Volume 16, No. 2, Art. 8 – May 2015
A Software-Assisted Qualitative Content Analysis of News Articles: Example and Reflections
Florian Kaefer, Juliet Roper & Paresha Sinha
Abstract: This article offers a step-by-step description of how qualitative data analysis software can be used for a qualitative content analysis of newspaper articles. Using NVivo as an example, it illustrates how software tools can facilitate analytical flexibility and how they can enhance transparency and trustworthiness of the qualitative research process. Following a brief discussion of the key characteristics, advantages and limitations of qualitative data analysis software, the article describes a qualitative content analysis of 230 newspaper articles, conducted to determine international media perceptions of New Zealand's environmental performance in connection with climate change and carbon emissions. The article proposes a multi-level coding approach during the analysis of news texts that combines quantitative and qualitative elements, allowing the researcher to move back and forth in coding and between analytical levels. The article concludes that while qualitative data analysis software, such as NVivo, will not do the analysis for the researcher, it can make the analytical process more flexible, transparent and ultimately more trustworthy.
Key words: qualitative content analysis; method; news articles; NVivo software; qualitative data analysis software (QDAS); computer-assisted qualitative data analysis (CAQDAS)
Table of Contents
1. Introduction
2. Literature Review
2.1 Qualitative content analysis (QCA)
2.2 Software-assisted qualitative data analysis
3. A Step-by-Step Approach to Software-Assisted Qualitative Content Analysis of News Articles
3.1 Step 1: Selecting and learning the software
3.1.1 Getting to know the software: Sample project, literature review
3.2 Step 2: Data import and preparation
3.3 Step 3: Multi-level coding
3.3.1 Coding: Inductive vs. deductive
3.3.2 Context unit (node)
3.4 Step 4: Visualizing data and presenting findings
4. Ensuring Trustworthiness and Reliability of Findings
5. Overcoming Limitations
6. Outlook
The purpose of this article is to illustrate the use of qualitative data analysis software (QDAS) as a research tool in implementing qualitative content analysis. The article offers a detailed description of QDAS applied to the analysis of international press coverage of a country's environmental performance linked to carbon emissions. Thus, while software-assisted qualitative content analysis of news articles is at the center of the approach suggested here, we include the steps prior to and following the actual analysis and coding, as they form a crucial part of the overall research process. [1]
Guided by a qualitative, mild social constructionist research paradigm, the research described here was part of a larger study that set out to determine the perceived credibility and potential vulnerability of New Zealand's global environmental positioning as a clean, green food exporter and 100% Pure tourist destination (see the Official Site for Tourism New Zealand). The study followed the argumentation that, as calls for environmental responsibility are growing louder, the global competitiveness of nations and places increasingly depends on their ability to convince audiences both domestic and overseas of their environmental credentials and integrity. As a main carrier of country reputation and channel through which place image travels, the mass media are known to play a crucial role with regard to the perceived legitimacy and credibility of a place's brand positioning (ANHOLT, 2010; AVRAHAM, 2000; AVRAHAM & KETTER, 2008; GOLD, 1994; HALL, 2002). Moreover, media coverage can turn remotely located places into areas of possible concern for people living thousands of kilometers away (CHOULIARAKI, 2006; COTTLE, 2009a; 2009b). [2]
The research described in this article sought to determine New Zealand's environmental reputation overseas through an analysis of a total of 230 articles published in Australian, UK and US quality daily newspapers during a five year period (2008-2012), focusing on coverage of New Zealand (NZ) in connection with carbon emissions as a proxy for its environmental performance. With regard to NZ's perceived environmental credibility, findings indicate that, contrary to a generally favorable perception at the beginning of the study period in 2008, by the end of the year 2012 NZ was no longer in the spotlight as an environmental leader with regard to carbon emissions. Instead, it was largely ignored in the global climate change arena. Judging from Australian media coverage, NZ's environmental reputation remained largely intact there, while in the UK and the US isolated unfavorable articles could be first signals of a shift towards wider negative perceptions. The study concludes that, in the absence of favorable coverage needed to maintain the country's image and reputation, NZ's global environmental positioning had become more vulnerable. Of particular interest for, and the key focus of, this article, however, is how software was used to support the process of qualitative content analysis. [3]
In the following we offer a brief review of academic literature on qualitative content analysis and software-assisted qualitative data analysis, two research methods that have gained much popularity in recent years. We then move on to a step-by-step illustration of the software-assisted analysis process, from choosing the right software and learning how to use it, to data import and preparation, coding and analysis, and visualization of research findings. We hope that this detailed description will assist those not yet familiar with QDAS-assisted qualitative or mixed methods analysis of textual data in gaining a realistic impression of the method's advantages and limitations. [4]
2.1 Qualitative content analysis (QCA)
Unlike quantitative content analysis with its long history as "a research technique for the objective, systematic and quantitative description of the manifest content of communication" (BERELSON, 1952, p.18), QCA is context-specific (SCHREIER, 2012): it treats context as "central to the interpretation and analysis of the material" (KOHLBACHER, 2006, §80). QCA moves away from the focus on objectivity as maintained by traditional quantitative content analysis (BERELSON, 1952; BRYMAN, 2012; HOLSTI, 1969), in an attempt to allow for "the subjective interpretation of the content of text data" while maintaining "the systematic classification process of coding and identifying themes or patterns" (HSIEH & SHANNON, 2005, p.1278). [5]
QCA is both systematic, flexible, and reduces data. As SCHREIER (2012, p.8) observes, the method is systematic in the sense that "all relevant material is taken into account; a sequence of steps is followed during the analysis, regardless of your material; and you have to check your coding for consistency (reliability)." QCA is further flexible in that the coding frame is adapted to the material and research questions at hand (SCHREIER, 2012). Furthermore, data reduction occurs through limiting analysis to relevant parts. [6]
QCA keeps transparency as one of the main advantages of classical content analysis (BRYMAN, 2012) intact, while attempting to synthesize two contradictory methodological principles: openness and theory-guided investigation (GLÄSER & LAUDEL, 1999). In other words, QCA seeks "to preserve the advantages of quantitative content analysis as developed within communication science and to transfer and further develop them to qualitative-interpretive steps of analysis" (MAYRING, 2000, §2). It aims for "empirical, methodological controlled analysis of texts within their context of communication, following content analytical rules and step by step models, without rash quantification" (§5). [7]
