to individual consequences of the financial crisis, and as such, added to the insights surrounding the crisis. So I collected them (initially) via a code family. The purpose was to filter these codes via the code family option. As the code list is sorted in alphabetic order, the codes referring to individual consequences appeared all over the place. Setting a filter, I could focus on the individual consequences codes and it became easier to sort and order them by way of changing the name of the code labels. Codes that contained similar content were merged under a common higher aggregated code label (see Figure 5).

Figure 5: Filtering codes via code families in the process of developing higher aggregated codes (enlarge this figure here) [39]
This way, the 20 descriptive codes were reduced to six codes and subsumed under the main category label "I_INDIVIDUAL CONSEQUENCES." After this process of splitting and aggregating, the code system consisted of 12 main category codes and their sub codes up to two levels deep adding up to a total of 76 codes.
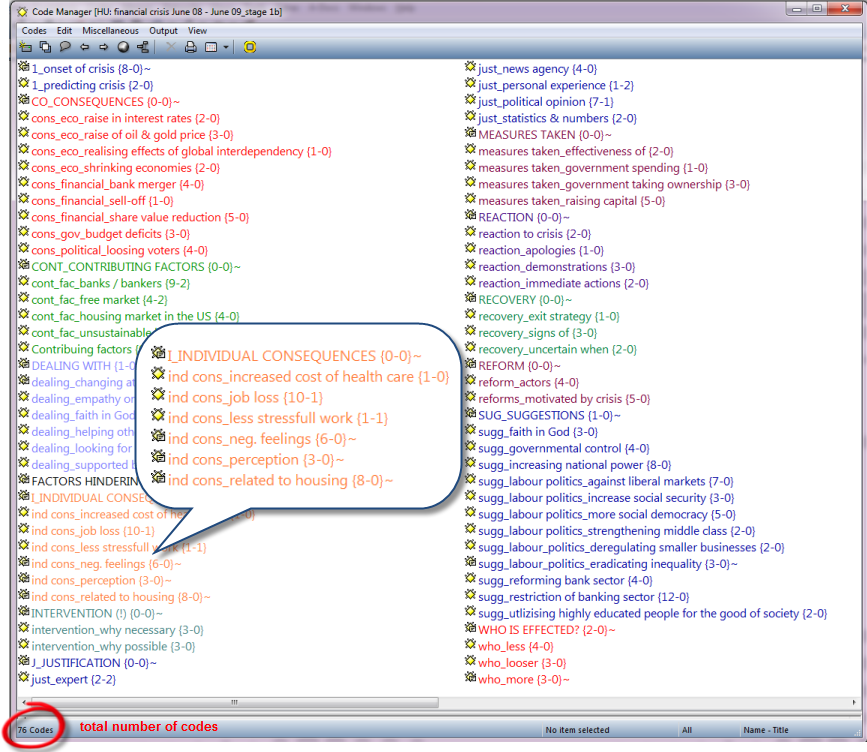
Figure 6: Structured code system in list view (enlarge this figure here) [40]
When you compare the list of codes in Figure 2 to the list in Figure 6, you see the difference. The list in Figure 6 can easily be explained to and comprehended by a third person due to the ways the codes have been developed and named, and thereby adds transparency to the research process. In addition, in terms of handling the list, it becomes easy to navigate. When typing the first few letters of a category label, the cursor jumps to this category in the list and there is no need to scroll. [41]
3.7 Thinking about things: Further data analysis
After coding, the next step was to look at the data with the research questions in mind. The research questions that were provided to us for analyzing the experiential study on the financial crisis were as follows:
Did views or arguments about the causes and prognosis of the economic crisis change between 2008 and 2009?
How do different actors identify the causes of economic crisis?
How do different actors predict the future consequences of the economic crisis?
And how do they justify their positions?
