Volume 13, No. 2, Art. 21 – May 2012
Hypertextuality, Complexity, Creativity: Using Linguistic Software Tools to Uncover New Information about the Food and Drink of Historic Mayans
Rose Lema
Abstract: In this essay on natural language I present a computer-supported study of words, sentences and hypertexts concerning bromatology (the study of food and drink) in a XVI century Maya-Spanish Calepin—the most complete and extended dictionary ever written on the culture of the constructors of the wonderful and prestigious Mayan cities of Uxmal, Kalakmul, Chichén-Itzá (ARZÁPALO, 1995). For constructing a complex corpus, I apply concepts of the three-body and the fractal dimension theories (POINCARÉ, 1908; MANDELBROT, 1975). First, I register an initial body of text by simply searching via the find key for abbreviations of bromatology and botany already recorded by the citation word in the Calepin. Then, I arbitrarily shorten the Spanish form corresponding to tasty and gather it through the whole dictionary. This way I obtain three bodies of interpretative meaning, lexias (BARTHES, 2002). Second, I establish the second and the third dimensional hypertextual relations between the gleaned words or sentences of text as well as their co-occurrences by using the comprehensive linguistics software, Tropes, a lexical and content analysis mixed tool, which brings up the qualitative and quantitative data pertinent to the research. Third, to bring back the colonial Maya voices of the Calepin, I surf the Internet and add to both written bodies of text a third text composed of beautiful colored images presenting food, drinks and tasty dishes that are still enjoyed by the Maya today and have been appreciated for almost five centuries. Notwithstanding the above, neither one of the three bodies (corpora) nested fractally one inside the other is exhaustive. Nonetheless, the study of their interrelations could lead to the deepening of our knowledge on the complex juxtaposition between Siglo de Oro and Maya languages and cultures in the Yucatán Peninsula.
Key words: bromatology; fractals; hypertext; lexias; three-body theory; Mayan culture; creativity
Table of Contents
1. Introduction
1.1 Theory, method and terminology
2. Semiautomatic Processing
2.1 First step
2.2 Second step
2.3 Third step
3. Semantic and Hypertextual Analysis
3.1 Star graphic
3.2 Spheres graphic
3.3 Hypertexts, hyperimages
4. Conclusion
Polonius: What do you read, my lord?
Hamlet: Words, words, words.
Polonius: What is the matter, my lord?
Hamlet: Between who?
Polonius: I mean, the matter that you read,
my lord.
Hamlet (Act 2, Scene2)
This essay describes the results of a study of Mayan bromatology (the science of food and drink). The primary data for the study was the Calepino de Motul, a XVI century Maya-Spanish dictionary, which was studied using a computational, non-linear, complex, creative/divergent construction of the body of work. Creativity and divergent thinking being (POPOVA, 2010, p.3):
"Divergent thinking isn't the same thing as creativity. I define creativity as the process of having original ideas that have value. Divergent thinking isn't a synonym but is an essential capacity for creativity. It's the ability to see lots of possible answers to a question, lots of possible ways to interpret a question, to think laterally, to think not just in linear or convergent ways, to see multiple answers, not one." [1]
The essay provides a discussion of theory, method, and terminology. It is in this section that I introduce Tropes, the software used for this investigation. Next, I describe the two-tiered computer-supported process of analysis that was used to glean meaning from the Calepino de Motul. In section two I describe the comprehensive hypertextual design, analysis and interpretation that were possible using the semiautomatic processing available in Tropes. In section three I discuss the final semantic and hypertextual analysis, with descriptions of the highest frequency and kind of references to food and drink—assuming they were easy to get for everyday alimentation. As a third body of analysis, I pick up the words with the lowest co-occurrences assuming that they could reflect the food and drink most rarely found in those times, perhaps somewhat difficult to prepare and undoubtedly the richest, most sophisticated and delightful. To revive the exquisiteness of the dishes, I obtained from the Internet their modern pictures. When found, they seem to bring back the Calepino to the present through taste, color, image and flavor¾telling us at the same time how much Maya still enjoy them today. In section four, I provide my concluding thoughts. [2]
1.1 Theory, method and terminology
The approach employed here comes from a chaotic, complex, and creative method (MANDELBROT, 1975; MORIN, 2005; PRIGOGINE & STENGERS, 1979), and looks for a new way to read culture through a dictionary with computer assistance (LEMA, 2002; LEMA & ABASCAL, 2011). In fact, what can be gathered from the method are principles and concepts for deciding on how to build, organize, explore and analyze this singular corpus. In the next section, I present theories, processes, and terminologies. [3]
To construct the corpus I have recurred to the three-body theory, invented by the French astronomist and mathematician POINCARÉ (1908), which establishes that orbits between three celestial bodies (as sun, earth, moon) are far more complex and extremely different from orbits of only two of them (as moon and earth). Moreover, the orbits between two bodies do not change unless in exceptional circumstances, whereas the orbits between three bodies change constantly as it corresponds to celestial bodies; in thousands of years, the change will be tremendous. In the fields of humanities and social sciences, the application of a three-body theory to a text analysis promises always to be more original, dynamic and innovating than a two body one (BRIGGS & PEAT, 1989). [4]
1.1.2 Fractals and self-similarity
"Roughly speaking, fractals are complex geometric shapes with fine structure at arbitarily small scales. Usually they have some degree of self-similarity. In other words, if we magnify a tiny part of a fractal, we will see features reminiscent of the whole. Sometimes the similarity is exact; more often it is only approximate or statistical.
Fractals are of great interest because of their exquisite combination of beauty, complexity, and endless structure. They are reminiscent of natural objects like mountains, clouds, coastlines, blood vessel networks, and even broccoli, in a way that classical shapes like cones and squares can't match. They have also turned out to be useful in scientific applications ranging from computer graphics and image compression to the structural mechanics of cracks and the fluid mechanics of viscous fingering" (STROGRATZ, 2000, p.398). [5]
I will be considering the word text in its broad philological sense, as weaving. In this case, I will be weaving written text with pictured images. In addition I will include in it the poststructural term lexias, which is defined by BARTHES as a sequence of text where content and signification are constructed by the reader and interpreter, who consciously builds her/his own analyses and interpretation in a way that fits into his/her sense of the world. A lexia becomes a minimum and dynamic unit of signification, defined by its impermanent changes, and it will never have a closed and fixed meaning. It constitutes a most fluid and versatile resource in discourse (BARTHES, 2002). [6]
When graphs, co-occurrences and images created by the software—Tropes—interweave on the screen they form an extended and diversified lacing, a dynamic text of texts, a text beyond texts, a hypertext (hyper-, meaning over, beyond). Furthermore, when images are fractalized to obtain special scaled layers of diversified images, they will naturally cover not only the figurative images we are used to observing in everyday life (a poster, a rock, somebody, a picture, a film, a ghost, an Internet page, a building) but will include images of alphanumeric, phonetic, hieroglyphic nature, rock carvings, sculptures, any symbolic code from any culture and any epoch. Hence, in all cultures of all times, letters, icons, images, ideograms, a, 5, w or π are images (VAN LEEUWEN, 2005). Consequently, I will look at the process of hypertextualization in its most extensive and postmodern sense which first includes intertextuality, that is, relations between written texts, like a text nested into a text or a text linked to another text, whether virtual or digital. But hypertextualization also involves hypertextuality, a term actually used only for relations between electronic texts and images. Nevertheless I consider a hypertext as a weaving (or a weaving of weavings) of symbols and/or images, hypertexts and/or hyper-images, and it offers a complex combination which expands and enriches the field of textuality, discourse and language. Moreover, if letters are represented by images, and of course images by images, hypertext includes past, present, and prospective combinations of images in culture (including evidently technoculture) and in nature. Both domains (culture and nature) are on the same plane, hypertext links and unifies them in a vast and non fragmented theory which involves complexity. Nevertheless, I must point out again that the term "hypertext" is actually used mainly in computation and "in some distant, or not-distant, future all individual texts will electronically link to one another, thus creating metatexts and metametatexts of a kind only partly imaginable at present" (LANDLOW, 2006, p.69). Therefore, in addition to LANDLOW's statement, I will be employing the notion of hypertext not only for digital hyperlinks, but also for physical ones—printed, carved, painted, gestured or otherwise—and for mental ones. Therefore, hypertextualization opens up a constant movement from in silico to paper, from hand, to mind, and other prospectively imaginable resource —be it immaterial, material and/or technological. Accordingly, the term and process of "text" is expanded to a scope far beyond the conventional definition. In fact, it is expanded to hypertext, that is, significantly expanded to the maximum. [7]
Notably , the concept of "expansion" contained in the morpheme hyper- could also reflect the postmodern emerging field of qualitative analysis phenomenon, which represents quite an expansion of research at least for the social and humanities fields, that is, an integration of both qualitative and quantitative analyses that were regarded as two distinct research methods. Take the term "self-similarity" as an example. When combining qualitative and quantitative methods as FIELDING and CISNEROS-PUEBLA (2009) suggest, texts, lexias, words, hypertexts and hyperimages turn out to be self-similar to MANDELBROT's fractals. At the same time self-similarity is established inside each one and across them. Likewise, qualitative analysis constitutes an innovative fractal amid the vast field of research. Thus, language sciences and qualitative analysis join thermodynamics fractals when searching hypertexts in the Calepin. [8]
1.1.5 The Calepin: Database for the study
As the aim of this essay being the interpretation of hypertexts concerning bromatology in a Maya manuscript, it is necessary to point out a few characteristics of the dictionary with its lexical, phonological, semantic and pragmatic data. The Maya-Spanish Calepin contains 16,000 entries tightly displayed on 465 folios reverse and obverse. It was created by the erudite bilingual linguist, the Franciscan friar Antonio de CIUDAD REAL (ARZÁPALO, 1995).1) The task he undertook lasted through 45 years, from his arrival to Campeche in 1571 to his death in 1616, in the Yucatán Peninsula, southeast Mexico. He was sent to Campeche by Philip II, the Spanish monarch who governed "a territory where the sun never set" (VILAR et al., 1965). The friar's mission consisted mainly in baptizing, civilizing the Mayas and learning and describing their language. [9]
1.1.6 Tropes: Software for analysis
The analysis mixes methods for establishing hypertexts, which are the core of the present case study. For this purpose I will be using the handy Tropes. Nowadays, it is a free downloadable tool for treating, analyzing, and mining natural language. It has being evolving since it was created in 1994 by recognized experts in information technology and linguistics—Pierre MOLETTE and Agnès LANDRÉ—who founded their work on the research of Rodolphe GHIGLIONE (see http://www.semantic-knowledge.com/TropesEnglishFreeLicenseV80a.txt). [10]
In an inquiry, the linguist explores the use of language through talk, discourse, narratives, texts, images and interviews gathered historically over centuries or compiled in the present. S/he often works on very large corpora containing hundreds of thousands of words. Today, such linguistic searches can be systematically and objectively done by means of tools for content analysis (MOSCAROLA, 1994; GHIGLIONE, LANDRÉ, BROMBERG & MOLETTE, 1998). A number of very advanced software programs have been created in the last decades for data mining, content analysis and/or lexical and grammatical categorizations. These tools mix qualitative and quantitative data analysis through extremely diverse corpora, and they are used by many investigators in the social sciences and humanities. [11]
In most programs, percentages, frequencies, occurrences and co-occurrences usually constitute the quantitative part of the research. Tropes offers percentages of word frequency as well as co-occurrences between hypertexts. The software is offered today in six different languages. It does not yet analyze images (photos, pictures, drawings). In lieu of a photograph, Tropes produces immediately under any chosen section of text the most direct, transparent and simple hypertextual graphics that are described below. [12]
Its most important quality is that users of all ages, coming from any discipline, and without training, can intuitively use it once downloaded, without having to understand, interpret and learn a mode d'emploi or to consult a technician, an electronic engineer or a good friend. It strongly fosters self-teaching. Moreover, it provides a good way for playing with texts, developing reading, learning a language and learning about language, interpreting content, and prospectively encouraging writing. It supports the development of relational cognitive habits, lexicon, and grammar acquisition as well as semantic exploration by means of its didactic, simple, economic, and intuitive icons and functions. Particularly, it represents a perfect tool for the recent field of literacy studies which includes electronic and non-electronic texts. Additionally, it furthers discourse analysis of very large bodies of texts. [13]
Tropes has been applied since its creation by professionals in social science and computational linguistics for solving numerous problems in natural language processing. Users include major corporations in aerospace, telecommunications, pharmaceuticals, the motor industry and numerous other sectors; government departments worldwide, including defense, health and science ministries; statistical and other research institutes; the administrations of major cities in Europe and abroad; numerous universities; financial and commercial organizations and many more. [14]
The uses of Tropes cover a wide spectrum, including "technology watch," which is "systematically capturing, analysing, disseminating and exploiting useful technical information for the watch and growth of a company. Watch must be ready for any scientific or technical innovation susceptible to creating opportunities or threats" (ROVIRA, 2008, p.2). [15]
