Volume 22, No. 2, Art. 3 – Mai 2021
Zur Einschätzung von Reaktanz und Invasivität in videografischen Daten. Ein kontextsensibler Ansatz zur Beurteilung der Kamerarolle in Aufnahmesituationen
Paul Goerigk, Kristin Weiser-Zurmühlen, Göntje Erichsen & Kathrin Wild
Zusammenfassung: Videografie ist das Mittel der Wahl zur Generierung von Daten, wenn feinkörnige Analysen von Interaktionen ermöglicht werden sollen. Unabhängig von verschiedenen Analyseformen stellt sich die Frage, wie die Aufnahmetechnik die nicht-verdeckt gefilmte Situation beeinflusst. Auf welche Weise können Forschende einschätzen, inwiefern die Gefilmten die Situation als Aufnahmesituation verstehen und welche Rolle sie der Kamera zuschreiben? Die Klärung dieser Frage ist im Kontext qualitativer Forschung für die Einschätzung der Verwendbarkeit der Aufnahmen als sozialwissenschaftliche Daten von zentraler Bedeutung. Nach einer kurzen Darstellung des Diskurses zu Invasivität und Reaktanz entwickeln wir auf der Basis einer konversationsanalytisch informierten Vorgehensweise ein Instrumentarium, das hilft, Invasivität und Reaktanz in Videodaten einzuschätzen. Dieses wenden wir auf empirische Fallbeispiele aus unterschiedlichen Forschungsprojekten an. Es zeigt sich, dass die zeitliche, räumliche, thematische und soziale Ebene des Kontexts der nicht-verdeckten Aufnahmesituation für die Bestimmung von Reaktanz und Einschätzung von Invasivität genutzt werden kann, auch wenn hierbei Grenzen deutlich werden.
Keywords: Videografie; Invasivität; Reaktanz; Kamerarolle; Methodologie der Datengenerierung
Inhaltsverzeichnis
1. Einleitung
2. Methodologischer Diskurs
3. Analytischer Bezugsrahmen
3.1 Invasivität und Reaktanz
3.2 Kontext und Kontextualisierung
3.3 Participation framework
4. Empirische Analyse
4.1 Analysefokus und Erkenntnisinteresse
4.2 Analyse von Fallbeispielen zu Kameraadressierungen
4.3 Diskussion der Ergebnisse
5. Fazit und Ausblick
Anhang: Transkriptionskonventionen
Zum Autor und zu den Autorinnen
Unterrichts- und Sozialforscher*innen setzen zunehmend auf Datengenerierung durch Videografie, um sich bei der Analyse flüchtiger Ereignisse nicht nur auf eine sinnhaft-sprachlich vorgeprägte Dokumentation des Geschehens wie z.B. auf Beobachtungsprotokolle (BERGMANN 2007) verlassen zu müssen. Technisch generierte Aufnahmen bieten gegenüber Beobachtungsprotokollen den Vorteil, dass das Datenmaterial nicht bereits im Erzeugungsprozess durch Sinnselektionen von Forschenden sowie Erzählzwänge geformt wird. Darüber hinaus ermöglichen Videoaufnahmen einerseits feinkörnige, andererseits immer wieder neue Beobachtungen des Geschehens, was insbesondere interaktionsanalytisch Forschenden neue Perspektiven eröffnet (MONDADA 2008), aber auch Fragen des Umgangs mit Videomaterial sowie zu dessen Verhältnis zu Transkripten aufwirft (MARKLE, WEST & RICH 2011). [1]
Gleichzeitig wird in der Methodendiskussion verstärkt auf die Invasivität von Aufnahmetätigkeiten verwiesen, womit neben der Wirkung anwesender Forscher*innen vor allem der Einfluss der Kamera(s) gemeint ist. Daraus ergeben sich Fragen hinsichtlich der Möglichkeiten, diese Auswirkungen zu erfassen, um sie bei der Analyse reflektieren zu können. Hierzu werden häufig retrospektive Verfahren eingesetzt, die jedoch aufgrund von sozialer Erwünschtheit und der damit verbundenen Notwendigkeit nachträglicher Interpretation nicht immer zielführend sind. Wir gehen in diesem Beitrag davon aus, dass sich die Invasivität – wenn auch nicht in Gänze – in Form von Reaktanz in den Videodaten manifestiert und insofern auch analysiert und reflektiert werden kann. [2]
Im vorliegenden Beitrag skizzieren wir zunächst den methodologischen Diskurs zum Einfluss der Kamera auf die aufgenommene Situation, um anschließend relevante Konzepte für die empirische Erfassung zu diskutieren. Wir legen die Annahme zugrunde, dass der situative Kontext hilfreich für das Einschätzen der Kamerawirkung ist und sich in Form von Reaktanz mithilfe des participation framework nach GOFFMAN (1979, S.11) methodisch fassen lässt. Mit unserem methodologischen Erkenntnisinteresse fokussieren wir insbesondere die Frage, welche Relevanz der jeweils soziale, thematische, räumliche und zeitliche Kontext der Aufnahmesituation für die Rollenzuweisung der Kamera in der nicht-verdeckten Aufnahmesituation hat. Dazu analysieren wir explorativ verschiedene Datenbeispiele und schließen weiterführende methodologische Überlegungen an. Die Beispiele stammen aus schulischen bzw. institutionellen Kontexten, sodass unsere Ergebnisse in ihrer Reichweite vorerst auf diese begrenzt bleiben. [3]
In diesem Abschnitt gehen wir auf den methodologischen Diskurs sowie die Chancen und Herausforderungen von videografischen Verfahren ein. Hierzu diskutieren wir unter Bezugnahme auf das Konzept der Invasivität eine potenzielle Einschränkung der Verwendbarkeit von audiovisuellen Daten, um anschließend zu argumentieren, dass eine systematische Analyse des Kontexts von nicht-verdeckten Aufnahmen für das Verstehen von Reaktanz und ein Einschätzen von Invasivität genutzt werden sollte. [4]
Auch wenn es Untersuchungen gibt, bei denen mit verdeckten Aufnahmen (bspw. von Überwachungskameras) gearbeitet wird, entwickeln wir unsere Überlegungen anhand audiovisueller Daten, die mit Kenntnis der Beforschten aufgezeichnet wurden. Wir beziehen uns in diesem Beitrag auf das Generieren von Videoaufnahmen im schulischen bzw. institutionellen Kontext und auf Daten, über deren Zweck die Forschungsteilnehmer*innen jeweils informiert waren. Mit Videografie ist hier in Anlehnung an CORSTEN (2018) sowie DINKELAKER und HERRLE (2009) das audiovisuelle Aufzeichnen in einem zuvor definierten Feld zu Zwecken der wissenschaftlichen Analyse gemeint. [5]
Es kann davon ausgegangen werden, dass durch die Kamera das Geschehen nicht passiv aufgezeichnet wird, sondern dass diese an dessen Hervorbringen beteiligt ist (FANKHAUSER 2016). Daher sind videografische Verfahren der Datengenerierung grundsätzlich als reaktiv anzusehen, wenngleich sie einige Vorteile für Forschende mit sich bringen. HEE (2018) fasste diese auf der Basis einschlägiger Forschungsliteratur unter den Punkten der dauerhaften Iterierbarkeit und der Berücksichtigung nonverbalen Verhaltens zusammen. Insbesondere aus der Möglichkeit, gefilmte Situationen wiederholt zu betrachten und zu analysieren, resultiert die Chance, dass Aussagen über das Datenmaterial von mehreren Personen am Originaldatum überprüft werden können (TUMA & SCHNETTLER 2014; vgl. auch VOLOSHCHUK & GRIEßHABER 2010). Gleichzeitig wird angenommen, dass sich die Situation durch den Einsatz der Kamera als technisches Beobachtungsmedium verändert (REH 2012). Bereits LABOV (1972) beschrieb diese Veränderung als Beobachter*innenparadoxon und merkte an: "To obtain the data most important for linguistic theory, we have to observe how people speak when they are not being observed" (S.113). Dies ist aus forschungsethischen Gründen schwerlich möglich. Deshalb ist es in der empirischen Sozialforschung üblich, den Einfluss der beobachtenden Person(en) und des technischen Geräts auf die Beobachtungssituation zu reflektieren. [6]
Videografieforscher*innen diskutierten diesen Aspekt bisher vor allem unter den Schlagworten Reaktanz und Invasivität (vgl. zur Abgrenzung der Begriffe Abschnitt 3.1): Es wird davon ausgegangen, dass sich Gefilmte während der Datengenerierung, die als solche erkennbar ist, anders verhalten, als wenn sie nicht gefilmt würden. Diese Veränderung der Situation, die sich in Form von Reaktanz manifestieren kann, stellt ein methodisches Problem dar (vgl. u.a. SCHNETTLER & KNOBLAUCH 2009; TUMA, SCHNETTLER & KNOBLAUCH 2013). DREISCHENKÄMPER und STANIK (2014, S.42) bezeichneten derartige Phänomene als "Verzerrungen und Störungen". [7]
Wie auch immer der Einfluss bewertet werden mag, es ist unmöglich – wie es schon in der Formulierung des Beobachter*innenparadoxons bei LABOV anklingt – einzuschätzen, ob eine (Interaktions-)Situation exakt so stattgefunden hätte, wenn sie nicht (von einer Kamera) dokumentiert worden wäre. Für den Umgang mit diesem Problem wird häufig vorgeschlagen, vor dem Einsatz von Videografie teilnehmend im Feld zu beobachten sowie den Gefilmten Zeit zu geben, sich an die Beobachtungssituation zu gewöhnen und Vertrautheit mit der Kameraperson aufzubauen (WAGNER-WILLI 2004). Dies erscheint insofern sinnvoll, als so verlässlicher eingeschätzt werden kann, ob sich das Verhalten der Beobachteten angesichts von Aufnahmegeräten verändert (DREISCHENKÄMPER & STANIK 2014). Dennoch kann es allein durch die Anwesenheit eines oder einer Beobachtenden zu Reaktanz kommen. [8]