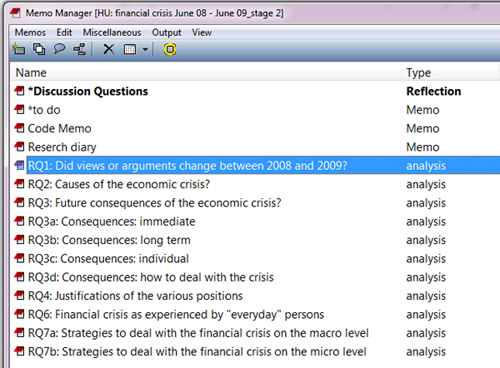
Figure 7: ATLAS.ti Memo Manager [42]
As you can see in Figure 7, all research question memos start with the prefix "RQ" for Research Question and a consecutive number. Research question 3 was later divided into sub questions so that each memo could be linked more specifically to quotes in the data illustrating the various aspects of the answer. Some of the research questions were added, based on what emerged as imported from the data. [43]
Then I queried the data to find answers to each research question. The analysis tools used for this were the query tool, the cooccurence explorer and cross tabulations of codes by documents. In section 4, the results of the analysis are presented. When reading the results, keep in mind the sample and the sample size that was used! The results are unlikely to adequately reflect the press coverage of the crisis in 2008 and 2009. [44]
4.1 Did views or arguments about the cause and prognosis of the economic crisis change between 2008 and 2009? (RQ1)
To find some initial answers to this question, I looked at the topics that were reported in the year 2008 as compared to 2009. This means taking a quantitative look, but it served well in providing an overview. In ATLAS.ti this meant to create a "Codes-Primary Documents Table" for all major category codes for the years 2008 and 2009. The filters were set by activating the respective primary document families (see Figure 1).
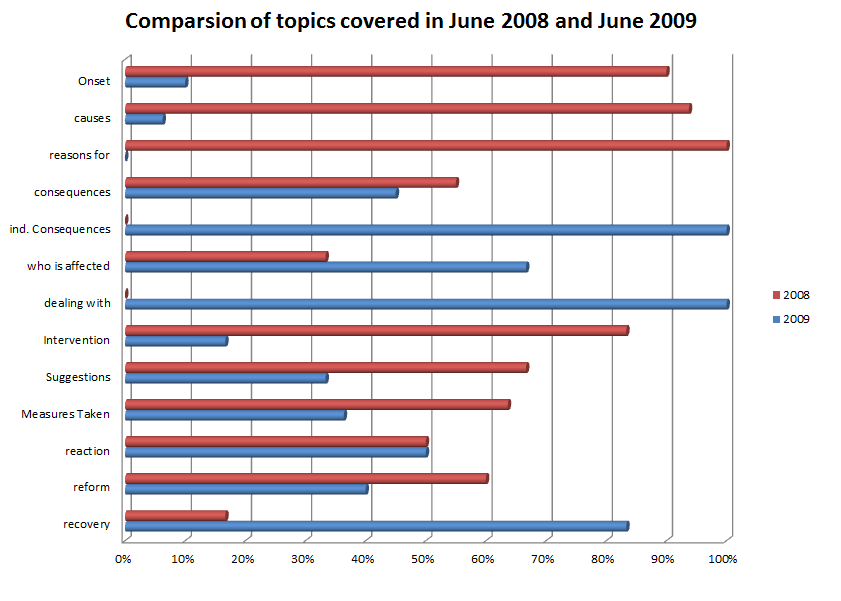
Figure 8: Initial findings in answering RQ1 (enlarge this figure here) [45]
What can be seen from Figure 8 is that the main topics of concern in 2008 were the factors contributing to the crisis, the onset and suggestions for how to deal with the crisis. In June 2009 the effects of the crisis become visible and much more is reported on the consequences of the crisis and who is affected by it. This appears to be an interesting finding and it can be conveyed very well and probably convincingly by adding bar charts as above. But please keep in mind; the data base consists of only 11 documents spread over various media sources and countries. The next step given a more comprehensive data set would have been to read through the quotations of those codes that show obvious differences and to write about possible changes in the views and lines of arguments. [46]
4.2 How do different actors identify the causes of the economic crisis? (RQ2)
In order to answer this question, the sub codes of the main category code: "CONT_CONTRIBUTING FACTORS" were queried10). [47]
The main underlying causes were identified to be the same by the various actors: changes in the structure of financial markets, accompanied by the introduction of new innovative financial products and the credit bubble. These causes were however evaluated in different ways. Especially the UK press was scapegoating bankers and liberal market policies:
"It was super-rich investment bankers and derivatives traders who dreamed up the collateralised debt obligations and exotic derivative products that have caused such chaos in the past year or so. It was the super-rich who have demanded cheap money for most of the past decade and cheered on the inflating of the credit bubble." (Guardian, 2:12, 2:3438-2:3766)11) [48]
Leading US and UK economists in comparison held consumer overspending to be responsible for the crisis. The line of argument was as follows: prices of homes had risen above historical records in the US and home owners were increasing their borrowing. Normally, the leverage falls when prices rise but this did not happen. This situation coincided with a dramatic change in the structure of the financial system that led to financial innovations like the "originate to distribute model." Instead of making you hold a loan or mortgage of any type, a modern financial firm made a loan and combined it with similar loans in a pool and then issued securities back by the pool. This worked well for a while but then the quality of the mortgages declined and the whole system became fragile (VOX, 5:4, 0:03:47.00-0:04:04.20). Thus, for economists the crisis was not primarily caused by bankers selling new and innovative financial products as a means to raise income, but by consumers borrowing too much money. [49]