They also include analysis of free-response questionnaires, studies of the effectiveness of advertising, monitoring of changes to brand image, analysis of clinical interviews, behavioral studies or analysis of literary works. Notably, it is a perfect research tool for analyzing and interpreting all the usually gigantic corpora collected in field logbooks or recorded by aural and/or visual technologies in the fields of speech, ethnography, ethnolinguistics, geolinguistics, dialectology, sociolinguists, therapeutic discourse, social semiotics, and the like, while maintaining the content understanding, analysis and interpretation of all kinds of extended physical or virtual texts coming from whatever discipline. Briefly: Tropes embraces all language and that is what a linguist desires. [16]
1.1.6.1 The body of text format
Tropes requires that sources be introduced in the form of HTLM (web pages), RTF, or other manipulable format. The text may include punctuation marks, capitals or special characters (such as parenthesis, numbers, percentages). Only alphabet letters and punctuation characters will be used during the analysis. If you want a series of words to be considered as a single word, link these words together with the underline character "_." For instance "ate_de_membrillo," which means "sort of quince paste." [17]
Via a user friendly Graphic User Interface (GUI), Tropes, which is a text analysis software, proposes numerous hypertext graphs and automatically sorted keyword lists: practical aids to immediate viewing and checking a hypothetical interpretation in order to show as clearly, directly, simply, succinctly as possible the complex three-dimensional linguistic and cognitive phenomenon of hypertextuality. In this presentation I have chosen, between the many modes offered by Tropes, two created for this purpose: the Star and the Spheres graphs. Spheres represents hypertexts of one clicked word or bunch of words, whereas the Star graph discloses the co-occurrences of both of them. When one clicks on any displayed hypertext you travel to another Sphere or Star screen in an infinite three-dimensional hypertextual journey. Both hypertext graphs show relations between linguistic groups of terms: the ones before, or predecessors and the ones after, or successors, on both sides of the central term selected to search its hypertextual interwinings. In other words, both Spheres and Star graphics are oriented on the screen space (see http://www.semantic-knowledge.com/tropes.htm). [18]
The Spheres graph (Figure 22) gives a broad idea of hypertextual relations via the dimensions (non numeric) and colors of its icons and orbits as well as for the non- numerical distances between Spheres and their orbits. The linguistic terms appear in the form of spherical areas. Each relational group of terms shows up as a Sphere, whose surface on the screen is proportional to the number of words it contains. Sometimes, two Spheres overlap partially one another, but that does not change the analysis results; on the contrary, it offers an interesting point to study on very close self-similarities. The graph also illustrates relations with the central reference, which has been chosen to find the correspondent constellations of hypertexts. The distance between the central reference and the others is proportional to the number of relations connecting them. In other words, when two words or groups of words are close together, they share many hypertextual relations, and when they are far from one another, they share few relations. If we take up the metaphor for the planetary system, we can say that there is a central linguistic term, around which related but differently sized planets (according to the number of word co-occurrences they might contain) revolve more or less closely (are more or less frequently used together). As word categories cannot be displayed in the Spheres mode, the user needing them for other purposes can click on the left column shown on the screen precisely on the categories label. Notice that in the Spheres graph neither the passive and active verbs nor the syntactic relations are displayed. If the researcher wanted to find other linguistic phenomena s/he just has to click on a special icon reserved for these on the left and outside of the graph and come back again on the search of hypertexts. In fact if we want to know the global number of equivalent words or groups of words, that is, the number of Spheres on the screen, we must click on the Used references label on the left and external side of the Spheres graphic. Note, however, that we will not know precisely the number of hypertextual relations between the Sphere and the Star graphs. We will describe the functions of the Star graph below. [19]
When surfing hypertextually in the Spheres graph from one term to another via clicking on one of them, which immediately places it in the center of the graph, the sizes and distances among the Spheres are also modified. The changes between different hypertextual relations are indicators of the center of interest of the author or oeuvre analyzed. If a concept you have clicked on has hyper-textual references with many others, it may be deduced that this reference is very important, or at any rate more important than others. [20]
To find the co-occurrences between a couple of hypertexts one must necessarily go to the Star graph (Figure 4). It is quite vivid, economic and precise. At the same time its representation is a lot more easy and rapid to read than with the Spheres graph. It immediately displays the relational quantitative and qualitative aspects, providing the precise numerical data that was not present in the Spheres graph. Having recourse to both modes allows you to progressively penetrate the massive qualitative linguistic inter-meanings, and, as an indispensable finishing touch, shows you their distributional co-occurrences frequency. Perception of sense and meaning in linguistics requires both complementary steps, the quantitative as well as the qualitative. This is particularly the case in studies of significantly large amounts of discourse. The branches of the Stars systematically relate all hypertexts in a scientifically rigorous manner. [21]
In fact, the figures shown on the Star graph give the number of relations (co-occurrence frequency) existing between the central word or group of words and precisely each one of the various sequences it intertwines with hypertextually in the body of text. You can follow relations shown on the graph by clicking directly on the terms you wish to study. The chosen term will occupy the center of the next screen in less than seconds and will be surrounded by its new hypertextual relations. This very powerful function enables you to move through a text while viewing micro-worlds as in a movie and to analyze the connections between various of its actors or characters. Numbers tell you how important the micro-worlds obtained through this function are. They amplify your first hypertextual visualization of the body of text. You now may feel the power of the hypertextual voyage, which will drive you through paths, methods, and issues you had not even imagined before when reading in a linear fashion. As is the case with the Spheres graph, which depends on the selected concept, when the Star graph displays the hypertextual relations between terms or groups of terms, it also shows predecessors in the whole body of text on the left and successors on the right. [22]
The Sphere and Star graphs, when used together, allow for the full capacity and power of hypertextuality as a tool for linguistic analysis (see http://www.semantic-knowledge.com/tropes.htm). [23]
1.1.6.5 Statistical, probabilistic and cognitive analyses.
One last word on Tropes qualities (even if I did not have to go to these applications in the actual study). This tool also has the capacity to carry out different sorts of text analyses: statistics on the total occurrence frequency of the main word categories and subcategories; statistics on the co-occurrence and the connection rate of semantic fields and word categories; a probabilistic analysis of the words occurring in bundles, and a geometric analysis of the bundles delimiting episodes in the body of text; a histogram of the text or episode with the correspondent frequency distribution; a cognitive-discursive analysis (CDA), making it possible to detect the most characteristic parts of the text; and more. Among other things, statistics are used to lay out the results, from the highest figures to the lowest significant ones or vice versa depending on what you need to find. The frequent word categories and the text style are obtained by comparing the distribution of the occurrence frequency of the categories observed in the text with linguistic production norms. These norms have been elaborated after studying a great number of different texts and will be stored into specific in-built tables. [24]
To construct the corpus for submitting to analysis, I e-searched lexias (by means of the handy very popular Find function) through the whole dictionary. A lexia, originally, lexie in French, figures a space of dissemination between hypertextualities and their potential emerging significations. Such significations depend on the reader, receptor or analyst's culture (race, gender, generation), as well as on her/his chronolinguistic, dialectological, sociolinguistic and ideological background. S/he will establish her/his own lexias which respond to a deep reading, as proposed by BARTHES (2002). And, as presented above, they are: first, the abbreviation bro.; secondly, the abbreviation bot.; and thirdly, a group of words containing the morpheme sabr-. [25]
2.1.1 bro., an abbreviation of the word bromatología, "bromatology"
to identify all the entries concerning bromatology. It is important to point out that as in many other classificatory semantic fields found in the Calepin, the abbreviation bro. was appended to the correspondent lexical entry very recently by ARZÁPALO (1995) in his very prestigious and recognized edition. Needless to say it represents a very handy appendix for linguistic search. [26]
2.1.2 bot., an abbreviation of the word botánica, "botany"
as there are and might have been many edible plants in Yucatán. This abbreviation was also appended in the 1995 edition. [27]
2.1.3 Sabr- , a home-grown third lexia
bringing forth word derivations containing the morpheme sabr-, "tasty." To diversify and simultaneously enrich the corpus, I recur to POINCARÉ's method contained in the three-body theory (1908), pointed out above. He studies the very complex and constantly modifying orbits of three planets instead of studying two in a dualistic, linear and comparative way. When e-constructing a three-body corpus, unexpected and multiple sets of interrelations start to show up. In fact it is easy to observe that more complex and wide-ranging links emerge between three elements, when the third one shows particular self-similarities in relation with the other two. This process leads to a highly hypertextual and creative design. Therefore, the third body of lexias consisting in a compound comprehending the morpheme sabr-, for sabroso, "tasty," as well as other words belonging to a self-similar semantic family, represents an innovation as there is no such classification in any of the Calepin's editions, and a most productive new means for establishing varied links in the field of bromatology. [28]
One could go further and further in using different linguistic forms more or less indirectly related to the lexia sabr- when following the multiple paths of food and drinking perceptions, and the range of fractals would be more complex. As an example, I will illustrate below with a few lexias that contain the form sabr-. By adding an absolutely literary, word to word translation into English, the lexias will perhaps talk a lot more about themselves and will gently allow the reader to listen to the Spanish voices of the past. Let us listen to the Maya voices the Franciscan priest recorded (before being manipulated and e-processed) freeing the actual interpreters of the Maya world.
"cii tii cal loc. psi. cosa gustosa y sabrosa y es propiamente de lo que se bebe, pero aplícase a otras cosas. Maa cii tu cal Dios u zaatal ah keban no se huelga Dios de que se pierda el pecador cii ua ta caleex ca uaalab tii batab por ventura holgáis que se lo diga al cacique" (ARZÁPALO, 1995, p.124, 074v, 03).2) The three Maya sequences meaning: a tasty and savory thing and it is properly about something one drinks, but it is applied to other things; God is not very pleased that the sinner gets lost; by chance would you like me telling it to the chief?
"cii tii chii loc. psi. cosa sabrosa y gustosa y dícese de lo que se masca aunque se aplica también a otras cosas. De aquí sale cii tin chii in chaantic ah okotoob gusto me da mirar a los que bailan o danzan" (p.124, 074v, 03). Meaning: a savory and tasty thing and it is said to be about something one masticates even though it can also be applied to other things; pleasure is given to me when I look at the ones who go to the ball or dance.
"u chayan than loc. psi. cosa gustosa y sabrosa como comida delicada y no de las ordinarias" (pp.752-753, 444v, 03). Meaning: a tasty and savory thing, like some delicate and non ordinary food.
"ciimaon tii chii; ciimaonac tii chii loc. fis. cosa sabrosa al paladar, aunque es poca" (p.122, 073r, 09). Meaning: a savory thing to the palate, even if it is a small amount.
"cii adj. qui. cosa dulce, sabrosa o que sabe bien, deleitable, gustosa y suave a los sentidos y cosa amorosa" (p.117, 070v,01). Meaning: sweet thing, savory or good to taste, delightful, tasty and delicate to the senses.
"zaop: sus.bot. anonas muy sabrosas, de mucha carne y pocas pepitas. Annona cherimola" (p.163, 098v,10). Meaning: very savory anonaes (tropical fruit) with lots of pulpa and few seeds.
"zapat cunah, zapcunah vt. bro. hacer desabrida alguna cosa" (p.163, 099r, 03). Meaning: to make something insipid.
"maa cii loc. qui. cosa amarga, cosa desabrida y sin sabor" (p.482, 282v, 08). Meaning: a bitter thing, an insipid and unsavory thing. [29]
I will now quote a complete lexicological entry in order to describe its components: "aal sus. bro. el agua que uno toma para beber. Chaeex a uaal tu zebal ca xiiceex tomad de prisa vuestra agua e idos" (p.1, 001r, 01). Now let's annotate some specifications regarding the different components of most of the Calepin's entries.
Bold characters as in aal enhance the original sequences in Maya which Father Antonio de CIUDAD REAL (ARZÁPALO 1995) might have collected from actual everyday informants during his life in Yucatán.
Italic characters, situated immediately after the entry, as in sus., describe the grammatical category of the Maya word aal, in this case, a substantive. The grammatical classification was also appended in the1995 edition.
Italic characters, just before the Spanish translation, as in bro., offer the semantic field abbreviation, as just seen in 2.1.1 and 2.1.2.
Normal characters bring up the translations from the Maya sequences as aal into Spanish, as in "el agua que uno toma para beber." It must be reminded that the Spanish language in the Calepin corresponds mainly to the Spanish written language of the Siglo de Oro, a sociolectal variant wonderfully recorded by CIUDAD REAL (ARZÁPALO 1995)—a most outstanding linguist and ethnographer.
Once the last clarifications on the systematization of the Calepin's entries have been brought about, it is time to translate the Spanish sequences into English: aal sus. bro. the water that one gets for drinking. Chaeex a uaal tu zebal ca xiiceex quickly get your water and go away. [30]
The last step for obtaining the corpus to be processed by Tropes consists in suppressing all Maya sequences, all metalinguistic and lexicological indications, abbreviations, phrases, and even translations into Latin when they appear. This gesture means we are suppressing most ARZÁPALO's and CIUDAD REAL's (ARZÁPALO, 1995) voices in order to keep only the Spanish translations they recorded. It also means that I have deconstructed the original composition of the dictionary and extracted a new corpus on bromatology. [31]
3. Semantic and Hypertextual Analysis
When the three last steps have been systematically accomplished through all the dictionary, we compose the whole corpus with all contexts containing bromatology, botany and taste terms. Figure 1 represents a short sample of the whole written text ready to be processed by Tropes.