It has to be noted that maintaining a strict distinction between quantitative and qualitative content analysis is not always useful or possible. For example, as KRIPPENDORFF (2013) points out, "all reading of texts is qualitative, even when certain characteristics of a text are later converted into numbers" (p.22). Also, qualitative content analysts are not per se opposed to incorporating quantitative elements and counting, as our own study shows, and as evident in the variety of approaches to QCA illustrated by SCHREIER (2014) and HSIEH and SHANNON (2005), among others. As KUCKARTZ (2014, p.3) points out, "both a quantitative analysis of qualitative data, as well as a qualitative analysis of quantitative data, are possible. Thus, there is no reason to suspect a deep divide between the qualitative and quantitative perspectives." For instance, subject to the research question, QCA can include quantitative elements such as word frequency analysis (MAYRING, 2000). In other words, QCA allows a focus on quantitative aspects of the research data that are most relevant to the research question (SCHREIER, 2012). [8]
Arguably the best known approach to QCA to date was developed by German scholar Phillip MAYRING in the 1980s, which has now become standard literature, particularly in his native, German-speaking scientific community (KOHLBACHER, 2006). One characteristic of MAYRING's approach is that coding criteria are developed based on research questions and theoretical background, while categories are developed inductively through close reading of the material, which are then checked against and refined in accordance with the previously established criteria (MAYRING, 2000). [9]
MAYRING further distinguishes between three types of QCA: summary, explication and structuring, which can be carried out either independently or in combination, depending on the particular research questions (see also KOHLBACHER, 2006; TITSCHER, MEYER, WODAK & VETTER, 2000): Essentially, summary refers to a reduction of the material to the essential content to make it more manageable, whereas explication focuses on explaining, clarifying and annotating the material. Structuring, a procedure similar to classical content analysis, seeks to extract a particular structure from the material in question. Among those three approaches, summary is perhaps the closest to the software-assisted approach to QCA described below. However, we concur with KOHLBACHER (2006) and GLÄSER and LAUDEL (1999) that as a young discipline, there is still ample room for further developing QCA, both in terms of methodological and practical advances. For this article, we are particularly interested in the uses for and potential of conducting content analysis with the assistance of specifically designed software. [10]
2.2 Software-assisted qualitative data analysis
Numerous scholars have discussed the advantages and limitations of using qualitative data analysis software packages (QDAS, also referred to as CAQDAS) in academic research. Proponents hail them for faster and more efficient data management (BAZELEY, 2007, 2009, 2011; BRINGER, JOHNSTON & BRACKENRIDGE, 2006; LEWINS & SILVER, 2007; MANGABEIRA, LEE & FIELDING, 2004; MARSHALL, 2002; RICHARDS, 2002; RYAN, 2009; WELSH, 2002), their ability to handle large volumes of data (BERGIN, 2011; BOURDON, 2002; MacMILLAN, 2005; ROBERTS & WILSON, 2002) and to reduce complexity (SCHÖNFELDER, 2011). Others have stressed their ability to improve methodological rigor (RICHARDS, 2002), consistency (BERGIN, 2011) and analytical transparency (BRINGER et al., 2004, 2006; COUSINS & McINTOSH, 2005; JOHNSTON, 2006; RYAN, 2009; THOMPSON, 2002; WELSH, 2002). BAZELEY (2007) and LEWINS and SILVER (2007) both provide detailed descriptions of how software packages support qualitative research as a tool for managing and organizing data, managing ideas, querying data, graphically modeling ideas and concepts, and reporting from the data. Moreover, the software's searching and modeling tools allow making data visible in ways not possible with manual methods, allowing for new insights and reflections on a project (SCHREIER, 2012; SICCAMA & PENNA, 2008). [11]
Critical voices, on the other hand, lament the high financial cost of some software packages and the considerable time and effort required to learn them (BERGIN, 2011; THOMPSON, 2002), and that they might entice the researcher to put too much trust in the tools provided, thereby potentially generating unrealistic expectations (MacMILLAN, 2005; MacMILLAN & KOENIG, 2004; MANGABEIRA et al., 2004). Others have pointed out that the relative ease of software-assisted coding can reduce critical reading and reflection (BAZELEY, 2007), and that software overuse can lead to "coding fetishism" (RICHARDS, 2002). A key concern in this regard seems to be that computer software will mechanize qualitative analysis and thus compromise the exploratory, interpretative character of most qualitative research (BAZELEY, 2007). However proponents such as RYAN (2009) note, it is up to the researcher to decide how and which data to code and to make sure software use suits the theoretical framework, context and research questions. After all, computers "cannot resolve essential dilemmas of inquiry, nor eliminate the important role of creativity ... and will not ultimately make the work less challenging" (COUSINS & McINTOSH, 2005, p.597; see also RYAN, 2009). Arguably, reservations regarding insufficient analytical flexibility are linked to a lack of transparent, clear descriptions of QDAS-use in qualitative research (MacMILLAN, 2005; MacMILLAN & KOENIG, 2004). In fact, several scholars have denounced the often lacking description in methodology chapters and research papers of how software was used throughout the analytical process (for example, JOHNSTON, 2006; KIKOOMA, 2010; THOMPSON, 2002). [12]
There is clear consensus that the choice/use of QDAS in the first place largely depends on the methodology and methods employed (MacMILLAN, 2005; MacMILLAN & KOENIG, 2004). However, limitations arise when researchers who do decide to use a QDAS software perceive it as a handy utensil or convenient tool, and the chosen software does not become a fully integrated part of the very design of the research project (BOURDON, 2002). On the other hand, as RYAN (2009) stresses, while software does aid the analysis of qualitative data, it should not be seen as a separate process from the research methodology. Rather, it has to be used in a way that supports and enhances the methods and methodology chosen for a specific study. [13]
In this article we address two gaps in the extant literature regarding QDAS. First, as noted above, there is little published work that fully describes the methodological process of using the software to facilitate analysis. Second, and most significantly for this article, there is also little published work with a specific focus on QCA. A key difference between QDA in general and QCA in particular is that the first focuses on the significance of observations, aiming for interpretations that do justice to a whole body of texts, whereas the second takes a somewhat more pragmatic approach by including quantitative aspects. Unlike data such as interviews, mentions of specific keywords within news texts—such as New Zealand in connection with carbon emissions—are limited to one paragraph and not necessarily linked to what follows or precedes it. Furthermore, the quantitative aspect of QCA proved ideal for answering the research questions concerning changes of the amount of coverage over time and how it differed across countries, offering valuable clues as to the salience and perceived newsworthiness of New Zealand's environmental performance in those countries. [14]
Moreover, as we have noted, while QDA due to its highly interpretive nature suits a sole researcher, the somewhat more rigorous, structured approach of QCA pays off when several researchers are involved in the research project and where double coding is employed as a means to ensure analytical reliability. By focusing on how to use software in conducting QCA, rather than QDA, the article aims to shed light on how it can help overcome QCA-specific challenges, such as accommodating the double coding and comparison of codes by different researchers. As KRIPPENDORF (2013) notes,
"faced with larger volumes of text and working in research teams, content analysts have to divide a body of texts into convenient units, distribute analytical tasks among team members, and work to ensure the consistent application of analytical procedures and standards. For these reasons, content analysts have to be more explicit about the steps they follow than qualitative scholars need to be" (pp.88-89). [15]