4.3 How do different actors predict the future consequences of the economic crisis? (RQ3)
In order to answer this question, the sub codes of the main category codes "CO_CONSEQUENCES" and "I_INDIVIDUAL CONSEQUENCES" were queried setting a filter for actors via PD families. Reviewing those data segments, it became obvious that the reported consequences could be sorted by short term, long term, and individual consequences. [50]
4.3.1 Immediate consequences of crisis
The immediate consequences of the crisis as reported by the financial times.com (UK global) were share-value reduction and a sell-off, banks desperately trying to raise capital and dramatically raising oil and gold prices at the same time (ft, 2008, 4:7, 1:1736-1:1967). [51]
In Germany the first reaction was to merge banks in order to strengthen them, indirectly raising capital (Deutsche Welle, 2008). In contrast, in the UK press, economists called for splitting up banks to reduce the power of the financial sector. In addition, a major concern was related to consequences for the Labour Party. In both 2008 and 2009, it was feared that the Labour Party would lose voters and thus lose the next election.
"The election results show above all that working-class support for Labour is splintering and fragmenting. Unchecked, this will not merely bring down the government, but could destroy the party" (Guardian, 8:3, 1:959-1:1153). [52]
The focus of the concern on the future of the Labour Party may be a sampling artifact. [53]
In 2009, the figures show that the financial crisis had led to shrinking economies all over the globe. Even if one's own economy was not hit so much, one could not be too happy about it as the financial crisis had clearly demonstrated global financial interdependency. The path to recovery, so it was felt, will be affected by how well or badly other countries are affected (BBC, 9:6, 1:02.31-1:29:37). [54]
A concern raised by the German press was the huge state budget deficits due to increased spending of governments, 1. to save the banks and 2. to ease the depression somewhat. Here an international view is taken as compared to the much more national focus of the UK press. The German press talks about the warnings given by the EU and the proposals put forward by the EU ministers.
"The European Commission also says it will formally warn eight euro-zone nations—including Germany—against breaking EU rules by overspending on economic stimulus packages. Germany's budget deficit is expected to reach 3.9% of GDP in 2009. The European Union expects it to rise to 5.9% in 2010—almost double the 3% limit imposed by the EU Stability and Growth Pact that safeguards the stability of the euro. The European Commission forecasts that 13 out of the 16 countries sharing the common currency will breach the 3% rule in 2009 and 2010" (Deutsche Welle, 7:5, 1:985-1:1571). [55]
The blog data offered insights regarding the consequences felt by individuals rather than governments, political parties and banks. The crisis led to job losses, people forced to sell their houses or having their property foreclosed. They talked about feelings of fear, insecurity, being worried and scared, frustrated and depressed:
"I just want my feeling of security back" (Oprah, 11:21, 42:42).12)
"I don't have kids of my own yet, but I worry about my future if I keep floundering. So I'm surviving." (Oprah, 11:42, 196:198).