Weiterhin ist zu diskutieren, ob es tatsächlich einen Gewöhnungseffekt gibt, wie ihn beispielsweise MORITZ (2011) und auch SCHNETTLER und KNOBLAUCH (2009) postulierten. Fraglich ist zudem, ob das Beobachter*innenparadoxon bei größerer Öffentlichkeit eine geringere Rolle spielt (KRELLE 2014) und ob die Kamera nicht vielmehr, wie es WAGNER-WILLI (2004, S.55) formulierte, lediglich "toleriert, aber nicht vergessen" wird. Denn auch in anderen Studien wurde darauf hingewiesen, dass trotz fortgeschrittener Interaktion die Kamera potenziell wahrgenommen wird (MAAK & RICART BREDE 2014) z.B. durch Blicke in die Kamera, ein bemühtes Ignorieren der Kamera oder das von TUNCER (2016) aufgezeigte explizite Thematisieren der Aufnahmetätigkeit und der Kameraorientierung im direkten Anschluss an moralisch heikle Äußerungen. [9]
Bei Aufnahmen von Interviews oder Gruppendiskussionen, bei denen gewünscht ist, dass bestimmte Inhalte vor und für die Kamera erzählt oder diskutiert werden, ist die Kamera notwendigerweise Teil der Situation. In diesen Projekten, aber auch allgemein in Forschungsvorhaben, bei denen der Interaktionsanlass die Datengenerierung für Forschung ist, stellt sich für die Auswertung die Frage nach dem Einfluss der Kamera. Forschende, die mit der Methode der "Kamera-Ethnographie" (MOHN 2011) Daten generieren, sehen die Kamera als Teil der aufgenommenen Situation an. Dabei markieren sie Reaktionen auf die Kamera nicht als unerwünscht, sondern nutzen sie für die Analyse, sodass die Wirkung der Kamera auf die Interaktion einen integralen Teil des Verfahrens darstellt (FANKHAUSER 2013). Obgleich die Reflexion der Wirkung der Kamera auf die Aufnahmesituation bei Verfahren, bei denen die Kamera der Interaktionsanlass ist, erfolgt, stellt sich dennoch die Frage nach den Dimensionen der Einschätzung bzw. Interpretation der Kamerawirkung. [10]
Um den Einfluss der Kamera auf institutionelle Interaktionen zu ermitteln, werden oftmals retrospektive Befragungen in Form von Interviews oder Fragebögen eingesetzt. Diese sind häufig nur eingeschränkt aussagekräftig oder schwer zu deuten, da beispielsweise die soziale Erwünschtheit eine Rolle bei der Rekonstruktion spielt, sodass sich daraus ein Effekt der Kamera auf das Verhalten nicht zuverlässig ableiten lässt. Die beiden nachstehenden Transkriptausschnitte aus zwei Interviews, die im Anschluss an dieselbe videografierte Unterrichtssituation geführt wurden (ERICHSEN in Vorbereitung), zeigen, dass Retrospektion nur bedingt hilfreich für das Verständnis der Invasivität in der zuvor gefilmten Situation ist. Deutlich wird sowohl in dem Interview mit der Schülerin (S) als auch in dem Interview mit der Lehrkraft (LE), dass die Situation als Beobachtungssituation wahrgenommen wurde, denn die Schülerin verwies darauf, dass die Lehrkraft aufgrund der laufenden Kameras "aufgeregt" sei:
|
S: |
[ich glaube] jeder wollte sich benehmen °h weil da kameras sind und so; und auch LE war ganz aufgeregt glaub ich; |
Auszug 1: Wahrnehmung der Beobachtungssituation durch Schülerin1) [11]
Die Lehrkraft rekonstruierte die Aufnahmetätigkeit ebenfalls als irritierend, nahm jedoch an, dass dies überwiegend den Beginn der Situation betreffe:
|
LE: |
also ich hab die kameras im prinzip nicht wahrgenommen (.) und_äh das war schon so_n bisschen unterrichtsbesuchgefühl ne, ((...)) aber das war jetzt nicht irgendwie so dass ich jetzt das gefühl hätte ich bin irgendwie furchtbar nervös oder so (.) das war echt nicht; die schüler waren natürlich bisschen nervös am anfang (.) glaub ich (.) aber das hat sich glaub ich schnell gelegt ne, |
Auszug 2: Wahrnehmung der Beobachtungssituation durch Lehrkraft [12]
Darüber, wie die von den beiden Interviewpartner*innen dargestellten Veränderungen der gefilmten Interaktion aussahen und inwiefern die Aufnahmesituation das Feld tatsächlich verändert hatte, bestand kein Konsens zwischen den Beteiligten und ist anhand der Interviewausschnitte nicht nachvollziehbar. Deutlich wird jedoch, dass die Beteiligten mit der Annahme agierten, die Kamera habe die anderen Beteiligten beeinflusst, sie selbst jedoch nur in geringem Maße. An diesem Beispiel wird deutlich, wie unterschiedlich Rekonstruktionen und Fremd- und Selbsteinschätzungen der Gefilmten sein können und dass eine Triangulation, wie sie von PETKO, WALDIS, PAULI und REUSSER (2003) vorgeschlagen wurde, nicht unbedingt zielführend sein muss. Um Invasivität besser einschätzen zu können, sind u.E. vor allem Verfahren gewinnbringend, mit denen anhand der gewonnenen Aufnahmen die Reaktanz der Beteiligten und die Relevanz der Kamera aufgezeigt werden kann. [13]
Im Folgenden diskutieren wir zwei ausgewählte Studien, deren Autor*innen versuchten, den Einfluss der Kamera auf Unterrichtssituationen systematisch zu erfassen. MAAK und RICART BREDE (2014) definierten Invasivität in Anlehnung an PETKO et al. (2003) als den Einfluss der Kamera auf das Verhalten von Beobachteten. Um den Einfluss der Aufnahmetätigkeit in Form von Reaktanz messbar zu machen, entwickelten sie ein Kategoriensystem, mit dem das Blick- und Interaktionsverhalten der Lehrkräfte, der Schüler*innen sowie der Kameraperson(en) eingeschätzt wurde. Dabei kodierten sie einen umso höheren Wert, je höher die Anzahl der beteiligten Personen war, bei denen Reaktionen auf die Kamera(s) erkennbar waren. Sie berichteten in diesem Zusammenhang von einem Gesamtwert von 10% beobachtbarer Invasivität im Rahmen von sechs Lehr-Lern-Situationen (MAAK & RICART BREDE 2014). Für welche Zwecke welche Aspekte von kamerainduzierten Reaktionen sinnvoll quantifizierbar sind, ist u.E. eine offene Frage. [14]
HEE (2018) orientierte sich an diesem System und entwickelte es sowohl theoretisch als auch empirisch weiter. Sie leitete auf der einen Seite deduktiv Kategorien in Anlehnung an das Organon-Modell nach BÜHLER (1982 [1934]) her und systematisierte auf der anderen Seite induktiv Kategorien ausgehend von ihren eigenen Daten, mit deren Hilfe Unterrichtssituationen kodiert und in ihrem Invasivitätsgrad, -typ und ihrer Invasivitätsdimension erfasst werden konnten. Innovativ an dieser Herangehensweise war, dass HEE mit der Terminologie LATOURs (2007) darauf hinwies, dass die Kamera von den Interagierenden im Sinne der Akteur*in-Netzwerk-Theorie nicht nur als ein Objekt behandelt würde, sondern dass ihr ebenfalls ein Interaktantinnenstatus zukäme, d.h. dass sie als Teilnehmerin behandelt werden könne, auch wenn dies in vielen Fällen nur die Rolle des bystanders beinhalte (HEE 2018, S.371). [15]
Um eine Kodierung vorzunehmen, schlug HEE vor, als Forscher*in auf das eigene Alltags- und Erfahrungswissen von (Unterrichts-)Situationen zurückzugreifen:
"Eine mögliche Behelfslösung, um [...] Effekte der Invasivität einschätzen zu können, besteht darin, [...] nicht zwischen unbeobachteter Kommunikationssituation und beobachteter Kommunikationssituation [...], sondern zwischen beobachteter Kommunikationssituation und einer Antizipation bzw. Realvorstellung einer unbeobachteten Kommunikationssituation (hier eben ohne Kamera) [zu vergleichen]. Freilich geht damit ein Stück weit subjektives Wissen der Analysierenden in den Vergleich ein, gleichwohl handelt es sich zumindest um ein 'erfahrungsgesättigtes' Wissen über vergleichbare Kommunikationssituationen (in der Regel gewonnen aus der Position eines/einer 'normalen' Kommunikationsteilnehmers/-teilnehmerin)" (S.372). [16]
Gerade Unterricht bietet ein derart vertrautes Terrain, dass es Forschenden scheinbar intuitiv gelingt, Situationen als "authentisch" einzuschätzen, d.h., dass sie hypothetisch ohne Aufnahmetätigkeit so geschehen würden. Wie genau diese Einschätzung jedoch vorgenommen werden kann, bleibt in den bisherigen Untersuchungen offen. Die von HEE genannten Aspekte der Kameraadressierung als Teilnehmerin bzw. bystander sowie des Einbezugs von Analytiker*innenwissen der Forschenden als Ressource für die Einschätzung von Invasivität halten wir für gewinnbringend (vgl. zu diesem Thema auch z.B. DEPPERMANN 2013). Daran wollen wir mit unseren Ausführungen im Folgenden anschließen und dies mit dem theoretischen Konzept des participation framework nach GOFFMAN (1979, S.11) verbinden. Weiterhin erfordern zwei weitere Aspekte u.E. aus methodologischer Sicht eine stärkere Beachtung: [17]