Figure 1: Sample of the text to analyze (enlarge this figure here) [32]
We now employ the Star graphic offered by the software. It shows some of the diverse contexts for plants; and its co-occurrences with each one of the other words. As supplementary information, on the left, we have the words that co-occur in the text before plants and, on the right, the ones co-occurring afterwards. As the graphic is hypertextual, when clicking on any of the words, it will appear in the center of the next Star graphic with its own distributed and detailed co-occurrences. [33]
As shown in Figure 2, when clicking on Tropes label Reference Universe 1 (selected because it contains elements concerning fauna and flora), and then on the term plants, we obtain 510 semantic equivalents or affinities related to botany, bromatology or to taste, with terms like prune or tree. So, the variety of flora is corroborated and most of the species are expected to be edible. Figure 3 shows only a section of the corpus with the contexts for plants, and Figure 4 pops up the Star with the whole corpus specific co-occurrences, of which there are 16 appearing in the corpus before the central term plants, for food and drink, and 3 appearing afterwards for health and diseases. It also shows the co-occurrences between the central term and each one of the terms in each branch. Some of the cultural features, actions and events start to show through the combined text, co-occurrences and graphics referring to a term belonging to nature, e.g., plants, and the link between culture and nature starts to develop in the Calepin.
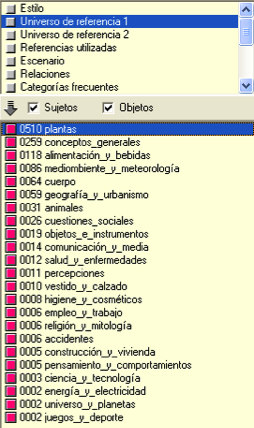
Figure 2: Plants 510 equivalencies