The illustration of software-assisted QCA offered below is a response to the concerns/ critiques above. However, this illustration does not neatly or strictly adhere to previous approaches, namely MAYRING's. Rather, the purpose is to offer a more practical account of QCA as used in our research, to illustrate how our analysis was assisted by a specific software package, NVivo. While the approach to software-assisted QCA described in this article shares MAYRING's predominant concern to develop a research design flexible enough to allow for quantitative and qualitative elements—as required by the research questions, it differs on various accounts. For example, while his approach considers the coding frame crucial to the method (SCHREIER, 2012), our emphasis here is on the multi-level coding process. [16]
3. A Step-by-Step Approach to Software-Assisted Qualitative Content Analysis of News Articles
Drawing on the steps proposed by JÄGER and MAIER (2009) and BAZELEY (2009), the following sections provide a detailed account of our QDAS-assisted analysis, namely: 1. selecting and learning the software, 2. data import and preparation, 3. the top-down and bottom-up coding procedure, and 4. visualizing data and presenting results. In presenting this account, we draw on our direct experience with NVivo 10, which was the software that we used for our analysis of news articles, described above. [17]
3.1 Step 1: Selecting and learning the software
The first step of our software-assisted analysis was to select the software. This is easier said than done, as the growing list of available options, such as MaxQDA, NVivo or dedoose,1) can be daunting, particularly as each option comes with its specific advantages and limitations. During a comparison of software options, it is important to keep in mind that the software cannot provide the researcher with a theoretical or analytic framework. It can "merely" provide tools to facilitate data management and analysis (LEWINS & SILVER, 2007). Furthermore, selection must also take into account practicalities, such as whether or which software programs are taught at your institution (ibid.) and the license fees. [18]
In our study, we needed a software package that would allow us to easily collaborate, and to conduct the kind of analysis described further on. Among the various options available, NVivo software suited our needs best, particularly since paying for the license fee was not an issue, and because on-site training was available at our institution. [19]
We acknowledge that high license fees can be a serious drawback for those unable to access a software package such as NVivo through an institution, or with limited financial resources, in which case open source solutions such as recently developed QCAMAP are perhaps as a better option. However, price is only one of the factors to consider. From our experience, since we had little knowledge of QDAS prior to commencing our study, access to learning support, such as training, guide books and video tutorials, was a key criterion, together with the option to learn from a pre-installed sample project. Clearly, this aspect should not be underestimated, as the initial effort required to learn and master the tools offered by QDAS can pose a difficult hurdle in conducting software-assisted qualitative research, as noted, for example by BERGIN (2011) and MANGABEIRA et al. (2004). [20]
Once analysis has started, availability of technical support is another aspect worth considering, as a lack of support can be a serious drawback in conducting QDAS-assisted literature reviews or qualitative content analyses of the type presented in this article. Computers and software can crash—we experienced both—and files can get lost or become inaccessible. This is where packages like NVivo really pay off, as opposed to open source software. We also recommend frequent backups and the use of real-time synchronization cloud storage services, such as Dropbox, as those can avert worst-case scenarios of data loss. An alternative to this would be to use software such as QCAmap and dedoose, which are entirely cloud based, allowing access to a research project from any computer with Internet access. [21]
Additional factors that need to be taken into consideration at the stage of choosing the software are whether specific functionality is required. For example, NVivo (Version 10) comes with a web browser extension (NCapture) through which social media data, such as Twitter tweets and public Facebook messages, can be collected and analyzed. While not immediately relevant for the research presented here, we considered this functionality of high potential for a follow-up study. [22]
3.1.1 Getting to know the software: Sample project, literature review
With regard to learning the chosen software, we followed the recommendation put forward by various scholars, to get acquainted with QDAS by using it for a literature review, as the process involved is very similar to analyzing qualitative data (DiGREGORIO, 2000; LAVERY, 2012). This can be particularly useful for masters or doctorate theses where literature reviews are extensive and require a considerable amount of time and in depth understanding of the themes, such as the one developed as part of this research project. A key advantage of conducting literature reviews through the NVivo software is that, because everything is stored in one big file, this can be easily edited, expanded, reused and shared. The software can also be used in combination with a range of other programs, such as referencing tools (Endnote, Mendeley, RefWorks, or Zotero), note-taking and archiving software (such as Evernote and OneNote), or SurveyMonkey. [23]
Apart from the literature review, we found that the best way to get to know the software was (in the case of NVivo) to experiment with the preinstalled sample project. In line with traditional approaches to content analysis, we also created a pilot project, in which steps such as data import and running coding queries were tested prior to entering the "serious" stage of analysis. As SCHREIER (2012, p.174) notes,
"trying out your coding frame on part of your material ... allows you to identify the inevitable shortcomings of your coding frame at an early stage, and allows other coders working together with you to familiarise themselves with the coding frame." [24]
3.2 Step 2: Data import and preparation
The next step, after selecting and getting familiar with the software, was to import and prepare the data to be analyzed. [25]
For the study at hand, the Factiva database was used to identify news articles containing specific search terms (Zealand and carbon emissions, used as proxy for New Zealand's environmental performance), published in specific newspapers (leading quality press in Australia, the UK and the US) over a specific time period (2008-2012). Search results (articles) were saved as rtf files, each of which comprised a year of coverage per newspaper. Once opened in Microsoft Word, we skimmed those files for content not relevant for the research question, such as sports reports or obituaries (having previously established selection criteria with the research team), and then split them into one file per article using a freely available file-splitting software, Editor's Toolkit. It is of course also possible to skip this step and to directly download and save each article as individual file, especially where database search results in fewer articles than in our case. [26]
Once imported into the software program via NVivo's integrated data import tool, we assigned the articles to a source classification sheet that we had previously created, adapted from a pre-installed template: essentially a table containing specific attributes (columns) and the respective values of each article (rows). For our analysis of news articles, we chose the attributes country, year, newspaper, article title, author, author position, and tone (whether a specific issue was captured and referred to favorably or unfavorably), amongst others (see Screen capture 1 below). In other research scenarios attributes might be age, gender, or profession. Essentially, assigning attributes to documents means to catalog specific information or characteristics (DiGREGORIO, 2000), which enables the search of data for patterns across specific groups or subgroups (ROBERTSON, 2008), or to run detailed queries at a later stage (BRINGER et al., 2006). An additional benefit was that attributes can be added, edited or deleted throughout the analysis process, as required. For instance, we added some specific attributes for connotation at a later stage.