Zum einen gehen wir angesichts der Komplexität audiovisueller Daten von einem Invasivitätskontinuum aus, statt beobachtete Invasivitätseffekte numerisch zu kodieren und als diskrete Variable zu verstehen. Zum anderen erachten wir eine Reduzierung von Invasivität auf ihre immanenten Aspekte als problematisch. Wir nehmen vielmehr an, dass Invasivität als Wirkung der Dokumentations- oder Aufnahmetechnik in der Situation durch die Reaktionen der gefilmten Personen beobachtbar wird, die kontextabhängig unterschiedlich ausfallen können. Aus diesem Grund sehen wir insbesondere die Kontexte, in denen Reaktionen auf die Aufnahmetechnik sowie auf die Forschenden zu beobachten sind, als relevant für die Konstitution von Invasivität an. Wir plädieren dafür, das soziale Geschehen vor, während und nach den Aufnahmen systematisch für die Analyse und das Verstehen von Reaktanz und Invasivität zu nutzen. Mit unserem methodologischen Erkenntnisinteresse fokussieren wir somit insbesondere die Frage, welche Rolle der soziale, thematische, räumliche und zeitliche Kontext der Reaktion in der Aufnahmesituation spielt, da so die Verwendbarkeit der Aufnahmen unter Berücksichtigung des jeweiligen Forschungsgegenstandes bzw. der Fragestellung einschätzbar wird. [18]
In diesem Abschnitt führen wir unser terminologisches Instrumentarium ein, das wir für die Systematisierung unterschiedlicher Kontexte und Arten videografierter Reaktionen auf die Kamera und mitunter auf filmende Personen nutzen. Wir haben festgestellt, dass die Aufgenommenen die Kamera, aber auch filmende bzw. forschende Personen relevant setzen, indem sie diese mehr oder weniger direkt anblicken, ansprechen oder sich anders auf diese beziehen. Die unterschiedlichen Arten der Bezugnahme fassen wir unter dem Terminus Adressierung zusammen. Wir kritisieren die oftmals nahezu synonyme Verwendung der Termini Invasivität und Reaktanz (Abschnitt 3.1), denn die Unterscheidung zwischen Invasivität und Reaktanz ermöglicht uns eine Beschränkung auf wahrnehmbare Aspekte der kontextsensiblen Reaktionen auf die Aufnahmetätigkeit in Form von Reaktanz. In Abschnitt 3.2 stellen wir den dynamischen Kontextbegriff vor, den wir bei unserer Analyse verwenden. Abschließend führen wir in Abschnitt 3.3 eine Heuristik ein, die es uns erlaubt, Teilnehmendenrollen zu unterscheiden. Damit lehnen wir uns stark an die GOFFMANschen Überlegungen zum participation framework an. [19]
Im Folgenden meinen wir mit Kameraadressierungen nicht nur die Adressierung der Kamera als beobachtende Akteurin. Stattdessen verstehen wir die Kamera als eine technische Vorrichtung, die auf audiovisueller Ebene Personen das Beobachten des gefilmten Geschehens – in einer von der Aufnahmesituation zu unterscheidenden Situation (Betrachten des Videos) – ermöglicht. Wenn die Gefilmten in die Kamera blicken oder sprechen, ist in einigen Fällen nicht erkennbar, ob die Kamera, die Kameraperson oder antizipierte Betrachtende der Aufnahmen das Ziel der Aktion sind. In den meisten Fällen jedoch wird der Kamera in der Situation von den Beteiligten eine Bedeutung zugeschrieben. Wir verwenden den Terminus Kameraadressierungen sowohl bei Beispielen, in denen die Kamera alleine, die Kamera in Kombination mit einer Kameraperson oder nur die Forschungsperson relevant ist als auch bei denen, in denen antizipierte Videobetrachtende gemeint sind. [20]
Durch die Wahrnehmung der Aufnahmetechnik sowie ggf. der anwesenden Forschenden und das Bewusstsein, gefilmt zu werden, verhalten sich die Interagierenden voreinander und vor der Kamera mutmaßlich bisweilen anders, als es ohne sie der Fall wäre. Zur Benennung dieses Sachverhalts hat sich der Begriff Invasivität (PETKO et al. 2003, S.270; siehe auch Abschnitt 2) etabliert. Ziel vieler videobasierter Interaktionsanalysen ist es, auf Interaktionssituationen mit einer möglichst geringen Invasivität zurückgreifen zu können. Inwiefern sich die Gefilmten zu welchem Zeitpunkt der Aufnahme bewusst sind, ist zwar nicht beobachtbar, Reaktionen auf die Kamera hingegen sehr wohl. In Anlehnung an LAURIER und PHILO, die der methodologischen Einsicht folgen, nur das in den Daten Sichtbare und Hörbare für Analysen nutzen zu können (2006, S.183), sprechen wir dann von Reaktanz, wenn Reaktionen auf die Aufnahmetechnik und das anwesende technische bzw. Forschungspersonal in den Aufnahmen beobachtbar sind. Damit grenzen wir uns explizit von einem psychologischen Reaktanzkonzept ab. Unter Invasivität hingegen verstehen wir den Einfluss der Aufnahmetechnik und der kamerabedienenden Personen auf die Gefilmten, der eine mehr oder weniger starke Verhaltensänderung nach sich ziehen kann. Invasivität ist demnach nicht vollumfänglich beobachtbar, sondern nur graduell und kaum verlässlich einschätzbar. Eine wie dargestellt verstandene Reaktanz hingegen lässt sich empirisch ermitteln. Aufgrund unserer ethnomethodologisch-konversationsanalytisch informierten methodologischen Perspektive beziehen wir uns in diesem Beitrag ausschließlich auf solche Reaktionen, die sichtbar sind, auch wenn es möglich ist, dass eine innere Beschäftigung mit der Kamera stattfindet, die nicht sichtbar wird. [21]
Da wir empirisch untersuchen wollen, welche Rollen Gefilmte den Kameras in Aufnahmesituationen zuschreiben und wie sich dies auf die Verwendbarkeit der Aufnahmen für Analysen auswirkt, interessieren uns die im Videomaterial beobachtbaren Reaktionen auf die Aufnahmetechnik. Wir treffen somit zunächst Aussagen über die Qualität der Reaktanz in konkreten Aufnahmesituationen, die anschließend genutzt werden können, um Invasivität einzuschätzen. Wir nehmen an, dass Rückschlüsse von Reaktanz auf Invasivität in begrenztem Umfang möglich sind, weil es eine Schnittmenge zwischen beiden gibt. Wie diese einzuschätzen und wie relevant sie ist, wird sicherlich in Abhängigkeit von verschiedenen Forschungstraditionen unterschiedlich eingeschätzt, sodass auch das von uns im Folgenden vorgeschlagene Verfahren zur Analyse von Reaktanz und einer daran orientierten Einschätzung von Invasivität verschieden bewertet werden dürfte. [22]
Bei der Suche nach beobachtbaren Reaktionen auf die Aufnahmetechnik sind wir in unserem vielfältigen Datenmaterial immer wieder auf verschiedene Arten der Adressierungen der Kamera(s) gestoßen. Da durch diese Adressierungen – mögen sie stark, schwach, explizit, implizit, diffus oder eindeutig sein – die Rolle der Kamera und damit das gemeinsame Verständnis der Situation sichtbar ausgehandelt werden, untersuchen wir diese nach der Vorstellung der dafür genutzten Konzepte in Abschnitt 4. [23]
3.2 Kontext und Kontextualisierung
Die Bedeutung der Kamera in Aufnahmesituationen ist eng an das Wissen über ihre aktuelle Aufnahmetätigkeit gebunden. Dabei ist das Filmen mit dem Smartphone, wie es im Alltag häufig praktiziert wird, vom vorbereiteten Filmen zur wissenschaftlichen Datenerhebung zu unterscheiden.2) So werden i.d.R. Einwilligungen eingeholt und Videokameras genutzt, die als solche wahrgenommen und entweder mobil verwendet oder zielorientiert im Raum platziert und aktiviert werden. Bemerken die Gefilmten, dass die Kamera ausgeschaltet ist, verändert sich die Situation für sie, und sie schreiben der Kamera mitunter eine deutlich andere Bedeutung zu als einer offensichtlich aufnehmenden. Vergleicht man die Kamera mit menschlichen Beobachter*innen, wird das Problem deutlich: Eine von einer anwesenden Person durchgeführte Beobachtung wird als solche meist von den Beobachteten wahrgenommen. Dabei gibt es eine natürliche Selektivität durch die beobachtende Person, denn diese kann nicht alles wahrnehmen und notieren, was geschieht. Aufgrund der Vergänglichkeit der beobachteten Ereignisse kann die Beobachtung nicht wiederholt werden. Wird gefilmt, ist hingegen nicht transparent, wer sich wann und mit welchem Ziel die Aufnahmen anschauen wird. Zudem "übersieht" die Aufnahme innerhalb der gewählten Kameraeinstellung nichts, sodass aufgrund der Möglichkeit des wiederholten Betrachtens eine ganz andere Beobachtungsintensität eröffnet wird. Da die Beobachtung nicht (nur) in der Aufnahmesituation geschieht, ist diese eine Situation, in der die gefilmte Person das Beobachten der Aufnahmen nicht beobachten kann, sodass ihr ein Einwirken auf die zeitlich versetzte Beobachtungssituation strukturell unzugänglich bleibt. Eine ausgeschaltete Kamera, eine eingeschaltete Kamera und anwesende Beobachtende tragen daher auf sehr unterschiedliche Weise zum Kontext der jeweiligen Interaktion bei. [24]
Der Begriff des Kontexts wurde u.a. von Konversationsanalytiker*innen intensiv diskutiert (BILLIG 1999; SCHEGLOFF 1997). Obwohl keine einheitliche Haltung zur Nutzung von Kontextinformationen für die Analyse festzustellen ist, zeigt dieser Diskurs, dass es einen primären Kontext gibt, der von Gesprächsbeteiligten standardmäßig als relevant angenommen und genutzt wird: das in der Interaktion soeben und bisher Gesagte und Getane, auf das sich jede Äußerung in unterschiedlichem Maß bezieht. In dem sich turn by turn entfaltenden Gespräch wird die augenblickliche Äußerung im nächsten Moment ihrerseits zum Kontext, sodass jede Äußerung kontextgebunden ist, aber auch den Kontext erneuert (HERITAGE 1984). Die Interagierenden deuten die Äußerungen der Beteiligten kontextabhängig und passen die eigenen Gesprächsbeiträge so an, dass sie für die anderen Beteiligten – und damit für gewöhnlich auch für (wissenschaftlich) Beobachtende – verstehbar werden. [25]