Figure 3: Plants context (enlarge this figure here)
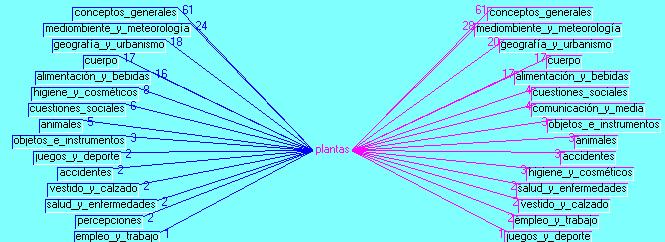
Figure 4: Plants Star graphic [34]
Clicking once again on Reference Universe 1 label we obtain 31 equivalents for animals. There are less references to fauna than flora in the text, and this could perhaps be associated with the proportions and nature of the ethnic group diet. Figure 5 brings up some of its contexts. They are diverse and refer mainly to birds and small rodents, common in Prehispanic Yucatán, and to pigs and horses, brought in by the Spanish ships. Figure 6 pops up the Star graphic with the co-occurrences, the highest having to do with food and drink, 6, and plants, 3 before animals and 5 afterwards. In contrast with section 3.1.1, where plants co-occurred 16 times with food and drink, here animals co-occur only 6 times.

Figure 5: Animals context (enlarge this figure here)

Figure 6: Animals Star graphic [35]
Tropes identifies 109 equivalents, the term banana being relatively frequent as in Figure 7. As expected, on Figure 8, the highest co-occurrences being tree, 12 to the left and 5 to the right, as well as parts of the plant, 13.