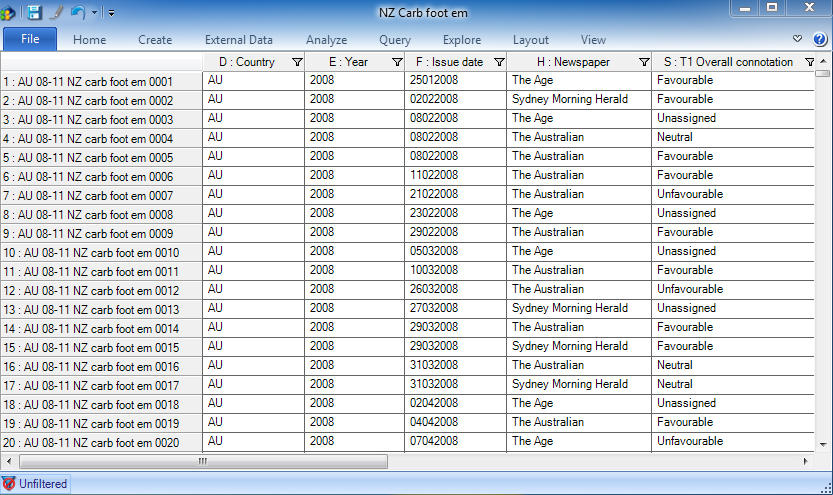
Screen capture 1: NVivo source classification sheet with attribute values. Please click here for an increased version of Screen capture 1. [27]
Screen capture 1 above shows part of the filled classification sheet of the research project. The column on the far left represents the individual news articles (units of analysis), followed by columns for attributes, such as country, year, issue date, and so on. [28]
3.3 Step 3: Multi-level coding
3.3.1 Coding: Inductive vs. deductive
QCA, according to MAYRING (2000), has at its core the creation and implementation of a coding frame, involving pilot coding, subsequent modification of the coding frame, and double coding. SCHREIER (2012) suggests that coding as implemented in QCA and coding more generally conducted during QDA are separate, albeit similar, processes:
"Both involve some degree of abstraction from your material, and both involve assigning a category/code and a segment of data to each other. The methods are different in that coding involves an analytic and iterative procedure, codes are typically data-driven and consistency is less of an issue. QCA is descriptive, linear, more than iterative, categories can also be concept-driven, and consistency is an important quality criterion" (p.44). [29]
The use of software facilitates the coding process by automatically recording the codes into the software's coding system ready for sorting later, as required. A big advantage of the software lies in the retrieval of coded text, which remains linked with the individual source passages and so allows ready checking back and forth between analysis and source data. In addition, coding frequencies can be readily viewed, helping in the process of thematic analysis (KUCKARTZ, 2014). [30]
When using NVivo, coding is essentially the act of assigning segments of text or other content to nodes, which are best understood as containers or storage areas (BAZELEY, 2007) that hold "references about a specific theme, place, person or other area of interest" (BRYMAN, 2008, p.570). Similarly to the way folders are organized in Windows operating systems, nodes can be structured hierarchically so that a parent node (for example, Australia) can have multiple child nodes, which in turn can contain additional child nodes (see Screen capture 2 below).
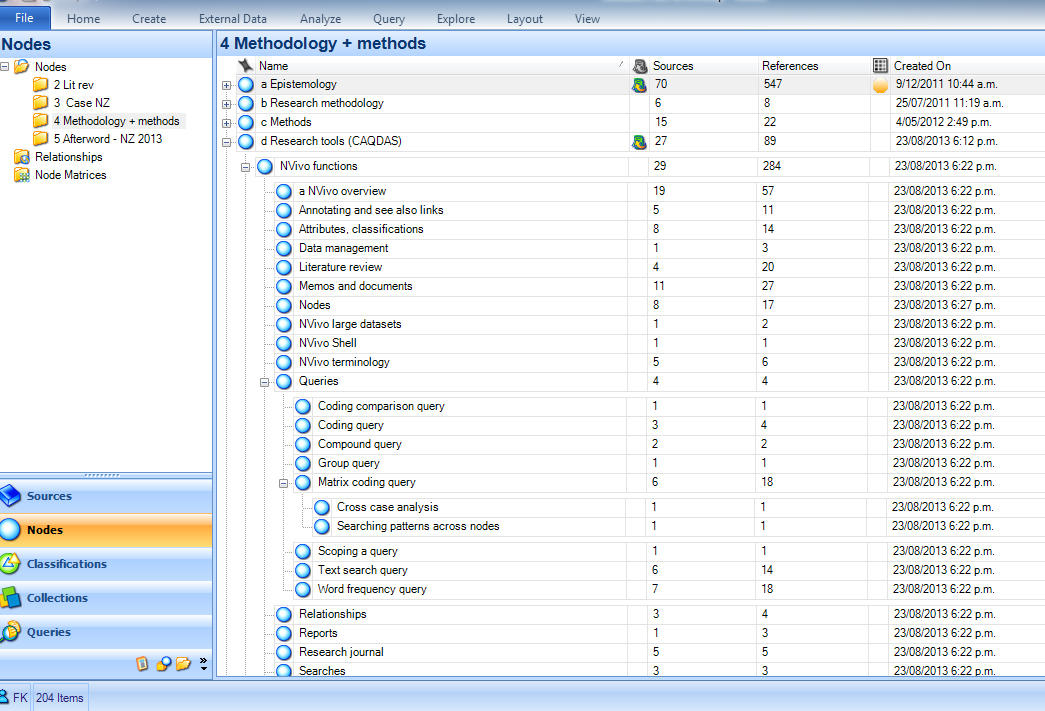
Screen capture 2: Parent and child nodes in NVivo (Version 10). Please click here for an increased version of Screen capture 2. [31]
Depending on the chosen methodology, this coding can be a first step or "a permeating feature throughout the analytical process" (SCHÖNFELDER, 2011, §33). For example, inductive coding—starting with a detailed analysis of sources, such as news articles, and generating concepts and ideas as themes emerge—will be the preferred strategy for those following a grounded theory strategy (BAZELEY, 2007). Deductive coding, on the other hand, means to start with a specific set of themes, keywords or theoretical ideas in mind, and then to explore whether and how these are mentioned in the sources. [32]
For the multi-level QCA of news articles presented in this article, we used a combination of inductive and deductive coding approach, given our research objective was to determine both quantity (amount and frequency) and valence (tone and themes) of news coverage. In fact, taking such a flexible approach to coding is not uncommon, as the way in which software is used during the analysis process depends on the research questions and objectives (see for example, BOURDON, 2002; MacMILLAN, 2005; RYAN, 2009; SIN, 2008). [33]
Once we completed the step of assigning the source classification sheet attribute values to the news articles, the actual analysis began. The following section describes our use of NVivo 10 software to facilitate the multi-level coding approach we took for our qualitative content analysis of Australian, U.K. and U.S. newspaper articles covering NZ in connection with carbon emissions and its environmental global positioning, published during 2008-2012. [34]
As a first step in the multi-level coding approach illustrated in Figure 1 below we reduced the news articles to those parts relevant for the research question, namely those that contained all the search terms. SCHREIER (2012) describes this process as: "Dividing your units of analysis [news articles] into units of coding [parts of the article relevant for the research question] can be thought of as cutting your text into snippets with a pair of scissors" (p.133). We used NVivo's "query" function to help find patterns and to check our initial ideas, as recommended by BAZELEY (2007). The function allowed us to save searches and to re-run them as required on different data, and to store, print or export the results. For example, we ran text search queries for specific words or combinations of words on all or selected sets of our news articles, as well as word frequency queries to generate lists of the most frequent words in a particular source, folder or node. [35]
We were interested in understanding results of any query in "context." SCHREIER (2012), in reference to KRIPPENDORFF (2004) and RUSTEMEYER (1992), describes context units as "that proportion of the surrounding material that one needs to understand the meaning of a given unit of coding" (p.133). In our case, we decided that at least the paragraph surrounding each search term was necessary as the context for understanding how the term was used. [36]
We first conducted a text search query for emissions and saved results including the surrounding paragraph at a new node. Next, we ran a text search query for New Zealand within the content just saved in the newly created emissions node (in NVivo this is called a compound query), to single out references to New Zealand and carbon emissions. [37]
Again, results were saved as a new node—NZ emissions—which became the context node. This way only the search term in its context, the most relevant parts within the articles, was included in the analysis. [38]
In the case of overseas news coverage of New Zealand and carbon emissions, this was necessary as mentions often were limited to one paragraph, leaving the rest of the article of little relevance for the research questions.