Mit dem Kontextbegriff ist das Konzept der Sequenzialität verbunden, mit dem ein normativ geregeltes Nacheinander der Sprechbeiträge gemeint ist, sodass längere Redeüberlappungen als Abweichung behandelt werden.3) Wollen wissenschaftlich Beobachtende die Bedeutung einer Handlung oder Äußerung verstehen, sind sie auf das Verständnis der Interagierenden angewiesen und darauf, wie diese sich dies wechselseitig accountable (GARFINKEL 1967, S.9), also erkennbar und verstehbar, machen. Dafür ist es nötig, den sequenziellen Ablauf zu rekonstruieren, denn die Beteiligten orientieren sich während der fokussierten Äußerung am zuvor Geäußerten (first turn). In der darauffolgenden Äußerung der/des zweiten Beteiligten (second turn) wird deutlich, wie sie/er die erste Äußerung verstanden hat. In der an den zweiten turn anschließenden Äußerung der/des ersten Beitragenden (third turn) wird deutlich, ob er/sie mit der Interpretation, die im zweiten Beitrag offenbar wurde, übereinstimmt (SCHNEIDER 2000, S.125-126). Andernfalls kann die dritte Äußerung zur "Reparatur" (repair nach SCHEGLOFF, JEFFERSON & SACKS 1977, S.361) von dem oder der ersten Beteiligten genutzt werden. Wird sie dafür nicht genutzt, gehen die Beteiligten von einem geteilten Verständnis aus (SCHNEIDER 2000). Anders als in auditiv vermittelten Interaktionen wie beispielsweise Telefongesprächen zeigen sich die Beteiligten in Face-to-Face-Interaktionen gestisch, mimisch und mittels anderer Ausdrucksmodalitäten zeitlich überlappend und fein aufeinander abgestimmt ihr Verstehen an (MONDADA 2018), sodass die Sequenzialität im Normalfall keinem reinen Nacheinander folgt, sondern sich viele Aktivitäten zeitlich überlagern. Da sich die Beteiligten trotz zeitlichen Überschneidungen aber in ihrem Handeln auf Handlungen der oder des jeweils anderen beziehen, ist festzustellen, dass sie eine Ordnung des kausalen Nacheinanders erzeugen. Daher beziehen wir den Sequenzbegriff hier auch auf Handlungssequenzen. [26]
So kann eine Unterbrechung eines Sprechbeitrags durch Blickrichtungen hervorgerufen werden (GOODWIN 1980). Sprachliche Äußerungen werden häufig gestisch und mimisch begleitet, ergänzt oder modifiziert (GOODWIN & GOODWIN 1986). Für die Erzeugung einer gemeinsamen Orientierung (GOODWIN 1986) werden in bestimmten Situationen Gesten verwendet. Eine Arbeitshandlung in einer technisierten Arbeitsumgebung wird von anderen Beteiligten als Angebot oder Aufforderung für eine anschließende Arbeitshandlung verstanden und genutzt (HEATH & LUFF 1993). Weiterhin muss ein Beitrag zu einer Face-to-Face-Interaktion nicht unbedingt verbal sein oder sich auf verbale Beiträge beziehen, sondern es können Interaktionsepisoden völlig ohne gesprochene Sprache realisiert werden (SCHMITT 2012). Ein Kontextbegriff, der ausschließlich auf verbale Äußerungen bezogen wird, erscheint für eine Analyse audiovisueller Aufnahmen von Face-to-Face-Interaktionen nicht hilfreich. Auch ein eng verstandener Sequenzbegriff mit Beschränkung auf das normativ geordnete Nacheinander von Sprechbeiträgen greift aufgrund der vielfältigen Ausdrucksmöglichkeiten in Face-to-Face-Interaktionen zu kurz. In physisch ko-präsenten Interaktionen, bei denen die Beteiligten pragmatisch unterschiedliche Ausdrucksmodalitäten (MONDADA 2018; SCHMITT 2005) und/oder semiotische Felder (GOODWIN 2000) nutzen, müssen die Begriffe von Kontext und Sequenzialität erweitert und angepasst werden. [27]
Um im Hinblick auf diese Weiterentwicklungen des Kontext- sowie des Sequenzbegriffs Reaktionen auf Videokameras in Aufnahmesituationen zu untersuchen, beziehen wir uns im Folgenden auf die Kontextualisierungsanalyse von GUMPERZ (1992), wobei wir sie nicht auf Verbalität beschränken. Kontext ist diesem Verständnis nach der Hintergrund eines focal event (GOODWIN & DURANTI 1992, S.3); es ist quasi das aus einem Möglichkeitsraum Hervorgehobene, auf das der Fokus gelegt wird. Das, was verfügbar ist und potenziell auch hervorgehoben werden könnte, aber nicht hervorgehoben wurde, bleibt im Hintergrund und bildet den Kontext für das focal event. Dem Fokussierten kann mithilfe der Differenz zwischen Fokus und Kontext eine Bedeutung zugeschrieben werden. Das aus dem Möglichkeitsraum aktuell Fokussierte nennen wir in Anlehnung an GOODWIN und DURANTI das Kontextualisierte. Kontextualisiert können nicht nur vorherige Äußerungen werden, sondern auch Handlungen, Gegenstände oder Personen des gemeinsamen Wahrnehmungsraums, geteiltes Wissen oder geteilte Erfahrungen. Wir gehen somit nicht von einem statischen Kontextbegriff aus, den man als mehr oder weniger wirkmächtigen Prädiktor auf die Kommunikation annehmen könnte, sondern von einem dynamischen, bei dem die Beteiligten für sie verfügbare Gegebenheiten als Kontext nutzen und ihn so zugleich hervorbringen (AUER 1986). Werden interaktionsexterne Elemente zur Kontextualisierung einer Äußerung oder kommunikativen Handlung hinzugezogen, werden zusätzliche interpretationsleitende Hinweise nötig, die von GUMPERZ (1992, S.231) als contextualization cues bezeichnet wurden. Diese können auf unterschiedlichen Ebenen verbalen und nonverbalen Verhaltens liegen, sodass sowohl Lexik, Syntax und Prosodie als auch Gestik, Mimik, Körperposition oder Blickrichtung zum Anzeigen dafür verwendet werden können. Dies geschieht in Face-to-Face-Interaktionen in der Regel nicht in einer rein sukzessiven Ordnung des wohlumgrenzten Nacheinanders, wie es bei auditiv vermittelter Kommunikation der Normalfall ist, sondern ist aufgrund der körperlich-leiblichen Ausdrucksmöglichkeiten auf visueller und mitunter auch auf taktiler Ebene wahrnehmbar (vgl. dazu beispielhaft MONDADA & SCHMITT 2010): Während noch eine Äußerung oder eine Handlung ausgeführt wird, wird bereits die nächste – z.B. durch eine Umpositionierung des Körpers – vorbereitet (MONDADA 2019). Da für unsere Zwecke ein so feinschrittiges Vorgehen eher von der Argumentation ablenken würde, vereinfachen wir die Darstellung in den meisten Beispielen und gehen nur insofern darauf ein, wie es der Entwicklung des Arguments dient. [28]
Kontextualisierungshinweise geben Aufschluss über Adressierungen der Kamera oder (zukünftig) Betrachtender, die in Aufnahmesituationen mehr oder weniger präsent sind. Der Kamera und den Betrachtenden werden nur Rezipient*innenrollen zugeschrieben, nicht aber die Fähigkeit, Beiträge zur Interaktion zu produzieren. Dies zeigt sich im Umgang der Gefilmten mit der Kamera. Dabei ist aufschlussreich, wie und inwiefern die Kamera(person) oder die antizipierten Beobachtenden adressiert werden. [29]
Um unterschiedliche Adressierungen untersuchen zu können, benötigen wir eine Terminologie, die ein systematisches Beobachten zulässt. GOFFMAN (1979, S.11) schlug mit dem Konzept des participation framework differenzierte Teilnehmendenrollen für Face-to-Face-Interaktionen vor, die wir im Folgenden als Heuristik für die Analyse von Kameraadressierungen nutzen. Er stellte fest, dass in Interaktionssituationen häufig nicht nur ein*e Sprecher*in und ein*e Zuhörer*in anwesend sind, sondern es eventuell mehrere Zuhörende gibt und weitere Anwesende, die je nach Umstand mithören. Beim participation framework wird die Rezipient*innenseite (R) in zwei Kategorien unterteilt, die anschließend weiter ausdifferenziert werden. Es gibt einerseits ratifizierte Rezipient*innen, die sich als legitim Zuhörende ggf. aktiv an dem Gespräch beteiligen können (S.7f.). Diese bezeichnen wir in der folgenden Tabelle mit "Rr". Ratifizierte Rezipient*innen können entweder von den Äußerungsproduzierenden adressiert, das heißt angesprochen werden (Rra) oder nicht adressierte, anwesende und legitim Zuhörende sein (Rrn). Andererseits gibt es nicht ratifizierte Rezipient*innen (Rn), die zwar anwesend sind, jedoch keine Beiträge zum Gespräch leisten und dies auch nicht von ihnen erwartet wird. In dieser Gruppe sind Anwesende, die aufgrund der räumlichen Nähe zu den Gesprächsbeteiligten unbeabsichtigt Teile des Gesprächs oder sogar das gesamte Gespräch mithören, die GOFFMAN (S.8) overhearer nannte (Rno). Diese sind von solchen zu unterscheiden, die als illegitim Zuhörende aufmerksam zuhören, also lauschen (Rnl).