"I almost lost my home to foreclosure, and I admit, I was scared too, but I prayed and kept my faith" (Oprah, 11:45, 210:210). [56]
The crisis had motivated many to return to their religious faith and to look out for non-material securities. Some even reported that they live a healthier and better, less stressful life, because the crisis had forced them to work less. It is too early to say, but a possible consequence of the financial crisis could be a shift in values from material towards spiritual and non-material values.
"I recently took an insignificant position ... working only a few hours a week. No stress—I now realize that God had a plan for me. Although, I make half of what I did previously and work half the hours, I am twice as happy and look forward to a day of non-stress. I am enjoying myself. My co-workers are a joy. I now know God interceded. I had started to have health issues from my previous stressful position. Money isn't everything. It sure helps but my spirit is filled with happiness" (Oprah, 11:6, 18:18). [57]
4.3.4 Suggestions on how to deal with the crisis
In relation to question three, I thought it was interesting to look at the suggestions put forward on how to deal with the consequences of the crisis. The contents coded with the category codes and sub codes "REFORMS" and "SUGGESTIONS" offered some answers: [58]
In the UK press, some authors call for a much stronger Labour Party. They argue that the crisis has shown that free market politics as the conservatives would have it does not work. As a result of the financial crisis, according to the examined UK press, it is time to push forward classical goals of Labour and social democracy (raised in 2008 and 2009 alike). [59]
Other issues that were put forward were:
more government (this is also requested by Spanish protesters) (Guardian, 2:25, 4:3095-4:3423),
more national control (vs. EU law or global regulation). This issue was raised in 2008 as well as in 2009,
restriction on liberal markets, but at the same time less restriction and regulations for smaller businesses. This issue was raised in 2008 and 2009,
increased social security (raised in 2008 and 2009),
politics to strengthen the middle class, raised in 2008 (Guardian, 2:19, 3:882-3:1215),
eradicating inequality (raised in 2008 and 2009). [60]
Issues related to the bank sector, like calling for reforms and restrictions to the bank sector are voiced by the US (2009) and the UK media (2008). [61]
4.4 How do different actors justify their positions?
In order to find out about the justifications of the various arguments, I evaluated the entire article or report. The RQ4 memo is linked to those parts in the document that I identified to be the point of justification:
Political opinion: The authors of the Guardian report from June 2008 are social democrats and in favor of Labour politics. Therefore they attribute the cause of the financial crisis to the liberal markets and conservative politics (Guardian, 2:57, 6:304-6:655 and 8:1, 1:22-1:268).
Statistics: The BBC report based their position on statistics and objective numbers (BBC, 9:6, 1:02.31-1:29:37).
Expertise: Some of the authors or informants were experts in their fields (economists, central bank) and based their arguments on their expert knowledge (Vox, 5:9, 0:00:00.00-0:00:41.00).
News agencies: Some articles are based on news provided by news agencies like the DPA (Deutsche Welle, 1:8, 2:2379-2:2460 and 7:6, 1:1955-1:2030).
Personal experience: Yet another angle is personal experience, a lay opinion expressed by ordinary consumers (Oprah, 11:72, 4:6). [62]
After answering the research questions, visualizing the findings in network views was a natural next step. Figure 9 integrates some of the findings. The green boxes show the contributing factors, the red ones the immediate and long term consequence, the orange ones the mentioned individual costs of the crisis and the violet boxes indicate the source of justification put forward for the various arguments. Linked to the code boxes are coded data segments that can be shown as example quotes when viewing the network in ATLAS.ti. Video and audio quotations are played when selecting. The contents of the analytical memos can also be expanded.