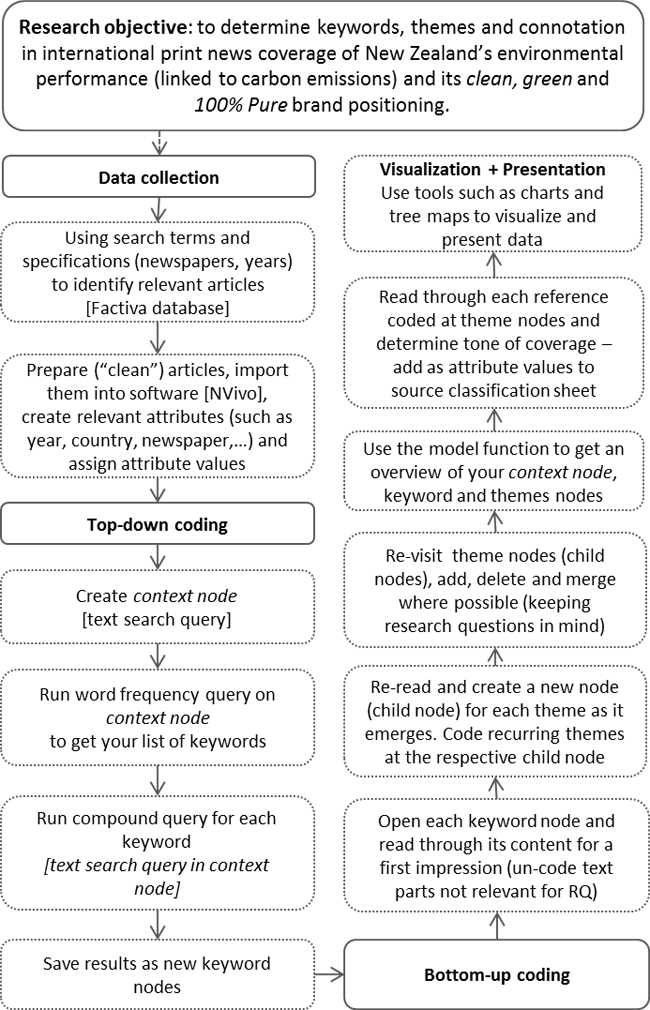
Figure 1: QDAS-assisted multi-level coding approach to qualitative content analysis of news articles [39]
Next we ran a word frequency query within the context node and created a new node for each of the key terms that appeared in the query results, such as emissions trading, or Australia. We then ran a text search query on the context node to single out and save references to each key term in the respective node. [40]
Once this was done, we started with the inductive part of analysis, or bottom-up coding. This basically consisted of opening the nodes created for each of the most frequent terms, reading their content line-by-line, and coding salient themes into new child nodes—a procedure also referred to as open coding (see for example, GIBBS, 2002; KUŞ SAILLARD, 2011; SICCAMA & PENNA, 2008). [41]
This was also the stage at which we determined the tone of coverage related to each of those key terms, which we noted in the source classification sheet, once the respective new attributes had been created. Unlike the comparatively rigid top-down coding process that comprised the first part of our software-assisted QCA, the second part was more flexible in that we revisited the newly created theme nodes, edited and changed them if, for example, references to a specific theme overlapped or turned out to be less frequent than expected, in which case we would merge those child nodes. [42]
3.4 Step 4: Visualizing data and presenting findings
Our final step of the software-assisted qualitative content analysis of news articles presented in this article was to use some of the visualization tools offered by NVivo, such as models, charts and tree maps. For instance, the model function helped us to detect patterns and relationships in data (BAZELEY & JACKSON, 2013). Especially during the literature review which we conducted prior to the data analysis and as a way to get acquainted with the software, models proved a useful tool to visualize links and relations between nodes, sources, or ideas (BAZELEY, 2007; BRINGER et al., 2006; ROBERTSON, 2008). They gave an overview of "who or what is involved, their relationships and their relative importance" (BAZELEY & JACKSON, 2013, p.217). We also used the model tool during the bottom-up coding stage described above, to gain a better understanding and overview of key themes in Australian coverage of New Zealand and carbon emissions, for instance (see Figure 2 below). We particularly liked the fact that the model tool displays but does not interfere with actual project documents (SICCAMA & PENNA, 2008).
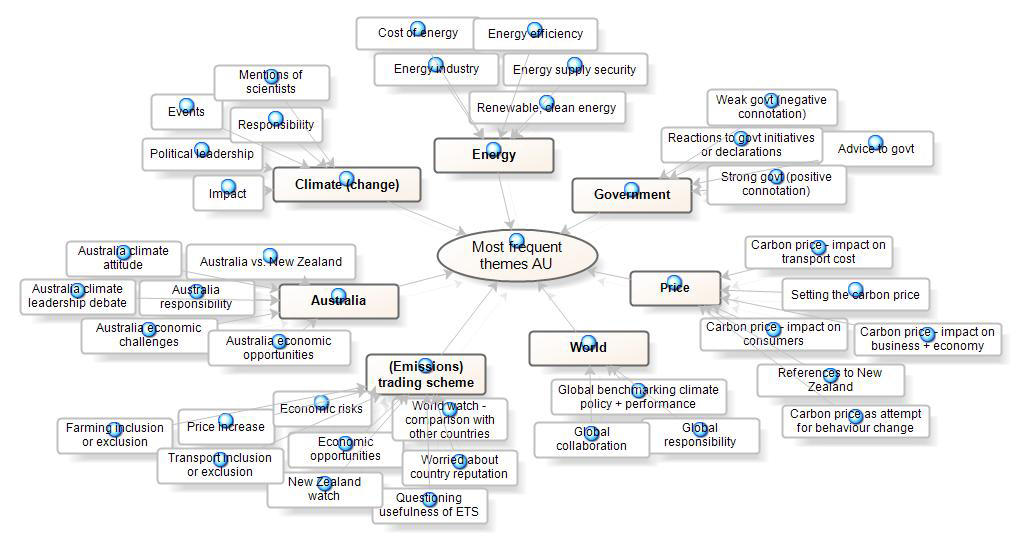
Figure 2: Model depicting key themes in Australian news coverage of NZ and carbon emissions during 2008-2012, created with
NVivo (Version 10). Please click here for an increased version of Figure 2. [43]
In addition, tree maps helped us to visualize one or more attribute values within the data. For example, a tree map derived from the attributes country and year illustrated how the amount of overseas coverage of New Zealand and carbon emissions differed across countries and changed over time (see Figure 3 below).