|
Abkürzung |
Erläuterung |
|
R |
Rezipient*in |
|
Rr |
ratifizierte*r Rezipient*in |
|
Rra |
adressierte*r ratifizierte*r Rezipient*in |
|
Rrn |
nicht adressierte*r ratifizierte*r Rezipient*in |
|
Rn |
nicht ratifizierte*r Rezipient*in |
|
Rno |
unbeabsichtigt mithörende*r nicht ratifizierte*r Rezipient*in |
|
Rnl |
lauschender nicht ratifizierte*r Rezipient*in |
Tabelle 1: Rezipient*innendifferenzierung nach GOFFMAN (1979) [30]
Bei naiven Rezipient*innenbegriffen wird davon ausgegangen, dass der*die Adressat*in auch das Ziel der Botschaft ist. Für Fälle, in denen das nicht zutrifft, schlug LEVINSON (1988, S.173) eine hilfreiche Differenzierung für die Kategorisierung von Adressierungen vor. Er unterschied, ob die Adressat*innen auch die Zielpersonen (target) waren, die letztendlich die Botschaft erhalten sollten. Nachrichten können also auch erstens an eine nicht anwesende Person, die nicht adressiert wird (ultimate target), überbracht werden. Dabei wird die adressierte Person Mittler*in (intermediary), und ihre Teilnahme ist ratifiziert (Rra), sie ist aber nicht die Zielperson. Oder die Zielperson ist zweitens zwar anwesend, wird aber nicht direkt adressiert, sondern andere Anwesende werden mit dem die Zielperson betreffenden Thema für die Zielperson wahrnehmbar adressiert, wobei die Zielperson entweder ratifiziert beteiligt (Rrn) sein kann oder aber nicht ratifiziert (Rno) ist, also entweder ein*e targeted overhearer oder eavesdropper (MEYER 2018, S.57-59) darstellt. [31]
Ein wichtiger Aspekt ist der Aushandlungsprozess der Kamerarolle zwischen den Beteiligten. Dabei werden zum einen die Produzent*innen- und die Rezipient*innenseite aufeinander bezogen, denn nicht nur die Kamera ist Adressatin, sondern in den gefilmten Situationen sind Wechsel in der Konstellation der Gefilmten entsprechend des participation frameworks beobachtbar, die Aufschluss über das Hervorbringen der Kamerarolle in Aufnahmesituationen geben. Zum anderen werden die Kontextualisierung der Beteiligten sowie ihre kamerabezogenen (Sprach-)Handlungen und Aktivitäten an Marjorie GOODWIN (2000) anschließend verfolgt, die die Einbettung der aktiv am Prozess der Interaktion Beteiligten herausstellte: "The analysis of participation within activities makes it possible to view actors as not simply embedded within context, but as actively involved in the process of building context" (S.178). Welche Rollen den Kameras oder den Forschenden bei dem Kontextualisierungsprozess zugeschrieben werden, bleibt daher eine empirisch zu klärende Frage, deren Beantwortung auch mit dem Einsatz der Kamera variieren dürfte. [32]
Das in Abschnitt 3 vorgestellte Instrumentarium wenden wir im Folgenden anhand verschiedener videografierter Sequenzen für eine empirische Untersuchung von Reaktanz an. Die Grundlage bilden dabei Videodaten aus unseren verschiedenen Projekten, aus denen wir Fälle ausgewählt haben, in denen die Kamera eine Rolle spielte. Wir wollen zeigen, dass unser Ansatz zur Erforschung von Reaktanz auf der einen Seite auf verschiedene Forschungskontexte und unterschiedliches Datenmaterial anwendbar ist, sodass sich eine gewisse Vergleichbarkeit herstellen lässt. Auf der anderen Seite berücksichtigen wir in der Analyse zugleich die Unterschiedlichkeit der Forschungskontexte, indem mittels des Konzepts der Kontextualisierung die Reaktanz jeweils vor dem Hintergrund der den Daten zugrunde liegenden Forschungsfrage interpretiert wird. Wir werden zunächst die Leitfragen vorstellen, die wir induktiv aus dem Vergleich unserer Daten entwickelt haben. In Abschnitt 4.2 untersuchen wir nacheinander aus jedem Forschungskontext exemplarisch zwei bis drei konkrete Datenbeispiele im Hinblick auf Reaktanz und diskutieren abschließend die Ergebnisse sowie theoretische, empirische und methodologische Implikationen. [33]
4.1 Analysefokus und Erkenntnisinteresse
Mit unserem Vergleich von Beispielen für Reaktanz aus unterschiedlichen Forschungsprojekten zeigen wir, dass den sozialen, thematischen, räumlichen und zeitlichen Kontexten von Aufnahmesituationen eine bedeutende Rolle zukommt. Um deren Kontextualisierungen zu ermitteln, haben wir datengeleitet Fragen entwickelt, die wir als Dimensionen von Reaktanz verstehen und die wir an jedes Datenbeispiel gestellt haben:
Wer wird adressiert? Hierbei soll gezeigt werden, ob die Kamera, die kamerabedienende Person oder antizipierte Betrachtende, die mehr oder weniger diffus sein können, adressiert und welche Rollen der*dem bzw. den Adressierten zugewiesen wurden.
Wie wird die Adressierung kontextualisiert? Mit dieser Frage wird untersucht, wie die Adressierung sozial, thematisch, zeitlich und räumlich kontextualisiert wurde und welche Konsequenzen sich daraus für die Interaktionssituation, in der sich die Beteiligten befanden, ergeben haben (vgl. auch LEVINSON 1983; STUKENBROCK 2015).
Wie stark ist die Adressierung? Eine Adressierung kann auf der einen Seite als stark angesehen werden, wenn der Blick in die Kamera gerichtet und in die Kamera gesprochen wird. Es sind auf der anderen Seite schwache Adressierungen möglich wie etwa ein schweifender Blick in die Kamera. Um z.B. die Stärke der Adressierung eines Blicks in die Kamera einschätzen zu können, muss jedoch fallspezifisch einerseits die Einbettung, andererseits die Adressierung selbst als Kontextualisierungshinweis betrachtet werden. Diese Aspekte sollen Auskunft über die Stärke der Kameraadressierung geben.
Wie eindeutig ist die Adressierung? Die Adressierung kann diffus erfolgen, sodass weder die Beteiligten noch die Beobachtenden eindeutig einschätzen können, inwiefern wer adressiert wird. Diese Dimension kann auf die anderen Dimensionen bezogen unterschiedliche Ausprägungen annehmen, es kann beispielsweise eindeutig eine Adressierung stattfinden, aber uneindeutig bleiben, wer genau adressiert wird. [34]
Mittels der Einordnung von Kameraadressierungen anhand der vier Fragen soll die je fallspezifische Reaktanz differenziert beobachtet und beschrieben werden, um die Verwendbarkeit der Daten analysebasiert einschätzen zu können. Damit schlagen wir eine Möglichkeit zur empirisch basierten Beurteilung von Invasivität auf der Grundlage der Analyse von Reaktanz vor. [35]
4.2 Analyse von Fallbeispielen zu Kameraadressierungen
Die folgenden sieben Datenauszüge entstammen unterschiedlichen empirischen Forschungsprojekten, in deren Rahmen wir Videoaufnahmen im Kontext von Schule und Ausbildung angefertigt haben. Die Beispiele sind nach abnehmender Reaktanzstärke geordnet. Wir führen zum besseren Verständnis jeweils zu Beginn der Beispiele kurz in die gefilmte Situation ein und analysieren die Sequenz dann hinsichtlich der vier unter Abschnitt 4.1 aufgeführten Fragen. Abschließend reflektieren wir die Ergebnisse der Analyse vor dem Hintergrund des dem jeweiligen Forschungsvorhaben zugrunde liegenden Erkenntnisinteresses. Obgleich die Beispiele auf institutionell gerahmte Interaktionen im Kontext von Schule und Ausbildung beschränkt sind, möchten wir anregen, weiterführend zu erforschen und zu diskutieren, inwiefern die Erkenntnisse auf andere Kontexte übertragbar sind oder sich als Kontrastfolie für Vergleiche mit anders gearteten Interaktionen und Kontexten eignen. [36]
4.2.1 Beispiel 1: Interaktion mit Kamera und Forscherin
Dieses Beispiel entstammt einem Deutsch-als-Fremdsprache-Unterricht in einer dänischen Vorschulklasse, hat also einen institutionellen Rahmen. Im rückwärtigen Bereich des Klassenzimmers befand sich auf jeder Seite eine Kamera, die Forscherin saß schräg hinter einer der beiden und fertigte Feldnotizen an. Diese Anordnung war zum Zeitpunkt der Aufnahme in dieser Lerngruppe bereits drei Monaten regelmäßig genutzt worden, jedoch mit einer Unterbrechung von sechs Wochen, die kurz zuvor geendet war. [37]
Im Klassenraum war auf jeder Seite eine Tischreihe angeordnet, an der die Lernenden Kaufmann spielten. Dabei standen einige Kinder als "Kaufleute" hinter den Tischen und einige als "Kund*innen" davor. Ein Schüler ging beim Wechsel von einer Tischreihe an die andere an einer der Kameras vorbei, blickte in die diese, ging bis zur anderen Tischreihe, schaute von dort aus erneut in die Kamera, lief dann auf diese zu, stieg auf einen Stuhl vor der Kamera, winkte hinein, sagte "hej" mit Blick in die Kamera und klopfte auf die Kameralinse. Hierdurch geriet die Kamera in den Wahrnehmungs- und Interaktionsfokus. Die Forscherin fragte ihn auf Deutsch nach seinem Namen, was er ebenfalls auf Deutsch beantwortete und umgekehrt auch die Forscherin nach ihrem Namen fragte, den sie ihm nannte. Die Forscherin fragte ihn auf Deutsch, ob er Deutsch möge, woraufhin er auf Dänisch antwortete, dass er nicht wisse, was das bedeute. Währenddessen beschäftigte er sich weiterhin mit der Kamera, blickte aber auch immer wieder zur Forscherin. Er drehte sich im weiteren Verlauf um, rief nach der Lehrkraft, wobei der Eindruck entstand, dass er ihr die Kamera zeigen wollte, da er direkt auf die Linse zeigte und schaute dann wieder in die Kamera. Nach etwa einer halben Minute entfernte er sich von der Kamera und richtete auch keine weiteren Blicke mehr in ihre Richtung. [38]