Figure 7: Fruit context (enlarge this figure here)
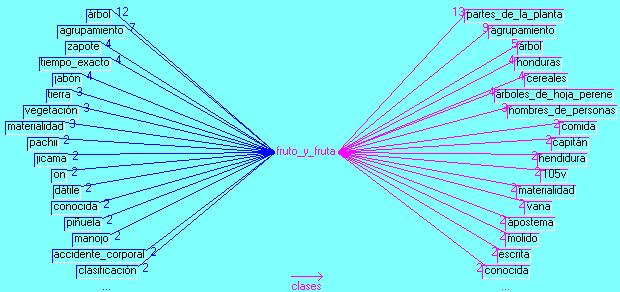
Figure 8: Fruit Star graphic [36]
There are 108 equivalents for cereals in the whole corpus. Corn being also in those times the people's indispensable everyday food. Figure 9 shows a series of significant contexts. The main discursive association is established in Figure 10 with corncob, 19 co-occurrences, reflecting reality in the surrounding nature. With the term food 4 but with hunger, 2. This last item and reality being one of the principal worries for the Franciscan friar.

Figure 9: Cereals context (enlarge this figure here)
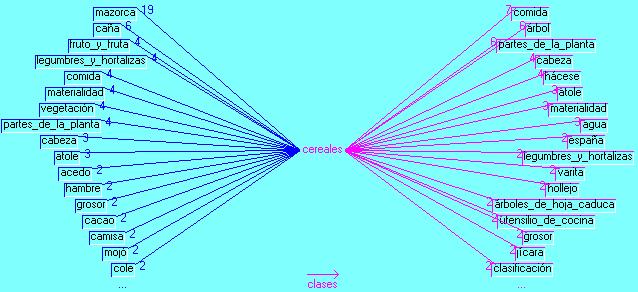
Figure 10: Cereals Star graphic [37]
Figure 11 shows the context for some of the 88 equivalents for food, while Figure 12 brings about 7 co-occurrences with cereals on the left side and 4 on the right for the same item. It also indicates 4 co-occurrences on both sides with the well-known chili or hot pepper. In addition some important items included in the diet are mentioned as hen and fish.

Figure 11: Food context (enlarge this figure here)
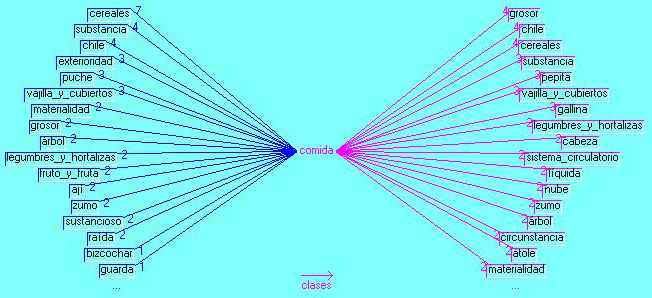
Figure 12: Food Star graphic [38]
Tropes adds up 30 equivalents for vegetables. Figure 13 unfurls a nice variety of them like garlic, radish, cucumbers. Similarly, Figure 14 specifies relatively similar co-occurrence numbers: plants and cereals show each 4 and/or 2 co-occurrences on both sides when connected with items like chili, cereals, pumpkin. All these results could represent rich, natural and quite different dishes when creatively combined.

Figure 13: Vegetables context (enlarge this figure here)

Figure 14: Vegetables Star graphic [39]
The word water shows 26 equivalents and it is repeated through the corpus. Figure 15 shows a small part of the corpus without any similarities, synonyms or affinities for water as it happened with the rest of the terms we have pointed out in the preceding sections. Figure 16 unfurls many branches for a large quantity of co-occurrences with relatively low numbers which go from 4 for pumpkin to 1 or 2 for jícama (a tuber), tostada (toasted corn tortilla), rabbit, salt, bird and so on.

Figure 15: Water context (enlarge this figure here)
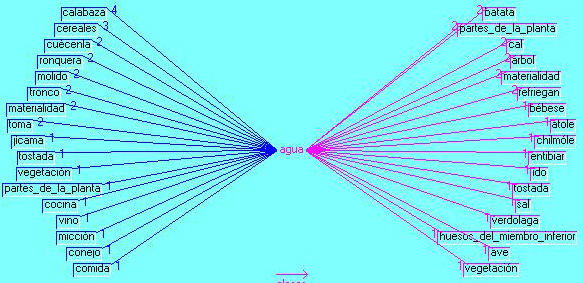
Figure 16: Water Star graphic [40]
It is quite reassuring to observe in Figures 17 and 18 that rich and nourishing pumpkins used to be part of everyday life and diet. With 25 equivalents, the Star graphic spreads a relatively high number of co-occurrences, 8 on both sides (6 and 2), for the pumpkin seed, associations that would normally be expected. Then a co-occurrence of 4 for water; of 2 for a large variety of edible food like cassava, yam, vegetables, fruit; and of 1 for jícara, the pumpkin hull still used all over Yucatán as a kitchen container for stews and soups, and specially, for drinking water. Its multifunctionality goes as far as to using a dried and hardened pumpkin to pour water on laundry or floors when washing them (see 3.3.6 below).

Figure 17: Pumpkin context (enlarge this figure here)
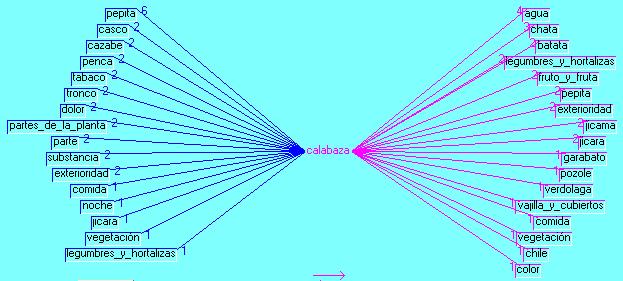
Figure 18: Pumpkin Star graphic [41]
Tropes pops out 23 equivalents for chili. Figure 19 shows twice the term ají, as an equivalent for chili. The term ají undoubtedly was a word more familiar to CIUDAD REAL (ARZÁPALO, 1995) as it comes from Spain and before from North Africa. But our Franciscan will be hearing the term chile, "chili" in English, always used through all Yucatán as well as through Indo-Afro-Latin America. Figure 20 has a multiple branches with 8 co-occurrences for food on each side of the Star, 3 for ají (in the whole text) and 1 for terms referring to local products: cocoa beans, pozole (soup made with fermented corn), drink, plants, and aromatic herbs.