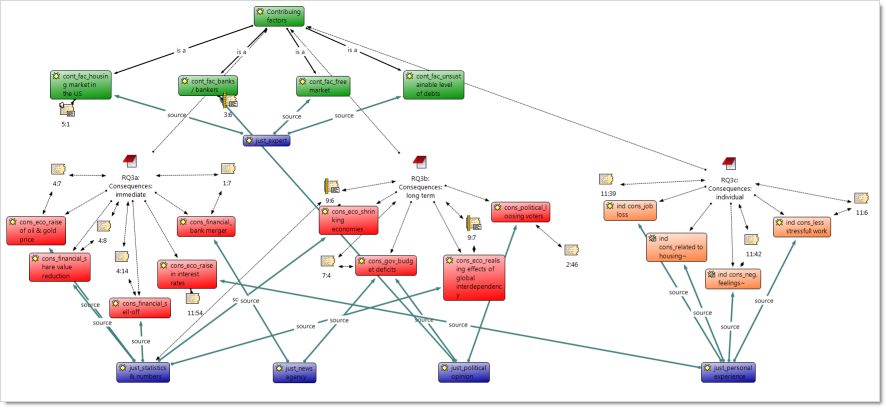
Figure 9: ATLAS.ti network view (enlarge this figure here) [63]
From my reading of the data, it appears that all countries included in the sample seem to focus on different issues. This may well be an artifact of the sample. The UK press attends to national issues, whereas the German press aims to bring in the EU perspective. The US press is busy analyzing the causes and consequences of the financial crisis. All point out that the financial crisis has made the interdependency of countries within the global market economy very clear. In terms of justifications, contributing factors are mostly explained by experts, immediate and long term consequences by objective facts on the one hand and political opinion on the other. When reporting on individual consequences, personal experiences have been used as source. [64]
5. Reflection on the Influence of Software on Qualitative Data Analysis
I began this paper by stating that methodological know-how is needed in order to use software appropriately. When users have a solid methodological foundation, I argued, the influence of software is reduced. As a novice qualitative researcher, I read some of the grounded theory books and followed the instructions provided. But I never applied the coding paradigm (STRAUSS & CORBIN, 1990) or any of the code families suggested by GLASER (1978). I felt that they were too restrictive, mostly did not fit the data and I did not want to force the data. I used grounded theory as many analysts do, as a set of useful procedures. Then slowly, without consciously being aware of it, I adapted them to a set of computer-assisted procedures which were outlined here as the computer-assisted NCT model of analysis. The method however is independent of a particular type of software. I would approach analysis in the same way using ATLAS.ti, MAXQDA, NVivo or QDA Miner. Some mouse clicks need to be adjusted, but the general principles of the analysis process remain the same. [65]
Writing this paper occurred at about the same time as finishing up the manuscript for the book on "Doing Qualitative Research with ATLAS.ti" (FRIESE, 2011). Since then some time has passed and the paper went back and forth a few times between the reviewers and myself allowing for some thoughts to settle and for some arguments to sharpen and to develop. As a result I would like to conclude this paper by refocusing the question that motivated the experiment in the first place. Software does influence the process of analyzing qualitative data as compared to manual paper & pencil methods. I have shown in this paper in which ways it can influence the process by outlining the NCT model of analysis. Regarding the differences between software packages, I doubt that they exert a strong influence. Assuming that an analytical choice was made to code the data instead of, for instance, using sequential analysis procedures, I would have developed the same codes in NVIVO, in MAXQDA or in any other software package that is mainly based on coding. Consequently, I would have been able to retrieve the same data segments in order to think and to analyze them and would have come up with the same results. [66]
As authors we have not yet read the other contributions, so I do not know the other findings, apart from what was presented at the Conference in April 2010. I however doubt that differences in findings are related to type of software package. Differences can likely be explained by the various samples, different analytical choices and differences in academic and culture backgrounds and training. What however is probably valuable in itself is to see how the various persons went about dealing with the data set and the analysis process. [67]