In der beschriebenen Situation adressierte der Schüler zunächst die Kamera. Nach Ansprache des Jungen durch die Forscherin adressierte er diese zunächst getrennt von der Kamera und danach abwechselnd beide. Sowohl der Kamera als auch der Forscherin wurde die Rolle der adressierten ratifizierten Rezipientin (Rra) zugewiesen. Dabei waren die Adressierungsstärke und die Eindeutigkeit hoch, da der Schüler durchgehend in die Kamera schaute und deutlich sichtbar mit ihr sowie der Forscherin interagierte. Nachdem er sich intensiv mit der Kamera auseinandergesetzt hatte, beachtete er sie sichtlich nicht weiter und wendete sich wieder der alltäglichen Unterrichtspraxis zu, wobei die Reaktanz geringer wurde. Es ist davon auszugehen, dass die anschließenden Aufnahmen für Analysen von mehrsprachigen Unterrichtsinteraktion (WILD 2020) genutzt werden können, da die Reaktanz zeitlich begrenzt war und sich nicht auf den lehrkraftseitigen Umgang mit mehrsprachigen Unterrichtssituationen auswirkte, was als Forschungsinteresse bei der Datengenerierung leitend war. [39]
4.2.2 Beispiel 2: Disziplinierung durch ein Dokumentationsmedium
Bei den Daten der folgenden zwei Beispiele (Auszüge 3 und 4) handelt es sich um Videoaufnahmen, die im schulischen Kontext entstanden sind. Die Schüler*innen nahmen an einer Gruppendiskussion zum Thema "TV-Serien" teil, die weder von der Forscherin moderiert noch durch eine anwesende Kameraperson begleitet wurde, sodass die Beteiligten die Gesprächsorganisation und -strukturierung selbst übernehmen mussten. Bei der Untersuchung, aus der die Beispiele in den Abschnitten 4.2.2 und 4.2.3 stammen, lag das Forschungsinteresse auf den Formen und Funktionen interaktiver Positionierungspraktiken von Jugendlichen beim Sprechen über Serien. Da sich die Gruppen jeweils aus Schüler*innen einer Lerngruppe zusammensetzten und die Gespräche in Räumlichkeiten der Schule stattfanden, lassen sich Kontextualisierungshinweise auf eine institutionelle Rahmung der Interaktionssituation rekonstruieren. [40]
Die in Auszug 3 abgebildete Sequenz begann mit einer negativen Bewertung der Moderatorin der Serie "Einsatz in vier Wänden" durch die Schüler*innen. Anschließend rahmte der Sprecher (JA, Z.08) diese Bewertung nachträglich für die abwesende Forscherin als scherzhafte Sanktion. Implizit verwies er mit einer humorvollen Schweigegeste sprachbegleitend zu der Äußerung "psch::;" (Z.05) und der Ermahnung "wenn die dich !HÖRT!;" (Z.06) auf die Aufnahme- und Speicherfunktion der Kamera, die diese Bewertung auch zukünftigen Betrachtenden des Videos zugänglich machte. Zunächst erschien die Forscherin als indirekte Zielperson, der die Rolle einer Lauscherin (eavesdropper) durch das Sprechen über sie (Z.06) zugeschrieben wurde. Kurz darauf änderte sich das participation framework dahingehend, dass die nicht anwesende Forscherin über die Kamera ratifiziert und adressiert wurde, da nicht über sie, sondern mit ihr (Z.08) gesprochen wurde. Damit signalisierten die Beteiligten, dass sie die Forscherin als Videobeobachterin antizipierten. Gleichsam setzten sie die Kamera als Dokumentations- und Speichermedium in den Interaktionsfokus, indem sie sich selbst für "Normverstöße" maßregelten. Rückwirkend wurde die Kamera damit während der Äußerung von OL (Z.02-03) als vorher nicht ratifizierte Rezipientin (Rn) markiert.
|
01 |
OL: |
((...)) |
|
02 |
|
die kann GAR nichts; |
|
03 |
|
=sieht IMmer hässlich aus. |
|
04 |
|
(2.0) |
|
05 |
JA: |
pach::; |
|
06 |
|
wenn die dich !HÖRT!; |
|
|
|
((deutet zur Kamera hin, blickt OL an)) |
|
07 |
|
=ne, |
|
08 |
|
also ha haben sie geHÖRT? |
|
|
|
((blickt in die Kamera)) |
|
09 |
OL: |
[(ja)] |
|
10 |
SO: |
[EIN]satz in vier wänden; |
Auszug 3: Disziplinierung durch Dokumentationsmedium [41]
Die Stärke der Adressierungen war hier relativ hoch, da JA offensichtlich über einen längeren Zeitraum hinweg in die Kamera blickte, sprach und zeigte. Die erste Adressierung (Z.06), bei der während des Zeigens auf die Kamera die Diskutierenden verbal angesprochen wurden, war weniger eindeutig als die zweite (Z.08), die – im Unterschied zur Sequenz in Abschnitt 4.2.1 – an die Forscherin gerichtet worden war. Das kamerabezogene Handeln sowie dessen Analyse sind in diesem Zusammenhang hilfreich, da sich mikroanalytisch rekonstruieren lässt, dass und wie sich die Jugendlichen gegenüber der Kamera bzw. der Forscherin positionierten, was Teil der Fragestellung war (WEISER-ZURMÜHLEN im Erscheinen). [42]
4.2.3 Beispiel 3: direkte Ansprache der Kamera
Während in dem vorherigen Datenauszug (Abschnitt 4.2.2) die Forscherin angesprochen wurde, auch wenn der Schüler in die Kamera sprach, ist die Adressierung im folgenden Beispiel (Auszug 4) weniger eindeutig erkennbar: Nachdem sich zwei Gesprächsstränge innerhalb der Gruppe ergeben hatten, wiesen zwei Personen auf die zuvor formulierte Instruktion hin, die Aufgabe gemeinsam zu bearbeiten (Z.05-08). Hieran zeigt sich exemplarisch, dass die Schüler*innen die Datenerhebungssituation bisweilen ähnlich einer Gruppenarbeitsphase kontextualisierten. Daraufhin entschuldigte sich eine Schülerin scherzhaft bei der Kamera (Z.08) und rückte sie damit in den Interaktionsfokus. Zwar wurde hier auf lexikalischer Ebene die Kamera direkt angesprochen und ihr damit quasi ein Interaktantinnenstatus zugesprochen (HEE 2018). Es kann allerdings aufgrund der vorherigen Kontextualisierungshinweise auch davon ausgegangen werden, dass sich diese Äußerung zusätzlich auf die Forscherin als antizipierte Beobachterin und damit adressierte, ratifizierte Rezipientin (Rra) bezog.
|
01 |
LE: |
deswegen warte ich ja auf die neue STAFfel (die bald kommt;) |
|
02 |
EM: |
die (dritte hat so REINgehauen) |
|
03 |
MA: |
die VIERte soll (xxx) |
|
04 |
EM: |
TSCHULdigung leute; |
|
05 |
|
tschuldigung wir hier. |
|
06 |
NE: |
wir müssen zuSAMmen reden; |
|
07 |
EM: |
ja tschuldigung ihr habt, ja gerade (xxx) |
|
08 |
LE: |
achso SORry kamera; |
|
|
|
((blickt in die Kamera)) |
|
09 |
JO: |
leute WISST ihr, |
Auszug 4: direkte Ansprache der Kamera [43]
In Bezug auf die kontextuelle Einbettung ist festzustellen, dass die Entwicklung unterschiedlicher Gesprächsstränge als Anlass genommen wurde, die Kamera zu adressieren. Verglichen mit der Sequenz in Abschnitt 4.2.2 sind Stärke und Eindeutigkeit der Adressierung hier im Sinne eines Kontinuums als relativ stark zu bestimmen, wenn auch nicht so stark wie in den ersten beiden Beispielen. [44]
Bei den Unterrichtsaufnahmen des nun folgenden Beispiels handelt es sich um die zeitlich-räumliche Entfaltung der Interaktion einer Schülergruppe. Dabei nutzen wir die Möglichkeiten einer Rekonstruktion der von uns in den Blick genommenen Handlungen nicht mittels einer multimodalen Analyse (s. hierzu Abschnitt 4.2.5), sondern veranschaulichen den Verlauf mit Bildfolgen. Diese entsprechen nicht den Perspektiven der bei der Datengenerierung genutzten Kameras, sondern sind Konstruktionen, die auf dem Verständnis des Geschehens beruhen, das wir mithilfe des Einsatzes von zwei Kameras und der so ermöglichten Mehrperspektivität entwickelt haben (BEELI-ZIMMERMANN, WANNACK & STAUB 2020). Bei dem Beispiel handelt es sich um Biologieunterricht in einer Mittelstufe, in dem in Kleingruppen gearbeitet wurde. Anhand eines Arbeitsblattes sollten Merkmale von verschiedenen Tierschädeln festgestellt werden, wobei jeder Kleingruppe ein anderer Tierschädel als Anschauungsmaterial diente. Die unterschiedlichen Schädel wurden nach dem Ablauf einer bestimmten Bearbeitungszeit im Uhrzeigersinn weitergereicht, was in Abbildung 1 durch gestrichelte Pfeile symbolisiert wird. Bei diesem Beispiel spielte die Gruppe 2 eine besondere Rolle, die sich aus fünf Jungen (J1-J5) zusammensetzte. Besonders interessant ist das Verhalten von J2, das auf die Kameras bezogen war (erst in Richtung Kamera 1, dann in Richtung Kamera 2), in Abbildung 1 mit Pfeilen mit durchgängigen Linien gekennzeichnet.