Figure 19: Hot pepper or chili context (enlarge this figure here)
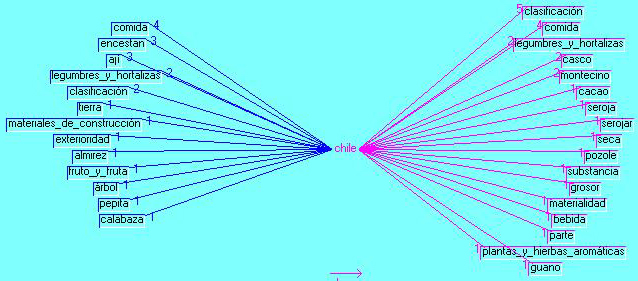
Figure 20: Hot pepper or chili Star graphic [42]
In short, via the Star graphics we have learned that the lexical equivalents showing the highest numbers not only reflect affinities and similarities between food, drink, and other semantic items, but they also point out which of the words were more common in the everyday discourse recorded by CIUDAD REAL (ARZÁPALO, 1995). Second, the co-occurrences revealed by Tropes between hypertextual elements, as well as the contexts where they occur, provide illustrations of the precise meaning of words referring to food and drink in those times. Third, through the linguist processing that is possible through the software we have a better knowledge, not only of XVIth century Maya culture, but also of the edible natural resources. Fourth, we can surmise that the diet consisted mainly of fruit, cereals (especially corn), diverse vegetables, pumpkin and hot pepper, and that it was very similar to the diet found to-day in most towns of the Yucatan countryside. Fifth, according to the equivalences, most of the plants are not edible because they are not tasty to the Maya. Anyhow they have used them as medicinal plants and still do. Sixth, there are 31 references to diverse small size animals, 30 for vegetables, and 108 for cereals, with an outstanding 109 for tropical fruit. These data reflect today's reality observable in the Maya countryside. Seventh, the only drink quoted by CIUDAD REAL (ARZÁPALO, 1995) in the Star graphic is water. [43]
Trying to get information of a new sort on food and drink, we now switch to the Spheres graphic. This hypertextual graphic shows proportions and distances between hypertextual words and fields. Proportions and distances in the Spheres graphic are represented by the relative volume of icons and by the relative space between the orbits of the Spheres. [44]
In other words, strictly speaking, there is not a numerical representation as in the Star graphic: the largest Spheres correspond to the terms which appear more frequently and which are more important. To get the number of equivalents we click on Used references (outside the graphic), and Tropes will provide a global number with no distribution between each couple of Spheres as the Star graphic did. At a glance, we notice that the more distant the Spheres, the fewer hypertextual relations between terms, and, conversely, the closer the Spheres, the more hypertextual relations between them. If we click on one of the Spheres, we will be taken to a different Spheres graphic with a different central term, the one we just clicked on. [45]
Therefore, the main difference between both graphs resides in the fact that the Spheres' graphs require a bit of work to be read and interpreted. In addition, with the Spheres graph the reader must pay more attention to the relative dimensions and distances between the global system of hypertextual spheres. The Spheres graph is a merely spatial graph, a planetary graph; while the Star graph is a precise and punctuated graph offering numerical details between each couple of hypertexts, without displaying neither distances nor dimensions. [46]
We obtain 20 equivalents for corncob. The number does not show in the graph but in the left column if we click on the label Used references. Besides, it is global and does not have the distribution precision offered by the Star graphic. Figure 21 shows the context for this item. Figure 22 shows the corncob Sphere covering part of a bigger one, that is, cereals, confirming the semantic class which comprehends corncob.

Figure 21: Corncob context(enlarge this figure here)

Figure 22: Corncob Sphere graphic (enlarge this figure here) [47]
At the same time, the graphic shows vegetables as the nearest semantic field, the one which has more hyper-relations with corncob. A little further to the left we see a big blue Sphere, referring to parts of the plant. This way our colonial dictionary is being accurately e-redesigned by means of icons, graphics and colors emerging from hypertextuality. [48]
For atole (Figures 23 and 24), the delicious and nourishing everyday drink of our whole country in those times as well as nowadays, made from corn adding a bit of chocolate, vanilla or cinnamon; Tropes finds 14 equivalents for it. In the hypertextual graphic cereals appear as well before than after atole. And we should remember that after a 3D-clicking on any of the Spheres, Tropes can take us to another hyper-textual Spheres graphic related to the previous Spheres.

Figure 23: Atole context (enlarge this figure here)
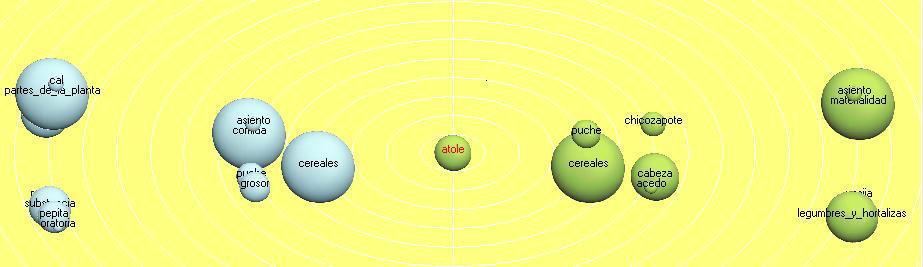
Figure 24: Atole Sphere graphic (enlarge this figure here) [49]
The term pepitas, "pumpkin seeds," runs all over the text with 12 equivalents. The nearest Spheres are, of course, pumpkin, then food, as shown in Figures 25 and 26.

Figure 25: Pumpkin seed context (enlarge this figure here)

Figure 26: Pumpkin seed Sphere graphic (enlarge this figure here) [50]
Tropes brings up 12 equivalents for the term ají. Its context appears in Figure 27. Its Sphere appears in Figure 28 near hot pepper (also chili in English) and near cereals, because when cooking and eating we add ají to corn. Nevertheless it is pertinent to point out once again that, in actual Standard Mexican Spanish we have substituted the term ají with the word chile, both referring, in English, as said before, to "hot pepper" or to "chili." And it does not surprise us that our friar had a quite singular way to describing the world of "hot food," I am assuming that he had not tried it very often before getting to our Continent. I suppose the term ají might have been more familiar to him, as it was the term used in his native land and still is. All over Mexico, and particularly in all Yucatán, I have never ever heard people use the term ají, although quite a few might understand its meaning.

Figure 27: Ají context
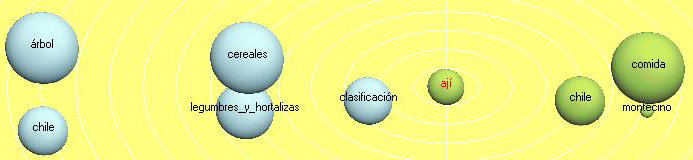
Figure 28: Ají Sphere graphic [51]
Again, whereas ají represents for us a synonym of chile, Tropes stresses that CIUDAD REAL (ARZÁPALO, 1995) used and/or heard both terms. He recorded ají, which was and still is a term used in Spain as well as in Morocco and parts of North Africa. Most probably he did not know the term chile, before getting to Yucatán. So, amazing bits of ethno-history can be assumed and deduced by means of the Tropes graphics. [52]
Tropes finds 12 lexical equivalents for sugar cane. Figure 29 illustrates that the linguistic Spanish form, caña, does not have any synonymic form. Figure 30 indicates the nearest Spheres to sugar cane are cereals, parts of plant and, of course, fruit.

Figure 29: Sugar cane context (enlarge this figure here)

Figure 30: Sugar cane Sphere graphic (enlarge this figure here) [53]
Tropes pops up with 11 equivalents for cocoa beans, a seed considered sacred by the Mayas and through all Mesoamerica. Prepared as a tasteful and energetic drink, cocoa beans formed part of most sacred rituals as represented in quite refined ceramic scenes. Figures 31 and 32 indicate the term appears mainly near cereals.

Figure 31: Cocoa beans context (enlarge this figure here)
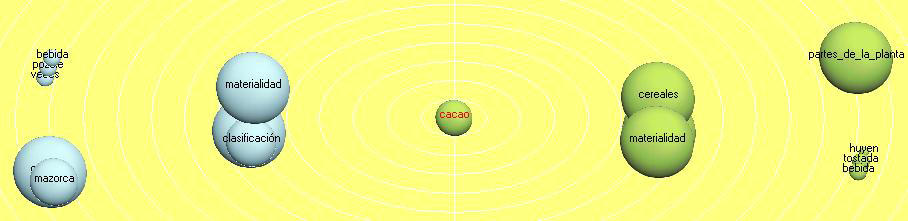
Figure 32: Cocoa beans Sphere graphic (enlarge this figure here) [54]
Tropes signals 10 equivalents for the Panhispanic term zumo, "fruit juice," which we barely use only in cooking books. Instead, we use the term "jugo," Yucatán being a country for an everyday jugo de china also sometimes called jugo de naranja. Again, getting back to our Franciscan, he might only have used zumo, a Spanish term he brought, and he might have taught it to the Mayas, but the descendants rather picked up the term jugo. In Figure 33 we show some of its context and in Figure 34 we can see the term appears close to earth and parts of plant Spheres.