BBC (June 15, 2008). The banking crisis in 76 seconds, http://news.bbc.co.uk/2/hi/programmes/the_daily_politics/7959184.stm [Accessed: January 5, 2011]. (3:4, 0:00:22:87-0:00:32:98)
BBC (May 15, 2009). EU recession "deeper than expected", http://news.bbc.co.uk/2/hi/business/8053019.stm [Accessed: January 5, 2011]. (9:6, 1:02.31-1:29:37)
Guardian (June 4, 2008). The fight back starts here, http://www.guardian.co.uk/business/2008/jun/04/economicgrowth.banking/print [Accessed: January 5, 2011]. (2:12, 2:3438-2:3766; 2:19, 3:882-3:1215; 2:25, 4:3095-4:3423; 2:57, 6:304-6:655)
Guardian (June 10, 2009). Homes and jobs, that's all we want, http://www.guardian.co.uk/commentisfree/2009/jun/10/labour-gordon-brown-jobs-homes [Accessed: January 5, 2011]. (8:1, 1:22-1:268; 8:3, 1:959-1:1153)
Deutsche Welle (June 13, 2008). Germany steps up bank consolidation, http://www.dw-world.de/popups/popup_printcontent/0,,3411061,00.html [Accessed: January 5, 2011]. (1:8, 2:2379-2:2460)
Deutsche Welle (June 9, 2009). Euro-zone ministers agree to cut budget deficits next year, http://www.dw-world.de/popups/popup_printcontent/0,,4312563,00.html [Accessed: January 5, 2011]. (7:5, 1:985-1:1571; 7:6, 1:1955-1:2030)
Financial Times (June 27, 2008). Shares hit as fears grow over financial turmoil, http://www.ft.com/cms/s/7dbc2890-43a9-11dd-842e-0000779fd2ac,dwp_uuid=f6c5da2c-e98f-11da-a33b-0000779e2340,print=yes.html [Accessed: January 5, 2011]. (4:7, 1:1736-1:1967)
Oprah (June 2009). Has the financial crisis or unemployment affected YOU? R U Surviving????, http://www.oprah.com/community [Accessed: January 5, 2011]. (11:6, 18:18; 11:21, 42:42; 11:42, 196:198; 11:45, 210:210; 11:72, 4:6)
VOX Talks (June 30, 2008). Monetary policy responses to the financial crisis of 2007-2008, http://www.voxeu.org/index.php?q=node/1290 [Accessed: January 5, 2011]. (5:1, 0:00:34.40-0:01:15:58; 5:9, 0:00:00.00-0:00:41.00)
1) I define method in an epistemological sense as a series of steps taken to acquire knowledge, as compared to the more encompassing term methodology that includes the entire research process starting with an ontological consideration of what there is that can be studied (BLUMER, 1969; HUG, 2001; STRÜBING & SCHNETTLER, 2004). <back>
2) For a code to reach methodological status means that the researcher is able to clearly define a code and to determine its level. <back>
3) A good overview of all of these procedures can be found in SALDAÑA (2009):
Descriptive coding summarizes in a word or short phrase the basic topic of a passage of qualitative data (p.70).
Process coding uses "ing" words to mark action in the data. These can be simple observable actions like eating, reading, playing; or more general conceptual actions like conversing, struggling, adapting (p.77).
Initial or open coding is breaking down data into discrete parts, examining and comparing them for similarities and differences (p.81).
Emotion codes label the emotions recalled and/or experienced by the participant or inferred by the researcher (p.86).
Values coding is the application of codes that reflect a participant's value, attitude, believe, perspective or worldview (p.89).
Narrative coding applies the convention of literary elements and analysis onto qualitative texts mostly in form of stories. It blends concepts from the humanities, literary criticism and the social sciences (p.109).