Figure 3: NVivo tree map showing coverage of NZ and carbon emissions by country and year [44]
A major benefit of using tree maps and other visualization tools is that they are linked to the data represented, allowing fast and easy access. For instance, hovering over the fields within a tree map shows the number of items it represents, while a double-click opens the classification sheet with the meta-data (attribute values) previously assigned to the respective articles. However, due to the multiple functions offered by QDAS such as NVivo, the functionality of visualization tools can be limited, and so it can be useful to combine QDAS with other software. For example, we used Microsoft Excel to create the charts depicting changes in the amount and tone of overseas news coverage by manually transferring the respective values from our NVivo file. [45]
4. Ensuring Trustworthiness and Reliability of Findings
Because processes of organizing, coding and analyzing data in qualitative research are largely invisible to the reader, a high amount of faith in the presented research results is required (KRIPPENDORFF, 2013). Insufficient transparency and trustworthiness of the qualitative data analysis process have repeatedly been stressed as limiting factors of qualitative inquiries (BRINGER et al., 2004; DECROP, 1999; KIKOOMA, 2010; RICHARDS, 2002). As mentioned in Section 1, qualitative studies often lack a detailed account of data collection procedures, steps involved in the analysis process, and how those lead to specific results and conclusions (JOHNSTON, 2006; KIKOOMA, 2010; THOMPSON, 2002). Clearly, making the research process transparent can enhance its trustworthiness and perceived quality. [46]
While software-use per se does not guarantee trustworthiness, packages such as NVivo do provide a range of tools, or transparency mechanisms, that can help make the methodological and analytical process more comprehensible and retraceable (JOHNSTON, 2006; MANGABEIRA et al., 2004; RYAN, 2009; THOMPSON, 2002). These include the log file in which each action undertaken in NVivo is registered, the ability to export and save coding extracts, node structures, and so on, and the visualization tools described above. Moreover, the software makes it comparatively easy for multiple researchers to work on the same file without having to be in the same geographical location, thereby allowing for double coding and coding reliability. [47]
For the qualitative content analysis of news articles presented here, additional transparency mechanisms included keeping a research journal for reflections on the research process and to keep track of software or coding issues and their solutions. In fact, many QDAS users recommend recording emergent ideas, key decisions and even "have-done" and "to-do" lists in a research journal in order to allow reflection on the research process (BAZELEY, 2007; BRINGER et al., 2004, 2006; JOHNSTON, 2006). Keeping the research journal within NVivo had the advantage that it could be linked to sources or nodes, and that its content could be coded, searched and annotated just like any other document within the software. However, doing so also carried the risk of losing the journal in the event of software or computer crashes, as we experienced during the pilot project on a previous version of the NVivo software. We ended up keeping it as an external document for the additional advantage that the journal could be shared with research supervisors or collaborators not familiar with NVivo. [48]
Despite the apparent advantages of using software such as NVivo as a tool for qualitative content analysis of news articles, we endorse the observation by other scholars that QDAS are neither designed for nor capable of analyzing the data for the researcher and that they only provide the tools to assist this analysis (HUTCHISON, JOHNSTON & BRECKON, 2010; LEECH & ONWUEGBUZIE, 2011; MacMILLAN, 2005; ROBERTS & WILSON, 2002; SCHÖNFELDER, 2011; SCHREIER, 2012). We found that, despite its strengths, the NVivo package was no magic wand through which bad analysis or sloppy data could deliver great results (MARSHALL, 2002; THOMPSON, 2002). Just like with manual research methods, the researcher remained the person in charge of interpreting the text and drawing conclusions (BERGIN, 2011; GIBBS, 2002). Here we found the most trained researcher and the one closest to the data collected was best at analysis. The coding underpinning this analysis was however also retrievable, for display during ongoing analysis. Due to the transparent nature of the coding process, we were able to provide feedback to analysis and interpretation could become a truly joint effort. This supports the assumption put forward by MacMILLAN and KOENIG (2004) that the better the researcher is at working the software program, the better analysis and results are likely to be. In this regard, flexibility, creativity and intuition are as important as ever, whether one uses software or not (BOURDON, 2002; LEECH & ONWUEGBUZIE, 2011; ROBERTS & WILSON, 2002). [49]
We found that QDAS facility for analytical flexibility and transparency of the research process were among the key advantages of using software-assisted analysis over manual methods. [50]
Some early criticism of QDAS included concerns that the use of software for qualitative data analysis could hinder in-depth, interpretative analysis by distancing the researcher from the data (BAZELEY, 2007; BOURDON, 2002; RYAN, 2009). At the same time, too much closeness to data had been identified as a considerable limitation to using QDAS in qualitative research, particularly when researchers immerse themselves too much in their data and lose sight of the larger picture (BAZELEY, 2007; GILBERT, 2002). [51]
The multi-level approach to QDAS-assisted analysis of news articles presented in this article however was found to help avoid both extremes in that it allowed "closeness for familiarity and appreciation of subtle differences, but distance for abstraction and synthesis—and the ability to switch between the two" (BAZELEY, 2007, p.8). For example, usually the researcher closest to the data brings in the awareness of the complexities in the data, while other researchers bring in the abstraction necessarily for synthesis at the final stage of the analysis. However, they do this without being familiar with the coding process and the data. Thus abstraction is imposed on to the data. In this case as the coding and analysis processes are transparent, the focus on familiarity can be switched to abstraction, followed by synthesis as some members will still remain distant from the data, while being fully aware of how the data was coded. [52]
On the other hand, due to the comparative ease of coding in QDAS, over-coding did become a serious issue, especially for novice researchers who often did not know when to stop coding (MARSHALL, 2002). Thus we concur with MARSHALL who noted that in such a scenario, software designed to facilitate coding can turn into a serious limitation by making it difficult to stop, particularly because—no matter how much time and effort one spends coding—there is always something else, something potentially useful to be found (ibid.). We found that researchers who were distant from the actual data, could help the novice researcher think beyond the "coding" stage. [53]
Thus, we stress the importance of well-defined research questions and a clear, step-by-step procedure such as the one presented in this article, to help to avoid the issue of over-coding at the analysis stage. [54]
The purpose of this article was to illustrate the methodological process of using qualitative data analysis software such as NVivo, with a specific focus on qualitative content analysis. We demonstrated how tools provided by QDAS can be used to explore occurrences of specific keywords within news texts—namely New Zealand in connection with carbon emissions, their meanings within the immediate context, and how software makes it possible to drill down to words and back up to context, and to move back and forth in coding and between analytical levels. The article stressed that, while not without its pitfalls and limitations, QDAS-assisted qualitative research in general and QCA specifically also has some considerable advantages over manual analysis methods, first and foremost analytical flexibility and transparency. This is particularly the case where more than one researcher is involved. Eventually, there are myriad ways of applying software to qualitative and mixed methods analysis of texts, such as news articles. As software develops and the range of available options constantly increases, more illustrations and detailed accounts of software use in practice, such as the one attempted in this article, will be needed to guide researchers in their decision which, whether and how to use software within the broad field of qualitative research. [55]
1) For an overview and discussion of QDAS options see http://www.content-analysis.de/software/qualitative-analysis [Accessed: May 3, 2012]. <back>
Anholt, Simon (2010). Places: Identity, image and reputation. Houndsmills: Palgrave Macmillan.