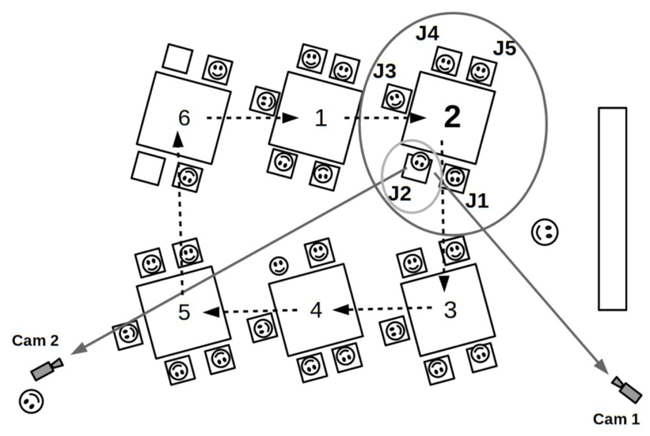
Abbildung 1: Übersicht des Klassenraums [45]
Da Gruppe 2 schneller mit der Bearbeitung des ersten Tierschädels fertig war als Gruppe 1, von der sie den nächsten Schädel erhalte sollte, entstand eine Situation, in der die Schüler der Gruppe 2 kein Anschauungsobjekt hatten und ihre Blicke durch den Klassenraum schweiften (Abb. 2, Bild 2).
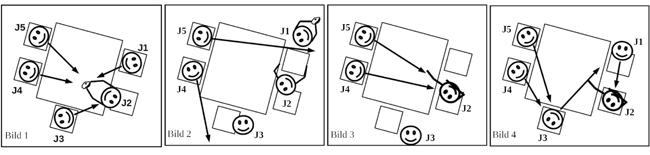
Abbildung 2: Comic 1 [46]
J2 blickte in die Kamera (Cam 1) und führte eine stilisierte Pose durch, die an das Posieren in (Musik-)Videos erinnert, was von J4 und J5 beobachtet wurde (Abb. 2, Bild 3). Dieses Posieren wurde auch von J1 bemerkt (Abb. 2, Bild 4), der soeben den Tierschädel bei der nächsten Gruppe (3) abgeliefert hatte und anschließend dieselbe Pose in Richtung Cam 1 ausführte (Abb. 3, Bild 1). Im nächsten Bild (Abb. 3, Bild 2) ist zu sehen, dass J4 vor Cam 1 und J2 in Richtung Cam 2 posierten und dadurch die Kamera in den Interaktionsfokus rückten. Dabei wurden sie von ihren Mitschülern J1 und J5 beobachtet. Während der Inszenierung wurde die Kameraperson durchgehend nicht beachtet, obwohl sie an die Kamera (Cam 2) herantrat.
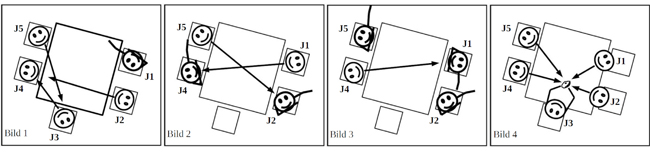
Abbildung 3: Comic 2 [47]
Daraufhin posierten J1 und J5 nicht vor der Kamera, sondern voreinander (Abb. 3, Bild 3). Als J3 mit dem nächsten Tierschädel zum Gruppentisch kam, schauten sich diesen alle an, ohne in die Kamera zu blicken. In diesem Beispiel wird deutlich, dass J2 alle Gruppenmitglieder, die gerade kein Anschauungsobjekt hatten, mit seiner Inszenierung animierte. Hier wird die Relevanz der sequenziellen Einbettung von Adressierungen erkennbar, denn aufschlussreich für die Kamerarolle ist der zeitliche Aspekt der Kontextualisierung der Kameras. [48]
Bemerkenswert ist, als was die Kameras adressiert und wie sie zur Adressierung genutzt wurden. Der Verwendungszusammenhang der Aufnahmen schien für die Schüler kaum eine Rolle zu spielen. Dies wird besonders durch das Ignorieren der Anwesenheit des Filmenden an der hinteren Kamera deutlich. Die Kameras wurden für Inszenierungen genutzt, die den Schülern aus anderen medialen Kontexten bekannt zu sein schienen, sodass der ratifizierte Adressat ein fiktives Publikum war. Daher war bei diesen Aktivitäten für die Schüler nicht die von den Forschenden intendierte Verwendung der Videos primär bedeutungsbildend, sondern die Inszenierung vor den Kameras für die Gruppenmitglieder. Die anderen Gruppenmitglieder erhielten so die Teilnehmerrollen von ratifizierten Rezipienten und wurden als Teil eines Publikums zu indirekten Adressaten (indirect target). Während den Kameras die Rolle von ratifizierten Rezipientinnen zukam (Rra), wurden mögliche spätere Betrachtende des Videos nicht sichtbar adressiert. [49]
Die Adressierungen waren, wenn auch nonverbal, stark und eindeutig. Von der offensichtlichen Reaktanz während der Inszenierungsphase lassen sich jedoch nicht zwingend Schlüsse auf den Grad der Invasivität der Kameras ziehen. Vielmehr sind die Daten im Hinblick auf die damit verfolgte Frage, in diesem Fall nach dem classroom management, auf ihre Verwendbarkeit zu prüfen. U.E. ergeben sich diesbezüglich keine Einschränkungen, da sichtbar wird, wie die Lehrkraft mit dem Problem umgegangen ist, dass bei einer Gruppe "Leerlauf" entstanden war. Die Nutzbarkeit für weitere Fragestellungen ist abzuwägen. [50]
4.2.5 Beispiel 5: doppelte Adressierung
Bei dieser Videoaufnahme aus einer Metallwerkstatt demonstrierte ein Ausbilder (AB) einem Praktikanten (P), wie mit der Fräsmaschine umgegangen werden sollte (GOERIGK 2018). Die Darstellung im Transkript erfolgte mit der Partiturschreibweise, wobei die Vorschläge von MONDADA (2018), allerdings modifiziert, genutzt wurden. Während der Demonstration schaute der Ausbilder kurz in die Kamera (Z.05, ca. 0.4 sec.), die vom Forschenden in der Hand gehalten wurde. Er ging einen Schritt auf den Praktikanten zu (Z.05) und schaute sich den Arbeitsgang an.
Auszug 5: doppelte Adressierung4). Bitte klicken Sie hier zum Herunterladen der PDF-Datei. [51]
Dann paraphrasierte er, näher am Praktikanten wie auch an der Kamera befindlich, das zuvor von ihm Gesagte: "das wird jetz paraLLEL gefrÄst;" (Z.06), wobei alle Anwesenden auf den Fräskopf schauten. Nur der Ausbilder blickte zwischenzeitlich ein zweites Mal kurz – jetzt ca. 0,8 sec. – in die Kamera. Diese Kontextualisierungshinweise lassen die Schlussfolgerung zu, dass er den Praktikanten, den anwesenden Kameramann und auch künftige Betrachter*innen des Videos adressiert haben könnte. Die Adressierung ist somit als eher stark, aber diffus einzuschätzen. Der Praktikant wurde als Lernender und somit als ratifizierter Rezipient (Rra) adressiert. Der anwesende Kameramann sowie potenzielle zukünftige Betrachtende der entstehenden Videoaufnahmen als Beobachtende einer Lehrpraxis wurden durch die wiederholte Blickzuwendung als Rezipient*innen ratifiziert (Rrn). Daher bleibt zu vermuten, dass die Form der Kommunikation ohne die Anwesenheit der Kamera und des Forschers im Feld anders ausgesehen hätte, auch weil der Ausbilder in diesem Beispiel das eigentliche Ziel der Äußerung offen ließ. [52]
Diese Art der Reaktanz ist analytisch für die Fragestellung nach der Ausbildungspraxis im Handwerk handhabbar, weil die Kamera und der Beobachter als legitime Beteiligte in Beobachter*innenrollen angesehen wurden, was bei der Analyse berücksichtigt werden konnte. Es ist anzunehmen, dass der Ausbilder "gute Lehrpraxis" präsentieren wollte, wobei Praktiken abgerufen wurden, von denen er möglicherweise annahm, sie seien für die Ausbildung typisch. Diese Einsichten können für die Analysen von Ausbildungspraxis genutzt werden, um die hier untersuchte Situation mit ähnlichen Gelegenheiten zu vergleichen, in denen der Ausbilder die Kamera weniger im Blick hatte bzw. ihr aufgrund von kommunikativer Involviertheit mit Auszubildenden weniger Aufmerksamkeit schenken konnte. [53]
4.2.6 Beispiel 6: fixierender Blick in die Kamera
Dieses Beispiel wurde im Englischunterricht einer dänischen Vorschulklasse aufgenommen. Die Kameras befanden sich zu diesem Zeitpunkt seit dreieinhalb Monaten im Raum, jedoch mit einer Unterbrechung von sechs Wochen, die kurz zuvor geendet war (vgl. Kamera-Setting in Abschnitt 4.2.1). Die Lehrkraft stand vorne im Klassenraum mit zwei Schülern an der Tafel, auf die Zahlen geschrieben wurden. Die Kinder sollten auf Zuruf der Lehrerin die genannte Zahl mit einer Fliegenklatsche berühren. Ein Mädchen, das sich weiter hinten im Raum befand, saß auf einem Tisch, schaute von der Tafel weg und drehte ihren Körper in Kamerarichtung. Dabei war ihr Blick zunächst gesenkt, sie hob dann ihren Kopf und sah für etwa vier Sekunden direkt in die eine der beiden rückwärtig aufgebauten Kameras. Schließlich wandte sie ihr Gesicht und ihren Blick der Tafel zu. Diese Handlungen können als Kontextualisierungshinweise dafür interpretiert werden, dass die Kamera zwischenzeitlich in den Wahrnehmungsfokus rückte. Ansonsten sind keine weiteren Kameraadressierungen sichtbar. [54]
Im Gegensatz zu den vorherigen Beispielen agierte die Schülerin hier nicht mit der oder für die Kamera, sondern zeigte lediglich an, dass sie diese vermutlich bewusst wahrnahm, auch wenn dies nicht sicher nachgewiesen werden kann. Die Adressierung ist eher schwach, aber dass sie stattfand, ist aufgrund der Körperpositionierung und der Veränderung des Blickwinkels leicht zu erkennen. Der Kamera wird hier die Rolle einer ratifizierten, aber nicht adressierten Rezipientin (Rrn) zugeschrieben, denn die Schülerin reagierte weder verbal noch nonverbal direkt auf die Kamera. Diese Szene erfolgte in einer alltäglichen Unterrichtssequenz, und die Schülerin verhielt sich nach der Szene nicht sichtlich anders als davor. Daher kann davon ausgegangen werden, dass die Kamera für sie weder davor noch danach besonders relevant war. Für den Untersuchungsfokus, nämlich mehrsprachige Unterrichtssituationen, ergeben sich keine Analyseeinschränkungen. [55]
4.2.7 Beispiel 7: schweifender Blick in die Kamera