Figure 33: Fruit juice context (enlarge this figure here)
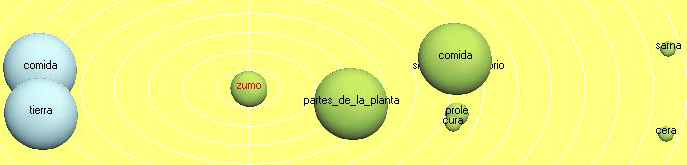
Figure 34: Fruit juice Sphere graphic [55]
Tropes indicates 10 equivalents for the word Hen. Figure 35, which corresponds this time to the whole corpus, talks about some ways of cooking the bird in a hot sauce stew, or baked under the ground. Figure 36 pictures the Spheres nearest it. On the left and the right appear Spheres corresponding to the hot sauce chilmole, carefully prepared with finely smashed hot peppers and tomato or any vegetable at hand for making a delicious stew with hen or pork. This last one showing on the porcs Sphere to the left. A bit further we find yam and fat for cooking. On the right the nearest Spheres are the chilmole we just mentioned and large Spheres for fruits and vegetables, which we now know are quite prominent in Maya diet. It could be said that Figure 36 by itself represents a mostly iconic menu.

Figure 35: Hen context (enlarge this figure here)

Figure 36: Hen Sphere graphic (enlarge this figure here) [56]
Tropes pops up with 9 equivalents for the term pap or mush. Figure 37 offering all its contextualization. Similarly to the term ají we saw before, the term puche is rarely used nowadays in Mexico in the sense of pap. One is more likely to hear instead papilla or, when generalizing all sorts of paps, the term atolito is fairly extended, the diminutive morpheme, -ito, signifying here "not quite a pure atole." So, atolito does not have to refer only to a corn pap. In the graph, pap, as expected, appears near atole, that is corn atole in the Calepin's text, the favorite pap. All things being equal, once again, we deduce that CIUDAD REAL registers and tries to introduce in Yucatán a term brought directly from Spain, that is puche, "pap." In Latin America it covers just some regions, mainly in the Southern part of the continent. In Mexico it is not used but might be known. Nevertheless when hearing it or reading and analyzing it as we are doing now, we can only understand it when we take into consideration the context. Figure 38 illustrates all the proximity relations between the most the important terms.

Figure 37: Pap context (enlarge this figure here)

Figure 38: Pap Sphere graphic (enlarge this figure here) [57]
In the last entries, I have demonstrated how the Spheres graph is useful for illustrating, in a non-numerical fashion, the hyper-textual relationships between words of the Maya culture regarding bromatology. The largest Spheres correspond to the more important relationships and the smallest to the less important ones. The shortest distance from one Sphere to the central one implies that they both have many hypertextual relations. When clicking on any Sphere, we can then navigate to another set of relations, proportions and cultural characteristics. It derives that the more distant the Spheres the fewer relations between terms. [58]
The Spheres entries shown after clicking on the label of departure for the experiment, Used references, happen to correspond to the lexical items contained, and comprehended in larger Spheres. Similarly, the Star graphs also display a logically more extended universe. Under the label Used references, Tropes displays a global number of equivalents while the Star graphs showed the precise distribution of co-occurrences between hypertexts. [59]
Logically speaking, a couple of the Spheres instances have made us go back to XVI century vocabulary, used by the friar and the Mayas, but we do not use them anymore nowadays here or in the Maya land. These small details document important aspects of Mexican Spanish language history and development. [60]
I would suggest that Tropes, via both graphs, has shown us not only quantitative data but lexical, semantic and discursive special features, especially for diachronic lexicology and dialectology. The software illustrates the uses of the Friar idiolect, which in principle reflects the Spanish used during the Golden Century or Siglo de Oro, at least by the very erudite ones as CIUDAD REAL. [61]
In this section, I add to the previous written corpus, images (note here that letters are also considered images, as explained in Section 1.1.4), and particularly, usual figurative images, mainly pictures. This way I will obtain a highly mixed or multimodal corpus (VAN LEEUWEN, 2005) on bromatology. Also, in contrast to the preceding corpus and to increase its variety, I select the lowest co-occurrences displayed when clicking on the label Used references at the bottom of Tropes lists. I assume that they represent the rarest and most difficult food to get and to prepare, even for the most sophisticated Mayans of those days. As the Three Body Theory should bring up new ways of looking at diverse realities, I did some research on the Internet to find which of these low co-occurrences food are still eaten in Yucatán. Enliving, recovering, refreshing food through modern pictures creates other fragments of signification and resignification, complementing the very textures of meaning, although the images themselves do not display any alphanumeric representation, as the two-layered corpus analyzed above. These third figurative lexias being simply recent pictures of food and drink found in Yucatán and in www-hyperlinks, I will be labeling them by means of some of the original Calepin's written lexias above. Adding this can tell us which of the undoubtedly natural, definitively not processed, and nourishing food has been carefully prepared through centuries by Maya, and subsequently Mexican culture, and perhaps many other cultures in the world. Since these food and drinks are still popular with the descendants of the early State Cities and Pyramids, perhaps, by showing the next food and drink images the taste and flavor may emerge in some readers: de la vista nace el amor. To select the colored images I looked for the very lowest numbers at the bottom of the list displayed when clicking on the label Used references to the left and outside both graphs. This way I was able to systematically locate the rare dishes and drinks of Maya culture, assuming that the rarest could be the most sophisticated and refined. [62]
3.3.1 Strawberry, sapodilla fruit and prunes
Tropes brings up 7 equivalents for strawberry, 7 for sapodilla and 4 for prunes (Figures 39, 40 and 41 respectively). It is important for dialectal and intercultural variants to point out that the term frutilla, used by CIUDAD REAL (ARZÁPALO, 1995) instead of the actual Panhispanic term fresa, refers to-day to the strawberry but only in Argentina, neither in Mexico nor in the Maya land. We might use it, very rarely, but just to designate a small fruit.

Figure 39: Strawberry

Figure 40: Sapodilla fruit

Figure 41: Prunes [63]
Now let us notice that wine offers 6 equivalents. As raisins have not been registered in the Calepin (perhaps they didn't grow that well in the tropical climate), we deduce that wine might have travelled from Spain or, most possibly, from the actual state of Jalisco, then called Nueva Galicia, where HERNÁN CORTÉS had started planting vine. [64]
And with fewer equivalencies, 5 each, the terms salt and pork appear on the same list. Needless to say that one of the favorite dishes in Yucatán is the cochinita, that is flavored with recado colorado, also called achiote (Figure 42), a very red powder obtained after grinding salt and different Yucatecan hot peppers.

Figure 42: Achiote [65]
3.3.4 Maguey, pursulence, chilmole
Tropes signals the term maguey (4), a special agave planted throughout the country (Figure 43), from which an alcoholic and very popular drink, the pulque, is extracted. It is important to notice that maguey is no longer planted in Yucatán. It also signals verdolaga (4), "pursulence" (Figure 44) and chilmole (4), "hot pepper sauce" (Figure 45), also sometimes called mole, made with numerous ground chilis, tomato, any vegetable at hand and cocoa beans. Pursulence, chilmole and chicken are served together, mainly around Christmas festivities, in Yucatán and across the whole country.