Avraham, Eli (2000). Cities and their news media images. Cities, 17(5), 363-370. doi: 10.1016/S0264-2751(00)00032-9.
Avraham, Eli, & Ketter, Eran (2008). Media strategies for marketing places in crisis: Improving the image of cities, countries and tourist destinations. Burlington, MA: Elsevier.
Bazeley, Pat (2007). Qualitative data analysis with NVivo (2nd ed.). Thousand Oaks, CA: Sage.
Bazeley, Pat (2009). Analysing qualitative data: More than "identifying themes". Malaysian Journal of Qualitative Research, 2, 6-22, http://www.researchsupport.com.au/More_than_themes.pdf [Accessed: May 12, 2012].
Bazeley, Pat (2011). NVivo 9.1 reference guide, http://www.researchsupport.com.au/NV9.1_notes.pdf [Accessed: May 14, 2012].
Bazeley, Pat, & Jackson, Kristi (2013). Qualitative data analysis with NVivo (2nd ed.). London: Sage.
Berelson, Bernhard (1952). Content analysis in communicative research. New York, NY: Free Press.
Bergin, Michael (2011). NVivo 8 and consistency in data analysis: Reflecting on the use of a qualitative data analysis program. Nurse Researcher, 18(3), http://europepmc.org/abstract/MED/21560920 [Accessed: May 3, 2012].
Bourdon, Sylvain (2002). The integration of qualitative data analysis software in research strategies: Resistances and possibilities. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 11, http://nbn-resolving.de/urn:nbn:de:0114-fqs0202118 [Accessed: May 12, 2012].
Bringer, Joy D.; Johnston, Lynne H. & Brackenridge, Celia H. (2004). Maximizing transparency in a doctoral thesis: The complexities of writing about the use of QSR*NVIVO within a grounded theory study. Qualitative Research, 4(2), 247-265. doi: 10.1177/1468794104044434.
Bringer, Joy D.; Johnston, Lynne H. & Brackenridge, Celia H. (2006). Using computer-assisted qualitative data analysis software to develop a grounded theory project. Field Methods, 18(3), 245-266. doi: 10.1177/1525822X06287602.
Bryman, Alan (2008). Social research methods (3rd ed.). Oxford: Oxford University Press.
Bryman, Alan (2012). Social research methods (4th ed.). Oxford: Oxford University Press.
Chouliaraki, Lilie (2006). The spectatorship of the suffering. London: Sage.
Cottle, Simon (2009a). Global crises in the news: Staging news wars, disasters, and climate change. International Journal of Communication, 3, 494-516, http://ijoc.org/index.php/ijoc/article/view/473 [Accessed: June 2, 2012].
Cottle, Simon (2009b). Global crisis reporting: Journalism in the global age. Maidenhead: Open University Press.
Cousins, Ken, & McIntosh, Wayne (2005). More than typewriters, more than adding machines: Integrating information technology into political research. Quality and Quantity, 39(5), 581-614. doi: 10.1007/s11135-005-3149-z.
Decrop, Alain (1999). Triangulation in qualitative tourism research. Tourism Management, 20(1), 157-161. doi:10.1016/S0261-5177(98)00102-2.
DiGregorio, Silvana (2000). Using NVivo for your literature review. Paper presented at the Conference on Strategies in Qualitative Research: Issues and Results from Analysis using QSR NVivo and NUD*IST, Institute of Education, London, http://www.sdgassociates.com/downloads/ literature_review.pdf [Accessed: May 23, 2012].
Gibbs, Graham R. (2002). Qualitative data analysis: Explorations with NVivo. Philadelphia, PA: Open University Press.
Gilbert, Linda S. (2002). Going the distance: "Closeness" in qualitative data analysis software. International Journal of Social Research Methodology, 5(3), 215-228. doi: 10.1080/13645570210146276.
Gläser, Jochen, & Laudel, Grit (1999). Theoriegeleitete Textanalyse? Das Potential einer variablenorientierten qualitativen Inhaltsanalyse. Berlin: Wissenschaftszentrum Berlin für Sozialforschung.
Gold, John R. (1994). Locating the message: Place promotion as image communication. In John R. Gold & Stephen V. Ward (Eds.), Place promotion: The use of publicity and marketing to sell towns and regions (pp.19-38). Chichester: John Wiley & Sons.
Hall, C M (2002). Travel safety, terrorism and the media: The significance of the issue-attention-cycle. Current Issues in Tourism, 5(5), 458-466. doi: 10.1080/13683500208667935.
Holsti, Ole R. (1969). Content analysis for the social sciences and humanities. Reading, MA: Addison-Wesley.
Hsieh, Hsiu-Fang & Shannon, Sarah E. (2005). Three approaches to qualitative content analysis. Qualitative Health Research, 15(9), 1277-1288. doi: 10.1177/1049732305276687.
Hutchison, Andrew J.; Johnston, Lynne H. & Breckon, Jeff D. (2010). Using QSR-NVivo to facilitate the development of a grounded theory project: An account of a worked example. International Journal of Social Research Methodology, 13(4), 283-302. doi: 10.1080/13645570902996301.
Jäger, Sigfried & Maier, Florentine (2009). Theoretical and methodological aspects of Foucauldian critical discourse analysis and dispositive analysis. In Ruth Wodak & Michael Meyer (Eds.), Methods of critical discourse analysis (pp.34-61). London: Sage.
Johnston, Lynne (2006). Software and method: Reflections on teaching and using QSR NVivo in doctoral research. International Journal of Social Research Methodology, 9(5), 379-391. doi: 10.1080/13645570600659433.