Provisional coding establishes a predetermined list of codes prior to fieldwork. The list can be generated based on the literature review, the conceptual framework, previous findings or the researcher's previous knowledge. With progressing analysis, provisional codes can be revised, modified and deleted or new codes can added to the list (p.121). <back>
4) Saturation is the point in time when one realizes that no new codes emerge. When reading further, noticing still occurs but one only applies codes that already existing. <back>
5) As the substance is non-standardized qualitative data, the outlined procedures need to be regarded as rules of thumbs and code frequencies just as pointers. There might be codes that are only applied a few times, but are nonetheless very important, and the researcher may feel that it is not appropriate to subsume them under another code. Such codes may indicate that more data material needs to be collected. Or due to the nature of the content that is coded, it can be that data segments that can be collected, are sparse, for instance when coding epiphanies in narrative interviews. <back>
6) QDA Miner has a function where codes are suggested to the analyst based on a text search. The analyst then needs to accept or reject the data segments that are suggested to be coded with this code. The software learns from it. The claim is that the software after going through this learning process is better than a human coder. This may work with certain types of data where that what is not said and that what is between the lines is not important. But still the analyst has to determine the level of the code, is it a sub code or a main category code, where does it fit into the overall coding system? <back>
7) As I needed to convert the HTML files anyway, I preferred to convert them to rich text rather than to doc(x) files, because ATLAS.ti converts doc(x) files to rich text anyway. I converted the files to PDF files when I wanted to preserve the original layout. <back>
8) This list view has been chosen for presentation purposes only. During the process of coding I normally use the single column view. <back>
9) The resemblance of the category name "consequences" to the paradigmatic model described by STRAUSS and CORBIN (1990) is coincidental and related to the content of the data. The category was developed inductively as it was an issue that was frequently reported on in relation to the financial crisis. <back>
10) In technical terms this means double clicking on each quote and reviewing the data. <back>
11) The reference is built up as follows: Name of Media, quotation ID, location of the quote in the data. As this is a quote from a PDF document, the column number and number of characters within the column are provided. The start and end points of the quotation is provided in order to be able to locate it also on a print out of the document and not just electronically within ATLAS.ti. <back>
12) This is a reference for an RTF or Doc(x) quotation providing the source, quotation ID, and paragraph numbers of the start and end of the segment. <back>
Blumer, Herbert (1969). Symbolic interactionism: Perspective and method. Englewood Cliffs, NJ: Prentice-Hall.
Bodgan, Robert C. & Biklen, Sari Knopp (2007). Qualitative research for education: An introduction to theories and methods (5th ed.). Boston: Pearson Education.
Charmaz, Kathy (2002). Qualitative interviewing and grounded theory analysis. In Jaber F. Gubrium & James A. Holstein (Eds.), Handbook of interview research: Context & method (pp.675-84). Thousand Oaks, CA: Sage.
Charmaz, Kathy (2006). Constructing grounded theory: A practical guide through qualitative analysis. Thousand Oaks, CA: Sage.
Corbin, Juliet & Strauss, Anselm (2008). Basics of qualitative research: Techniques and procedures for developing grounded theory (3nd ed.). London: Sage.
Cortazzi, Martin (1993). Narrative analysis. London: Falmer Press.
Dey, Ian (1993). Qualitative data analysis: A user-friendly guide for social scientists. London: Routledge.
Friese, Susanne (2011/forthcoming). Doing qualitative research with ATLAS.ti. London: Sage.
Gable, Robert K. & Wolf, Marian B. (1993). Instrument development in the affective domain: Meaning attitudes and values in corporate and school settings (2nd ed.). Boston: Kluwer Academic Publishers.
Gibbs, Graham (2005). Writing as analysis, Online QDA, http://onlineqda.hud.ac.uk./Intro_QDA/writing_analysis.php [Accessed: January 20, 2011].
Glaser, Barney G. (1978). Theoretical sensitivity: Advances in the methodology of grounded theory. Mill Valley, CA: Sociology Press.
Goleman, Daniel (1995). Emotional intelligence. New York: Bantam Books.
Hug, Theo (2001). Editorial zur Reihe: "Wie kommt die Wissenschaft zu Wissen?." In Theo Hug (Ed.), Einführung in die Forschungsmethodik und Forschungspraxis (Vol. 2, pp.3-10). Baltmannsweiler: Schneider-Verlag.