Figure 43: Maguey

Figure 44: Pursulence

Figure 45: Chilmole [66]
Tropes pops up 2 and 1 co-occurrences for nancé, a very sweet Yucatecan fruit (Figure 46); for the very colorful pitahaya (Figure 47); and for chaya, a Yucatecan kind of spinach, also full of vitamins and minerals and consumed almost everyday in pies, soups, stews, omelets over the Peninsula (Figure 48). A delicious and refreshing juice is made of chaya (Figure 49).

Figure 46: Nancé

Figure 47: Pitahaya

Figure 48: Chaya

Figure 49: Chaya juice [67]
As you might have guessed, when visiting Yucatán one eats and finds all sizes pumpkins, "calabaza," with their different colors, shapes and species, lying and growing all over the ground. There is no waste, as in most of Amerindian countries, Mayas let the empty nuts dry and will use them as containers for pouring water, for drinking water, for eating soups and stews. The Mexican name for the containers is jícara and the Maya one lek (Figure 50). Tropes points out for jícara a very low co-occurrence of 1 (see 3.1.8 above).

Figure 50: Jícara [68]
I have presented a potentially unending bundle of hypertextual terms, lexias, images and commentaries that are related to edible products directly supplied from the surrounding nature of the Peninsula. [69]
This presentation of food knowledge of the Maya illustrates how sophisticated and creative the Maya people were. This discussion also demonstrates how their culture and religion is based on a deep knowledge of nature and a profound respect for the fauna and flora present in their everyday lives. [70]
The linguistic material derived from this study is composed of numerous Maya bromatology descriptions and of a good amount of botanical items, as well as of a varied cluster of registers concerning taste and flavor. Nevertheless this study is likely to reflect only a small part of CIUDAD REAL's (ARZÁPALO, 1995) linguistic mission in Yucatán which consisted mainly of describing culture and nature as an excellent chronicler of his times would do. [71]
In undertaking this work, I hope I have added new paths for diachronic and/or intercultural studies. In doing so, a combination of data about linguistics, discourse, history, ethnography have emerged from the analysis. [72]
The complexity method of research and the multilayered corpus construction of hypertexts and hyperimages has been possible above all by using the simple and easy Tropes, a handy and didactic software for qualitative and quantitative content analysis. [73]
Deconstructing the dictionary for establishing a three-body corpus and applying it to a bromatology e-semantics has produced a new way of reading, writing, displaying and interpreting culture and enhancing ethno-ecological values of traditional societies, which may come someday to the rescue of modern societies. [74]
I wish to thank very specially César A. CISNEROS who, with his habitual enthusiasm, has connected and encouraged Latin American Qualitative researchers with others from around the world.
1) The Calepino de Motul was written by Antonio de CIUDAD REAL circa 1600. ARZÁPALO has added in his 1995 computarized edition the orthographic systematization of Maya, and modernization of Spanish; an index of Maya words and their localization; reverse index of Maya; grammatical, semantic and pragmatic classification of the lexical entries; scientific classification of fauna and flora terms; addition of the missing Spanish translations in the original document; a list of Latin expressions, samples of concordances and paleographic transcription (ARZÁPALO, 1995). <back>
2) The folio (recto/verso) number, and the entry number are indicated after the page number —exactly as they have been added by ARZÁPALO in the modern edition. <back>
Arzápalo, Ramón (1995). Calepino de Motul. Diccionario Maya-Español, por Antonio de Ciudad Real (3 vols., computarized ed.). México: UNAM.
Barthes, Roland (2002). Oeuvres complètes 2: livres, textes, entretiens 1962-1967. Paris: Seuil.
Briggs, John & Peat, David (1989). A turbulent mirror. An illustrated guide to chaos theory and the science of wholeness. New York: Harper and Row.
Fielding, Nigel & César A. Cisneros-Puebla (2009). CADQAS-GIS convergence. Toward a new integrated mixed method research practice? Journal of Mixed Methods Research, 3(4), 349-370.
Ghiglione, Rodolphe; Landré, Agnès; Bromberg, Marcel & Molette, Pierre (1998). L'analyse automatique des contenus. Paris: Dunod.
Landlow, George (2006). Hypertext 3.0. Critical theory and new media in an era of globalization. Maryland: The John Hopkins University Press.
Lema, Rose (2002). Los "diálogos" del Calepino de Motul: exploraciones en la historiografía de la otredad. Munich: Lincom-Europa.
Lema, Rose & Abascal, Rocío (2011). "India(s)," "Indio(s)" del Calepino de Motul: redes hipertextuales semiautomáticas. In César A. Cisneros Puebla (Ed.), Análisis cualitativo asistido por computadora. Teoría e investigación (pp.99-132). México: UAM/Porrúa.
Mandelbrot, Benoît (1975). Les objets fractals: forme, hasard et dimension, survol du langage fractal. Paris: Flammarion.
Morin, Edgar (2005). Introduction à la pensée complexe. Paris: Seuil.
Moscarola, Jean (1994). Les actes de langage: protocoles d'enquêtes et analyse des données textuelles. Communication au Colloque Consensus Ex-Machina. Paris.
Poincaré, Henri (1908). Science et méthode. Paris: Flammarion.
Popova, Maria (2010) Sir Ken Robinson on creativity and changing educational paradigms, http://www.brainpickings.org/index.php/2010/10/21/sir-ken-robinson-rsa/ [Accessed: February 27, 2012].
Prigogine, Ilya & Stengers, Isabelle (1979). La nueva alianza: metamorfosis de la ciencia. Madrid: Alianza Editorial.
Rovira, Cristòfol (2008).Technology watch and competitive intelligence for SEM-SEO, http://www.hipertext.net/english/pag1032.htm#2 [Accessed: February 27, 2012].
Strogatz, Steven H. (2000). Nonlinear dynamics and chaos. With applications to Physics, Biology, Chemistry, and Engineering. Boulder: Westview Press.
van Leeuwen, Theo (2005). Introduction to social semiotics. New York: Routledge.
Vilar, Pierre; Chaunu, Pierre; Lapeyre, Henri; Devèze, Michel; Canavaggio, Jean-François & Guinard, Paul (1965). L'Espagne au temps de Philippe II.Le temps des Hidalgos. Paris: Hachette.
Rose LEMA is a Linguistics and Anthropology professor at the Universidad Autónoma Metropolitana in Mexico City. Her PhD dissertation deals with issues on Maya Culture. Her actual research method has a base in prospective convergence of the following fields: Chaos theory, complexity, creativity, transdisciplinarity, qualitative analysis, art, cultural studies, humanities and social sciences, semiotics, discourse analysis, ethnography, ethnoecology, postmodern anthropology. She has published books and articles in Germany, France and Mexico. She has given many presentations at conferences in Australia, Europe and the Americas.
Contact:
Rose Lema
Departamento de Teorías y Procesos del Diseño, División de Ciencias de la Comunicación y Diseño
Universidad Autónoma Metropolitana-Cuajimalapa
Av. Constituyentes #1054; 11950
México D.F.
Tel.: 52+55+55-89-01-33
E-mail: roselema09@gmail.com
Lema, Rose (2012). Hypertextuality, Complexity, Creativity: Using Linguistic Software Tools to Uncover New Information about
the Food and Drink of Historic Mayans [74 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 13(2), Art. 21,
http://nbn-resolving.de/urn:nbn:de:0114-fqs1202215.

Creative Commons Attribution 4.0 International License