Kikooma, Julius F. (2010). Using qualitative data analysis software in a social constructionist study of entrepreneurship. Qualitative Research Journal, 10(1), 40-51. doi: 10.3316/QRJ1001040.
Kohlbacher, Florian (2006). The use of qualitative content analysis in case study research. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 7(1), Art. 21, http://nbn-resolving.de/urn:nbn:de:0114-fqs0601211 [Accessed: June 1, 2012].
Krippendorff, Klaus (2004). Content analysis: An introduction to its methodology. Thousand Oaks, CA: Sage
Krippendorff, Klaus (2013). Content analysis: An introduction to its methodology (3rd ed.). Thousand Oaks, CA: Sage.
Kuckartz, Udo (2014). Qualitative text analysis. London: Sage.
Kuş Saillard, Elif (2011). Systematic versus interpretive analysis with two CAQDAS packages: NVivo and MAXQDA. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 34, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101345 [Accessed: May 10, 2012].
Lavery, Lyn (2012). Using NVivo for literature reviews, http://forums.qsrinternational.com/index.php?showtopic=4285 [Accessed: February 20, 2012].
Leech, Nancy L. & Onwuegbuzie, Anthony J. (2011). Beyond constant comparison qualitative data analysis: Using NVivo. School Psychology Quarterly, 26(1), 70-84. doi: 10.1037/a0022711.
Lewins, Ann & Silver, Christina (2007). Using software in qualitative research: A step-by-step guide. London: Sage.
MacMillan, Katie (2005). More than just coding? Evaluating CAQDAS in a discourse analysis of news texts. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(3), Art. 25, http://nbn-resolving.de/urn:nbn:de:0114-fqs0503257 [Accessed: May 24, 2012].
MacMillan, Katie & Koenig, Thomas (2004). The wow factor: Preconceptions and expectations for data analysis software in qualitative research. Social Science Computer Review, 22(2), 179-186. doi: 10.1177/ 0894439303262625.
Mangabeira, Wilma C.; Lee, Raymond M. & Fielding, Nigel G. (2004). Computers and qualitative research: Adoption, use, and representation. Social Science Computer Review, 22(2), 179-186. doi: 10.1177/0894439303262622.
Marshall, Helen (2002). What do we do when we code data? Qualitative Research Journal, 2(1), 56-70. http://www.stiy.com/qualitative/1AQR2002.pdf#page=56 [Accessed: May 23, 2012].
Mayring, Philipp (2000). Qualitative content analysis. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(2), Art. 20, http://nbn-resolving.de/urn:nbn:de:0114-fqs0002204 [Accessed: June 1, 2012].
Richards, Lyn (2002). Qualitative computing—a methods revolution? International Journal of Social Research Methodology, 5(3), 263-276. doi: 10.1080/13645570210146302.
Roberts, Kathryn A. & Wilson, Richard W. (2002). ICT and the research process: Issues around the compatibility of technology with qualitative data analysis. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 23, http://nbn-resolving.de/urn:nbn:de:0114-fqs0202234 [Accessed: May 10, 2012].
Robertson, Stuart P. (2008). The qualitative research process as a journey: Mapping your course with qualitative research software. Qualitative Research Journal, 8(2), 81-90. doi: 10.3316/QRJ0802081.
Rustemeyer, Ruth (1992). Praktisch-methodische Schritte der Inhaltsanalyse. Münster: Aschendorff.
Ryan, Mary (2009). Making visible the coding process: Using qualitative data software in a post-structural study. Issues in Educational Research, 19(2), 142-163, http://iier.org.au/iier19/ryan.html [Accessed: February 2, 2012].
Schönfelder, Walter (2011). CAQDAS and qualitative syllogism logic—NVivo 8 and MAXQDA 10 compared [91 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 21, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101218 [Accessed: May 9, 2012].
Schreier, Margit (2012). Qualitative content analysis in practice. London: Sage
Schreier, Margrit (2014). Varianten qualitativer Inhaltsanalyse: Ein Wegweiser im Dickicht der Begrifflichkeiten. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 15(1), Art. 18, http://nbn-resolving.de/urn:nbn:de:0114-fqs1401185 [Accessed: February 3, 2014].
Siccama, Carolyn J., & Penna, Stacy (2008). Enhancing validity of a qualitative dissertation research study by using NVivo. Qualitative Research Journal, 8(2), 91-103. doi: 10.3316/QRJ0802091.
Sin, Chih H. (2008). Teamwork involving qualitative data analysis software: Striking a balance between research ideals and pragmatics. Social Science Computer Review, 26(3), 350-358. doi: 10.1177/0894439306289033.
Thompson, Robert (2002). Reporting the results of computer-assisted analysis of qualitative research data. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 25, http://nbn-resolving.de/urn:nbn:de:0114-fqs0202252 [Accessed: May 24, 2012].
Titscher, Stefan; Meyer, Michael; Wodak, Ruth & Vetter, Eva (2000). Methods of text and discourse analysis. London: Sage.
Welsh, Elaine (2002). Dealing with data: Using NVivo in the qualitative data analysis process. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 3(2), Art. 26, http://nbn-resolving.de/urn:nbn:de:0114-fqs0202260 [Accessed: May 10, 2012].
Dr. Florian KAEFER is a researcher, writer and advisor on the branding and reputation of places. He is the founder and editor of The Place Brand Observer. His doctoral research on news representations and discursive constructions of national environmental performance and place brand image in the case of New Zealand was part of a Royal Society New Zealand Marsden grant, led by Professor Juliet ROPER.
Contact:
Florian Kaefer
Address known by the Editorial Office
E-mail: editor@placebrandobserver.com
Dr. Juliet ROPER is Head of Department and Professor of Management Communication, Management School, University of Waikato, New Zealand. Her work on social and environmental aspects of sustainability, public relations, government and corporate discourses on sustainability and social responsibility has been published in, for example, Journal of Public Relations Research, Public Relations Review, Journal of Applied Communication Research, Public Understanding of Science, and Organization Studies.
Contact:
Juliet Roper
Waikato Management School
The University of Waikato
Private Bag 3105
Hamilton
New Zealand
E-mail: jroper@waikato.ac.nz
Dr. Paresha SINHA is a Senior Lecturer in the Department of Strategy and Human Resource Management, Waikato Management School, University of Waikato, New Zealand. Her qualitative case study based research on the co-production of celebrity CEO image and the legitimation of merger and acquisitions strategies in news media has been published in Organization Studies and Strategic Organization.
Contact:
Paresha Sinha
Waikato Management School
The University of Waikato
Private Bag 3105
Hamilton
New Zealand
E-mail: psinha@waikato.ac.nz
Kaefer, Florian; Roper, Juliet & Sinha, Paresha (2015). A Software-Assisted Qualitative Content Analysis of News Articles:
Example and Reflections [55 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 16(2), Art. 8,
http://nbn-resolving.de/urn:nbn:de:0114-fqs150283.

Creative Commons Attribution 4.0 International License