LeCompte, Margarete Diane & Preissle, Judith (1993). Ethnography and qualitative design in educational research. San Diego: Academic Press.
Lewins, Ann & Silver, Christine (2007). Using software in qualitative research. A step-by-step guide. London: Sage.
Lincoln, Yvonne S. & Guba, Egon G. (1985). Naturalistic inquiry. Beverly Hills, CA: Sage.
Miles, Matthew B. & Huberman, Michael (1994). Qualitative data analysis (2nd ed.).Thousand Oaks, CA: Sage.
Morse, Janice M. (1994). Emerging from the data: The cognitive process of analysis in qualitative inquiry. In Janice M. Morse (Ed.), Critical issues in qualitative research methods (pp.22-43). Thousand Oaks, CA: Sage.
Okeley, Judith (1994). Thinking through fieldwork. In Alan Bryman & Robert G. Burgess (Eds.), Analyzing qualitative data (pp.111-28). London: Routledge.
Prus, Robert C. (1996). Symbolic interaction and ethnographic research: Intersubjectivity and the study of human lived experience. Albany, NY: SUNY Press.
Riessman, Catherine K. (2008). Narrative methods for the human sciences. Thousand Oaks, CA: Sage.
Saldaña, Jonny (2003). Longitudinal qualitative research: Analyzing change through time. Walnut Creek, CA: AltaMira Press.
Saldaña, Jonny (2009). The coding manual for qualitative researchers. London: Sage.
Seale, Clive (1999). The quality of qualitative research. London: Sage.
Seidel, John V. (1998). Qualitative data analysis. The Ethnograph v5.0: A Users Guide, Appendix E. Colorado Springs, Colorado: Qualis Research), http://www.qualisresearch.com/ [Accessed: January 20, 2011].
Strauss, Anselm & Corbin, Juliet (1990). Basics of qualitative research: Grounded theory procedures and techniques. London: Sage.
Strübing, Jörg & Schnettler Bernt (2004). Klassische Grundlagentexte zur Methodologie interpretativer Sozialforschung. In Jörg Strübing & Bernt Schnettler (Eds.), Methodologie interpretativer Sozialforschung: Klassische Grundlagentexte (pp.9-18). Konstanz: UVK.
Tesch, Renata (1990). Qualitative research: Analysis types and software tools. New York: Falmer Press.
Wolcott, Harry F. (1994). Transforming qualitative data: Description, analysis, and interpretation. Thousand Oaks, CA: Sage.
Susanne FRIESE is managing director of Qualitative Research & Consulting. She previously worked as assistant professor at the Copenhagen Business School, Denmark in the institute of marketing and as lecturer of qualitative and quantitative methods at the Institute of Sociology at the Leibniz University of Hanover, Germany. Her research interests include the advancement of computer assisted qualitative data analysis methods. In previous issues of FQS, she has written a review on: Doris Mosbach (1999). Bildermenschen – Menschenbilder. Exotische Menschen als Zeichen in der neueren deutschen Printwerbung [People in Images—Images of People: Exotic People as Signs in the New German Print Advertisement] and on: Margaret A. Morrison, Eric Haley, Kim Bartel Sheehan & Ronal E. Taylor (2002). Using Qualitative Research in Advertising: Strategies, Techniques, and Applications / Shay Sayre (2001). Qualitative Methods for Marketplace Research. Together with Graham R. GIBBS and Wilma C. MANGABEIRA, she served as an editor for the FQS issue on Using Technology in the Qualitative Research Process (2002).
Contact:
Dr. Susanne Friese
Qualitative Research & Consulting
Am Wietzestrand 15A
D-30900 Wedemark
E-mail: s.friese@quarc.de
URL: http://www.quarc.de/
Friese, Susanne (2011). Using ATLAS.ti for Analyzing the Financial Crisis Data [67 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 39, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101397.
Revised: 2/2011

Creative Commons Attribution 4.0 International License