In derselben Unterrichtsstunde wie in Abschnitt 4.2.6 skizziert sangen die Lernenden zusammen mit der Lehrkraft im Stehen ein Lied. Hierbei handelte es sich um ein Ritual zu Beginn der Stunde. Bevor die Lehrerin zur nächsten Aktivität überleitete, schaute sich ein Schüler um und streifte dabei mit einem Blick eine der Kameras, wobei er nicht bei dieser verweilte, d.h. die Kamera nicht fixierte, sondern nach einem fließenden Übergang zu dem hinter ihm stehenden Schüler blickte. Im weiteren Verlauf sah er nicht wieder Richtung Kamera. [56]
Die Kameraadressierung war diffus: Es ist nicht zweifelsfrei über Kontextualisierungshinweise zu bestimmen, ob tatsächlich eine Adressierung stattfand. Falls eine – wenn überhaupt schwache und nicht eindeutige – vorlag, so kam der Kamera die Rolle einer wahrscheinlich ratifizierten Rezipientin (Rrn) zu, auch wenn das participation framework nicht eindeutig und die Kamerarolle sowie der Wahrnehmungsfokus somit schwer einzuschätzen sind. Hier schien die Relevanz der Kamera relativ schwach zu sein, sodass nicht mit Einschränkungen der Analyse von mehrsprachigen Unterrichtssituationen zu rechnen ist. Es ist unwahrscheinlich, dass diese Reaktanz sich auf den Umgang von Lehrkräften mit Mehrsprachigkeit im Fremdsprachenunterricht auswirkte. [57]
Die Beispiele zeigen, inwiefern die vier Dimensionen Kontextualisierung, Adressat*in, Stärke und Eindeutigkeit der/des Adressierten bei der Einschätzung von Reaktanz hilfreich sein können. Sie lassen sich in zwei Gruppen unterteilen: Die ersten beiden Dimensionen beziehen sich auf Eigenheiten, die nicht einer Logik der Ausprägung folgen, die letzteren stellen Kontinuen dar. Die ersten beiden Dimensionen beziehen sich auf die zeitliche, räumliche, thematische und soziale Ebene des Kontexts. Die zeitliche Ebene wird erkennbar in den Abschnitten 4.2.1 (Interaktion mit Kamera und Forscherin), 4.2.4 (Inszenierung) und 4.2.6 (fixierender Blick in die Kamera), in denen die jeweilige Adressierung zeitlich dadurch eingrenzbar ist, dass es ein eindeutiges Davor und Danach der Adressierung gibt. Die räumliche Ebene wird in den Unterrichtsbeispielen ähnlich sichtbar. So befand sich in Abschnitt 4.2.1 der gefilmte Schüler in unmittelbarer Nähe der Kamera, die übrigen jedoch nahmen davon unbeeinflusst an der Unterrichtsinteraktion teil. Auch in Abschnitt 4.2.4 wurde deutlich, dass die Reaktanz räumlich beschränkt war, da nur eine Gruppe ein auf die Kamera gerichtetes Verhalten zeigte, während die anderen weiterarbeiteten. Die thematische Ebene wird in Abschnitt 4.2.1 daran deutlich, dass der gefilmte Schüler die Kamera als Gegenstand behandelte. In den beiden darauffolgenden Abschnitten (4.2.2: Disziplinierung durch Dokumentationsmedium; 4.2.3: direkte Ansprache der Kamera) wurde die Aufnahmesituation thematisiert und damit zum Inhalt der Äußerungen. Auch der implizite Verweis darauf, dass die Forscherin die Aufnahmen betrachten würde – und damit eine Angemessenheit des Ausdrucks (Abschnitt 4.2.2) und der Gesprächsführung (Abschnitt 4.2.3) angemahnt wurde – verweist auf die thematische und soziale Ebene des Kontexts. Letztere ist auch besonders bei den ersten vier Beispielen (Abschnitte 4.2.1-4.2.4) gut sichtbar. Nur durch das Einbeziehen dieser komplexen Konstellation kann Reaktanz angemessen verstanden und Invasivität eingeschätzt werden. Folglich sollten die zeitliche, räumliche, thematische und soziale Ebene von Kontextualisierungen systematisch aufeinander bezogen werden. [58]
Die dritte und vierte Dimension beziehen sich auf Ausprägungen der Adressierungen, wobei wir die Dimensionen als Kontinuen verstehen. Das Kontinuum der Adressierungsstärke kann in den dargestellten Fallbeispielen zwischen den Extrempolen sehr schwach bis sehr stark aufgespannt werden. Auf dem zweiten Kontinuum können Adressierungen orientiert an ihrer Eindeutigkeit eingeordnet werden. Mit eindeutigen Adressierungen meinen wir, dass für Forschende klar zu erkennen ist, wer in welcher Rolle adressiert wird (Abschnitt 4.2.1 & 4.2.2). Diffuse Adressierungen dagegen machen es schwierig einzuschätzen, ob jemand und/oder die Kamera bzw. in welcher Rolle die Person und/oder die Kamera adressiert wird (Abschnitt 4.2.7: schweifender Blick in die Kamera). [59]
Was bedeutet das für die Einschätzung der Verwendbarkeit der Aufnahmen, in denen Reaktanz sichtbar wurde? Wenn die Adressierung eindeutig ist, ist die Verwendbarkeit auch sehr gut einzuschätzen. Es zeigt sich, dass die Eindeutigkeit tendenziell mit der Stärke der Adressierung steigt. Aufgrund dieses Zusammenhangs stehen wir bei der Einschätzung der Verwendbarkeit von Videoaufnahmen mit Reaktanz vor einem Dilemma, denn einerseits ist Eindeutigkeit von Adressierungen gewünscht, andererseits ist eine starke Adressierung unerwünscht. Das eine geht aber mit dem anderen einher. Allgemeine Aussagen über die Verwendbarkeit der generierten Videodaten mit Reaktanz lassen sich allerdings ohnehin nicht treffen, denn diese müssen immer unter Einbezug des Forschungsinteresses, der Forschungsfrage und des (institutionellen) Kontexts fallbezogen beurteilt werden. [60]
Im vorliegenden Beitrag haben wir auf Basis von verschiedenen empirischen Fallbeispielen gezeigt, wie die zeitliche, räumliche, thematische und soziale Ebene des Kontexts der Aufnahmesituation für die Bestimmung von Reaktanz und die Einschätzung von Invasivität sowie die Verwendbarkeit der Daten genutzt werden kann. Dabei erwies sich das Vorgehen anhand der vier eingangs formulierten Fragen sowie des participation framework als zielführend, wobei auch die Grenzen dieser Herangehensweise deutlich wurden. Wir schlagen folgende Gliederung für ein Vorgehen zur Analyse von Reaktanz vor:

Abbildung 4: Vorschlag zum Vorgehen zur Analyse von Reaktanz [61]
Im Anschluss an die Operationalisierung von Invasivität in Form der Analyse von Reaktanz ergeben sich mittels der von uns vorgeschlagenen Heuristik einige Forschungsdesiderate. Einerseits ist die Reaktanz nicht immer eindeutig zu bestimmen (vgl. Abschnitt 4.2.6), andererseits kann das Vorhandensein von Aufnahmetechnik zwecks Aufnahmen in einer Situation auch da invasiv sein, wo keine Reaktanz sichtbar ist. So kann eine gefilmte Person z.B. aufgrund der Anwesenheit von Kameras und Kamerapersonen ihr Verhalten so verändern, dass es für Forschende nicht sichtbar wird – beispielsweise indem sie sich zurückhaltender verhält als dies üblicherweise der Fall ist. Auch das kann sich auf die Verwendbarkeit der Daten auswirken, ist aber nicht direkt beobachtbar und dadurch mit den hier angewandten Methoden nicht beurteilbar. [62]
Die empirischen Beispiele zeigen, dass eine vermutete Gewöhnung an die Kameras nicht unbedingt geringere Reaktanz nach sich zieht. Daher sollte der Gewöhnungseffekt kontextsensibel berücksichtigt werden (vgl. die Diskussion in Abschnitt 2). So legen die zitierten Interviewdaten in Abschnitt 2 nahe, dass gefilmte Personen die Situation (subjektiv) als Aufnahmesituation verstehen und sich mit diesem Verständnis an der Interaktion beteiligen, wodurch sie tatsächlich eine Aufnahmesituation herstellen. Anbieten würden sich einerseits verdeckte Aufnahmen, was allerdings aus ethischen und rechtlichen Gründen problematisch ist. Andererseits könnten Forschende ihre Erhebungen durch eine ethnografische Vorgehensweise ergänzen und so auf Basis ihrer Kenntnis des Feldes durch regelmäßige Beobachtungen eine Vergleichsfolie schaffen, um gezielt die für das Forschungsinteresse relevanten Unterschiede herauszuarbeiten. Letztlich müssen Forschende im Einzelfall unter Berücksichtigung der jeweiligen Fragestellung reflektieren, wie die Einschätzung der Reaktanz ggf. die Rekonstruktion der Interaktion relativieren bzw. verändern muss. Schließlich kann darauf basierend entschieden werden, inwiefern die Rolle, die der Kamera(person) und potenziellen Betrachtenden des Videos zugeschrieben wird, eine Verwendung der Aufnahmen als Datenmaterial erlaubt. [63]
Für Kommentare zu einem ersten Entwurf dieses Beitrags danken wir Inka FÜRTIG und Stephanie FALKENSTERN. Besonders bedanken wir uns bei den beiden anonymen Gutachter*innen für ihre konstruktiven und hilfreichen Anmerkungen.
Anhang: Transkriptionskonventionen
|
Zeichen |
Erklärung |
|
[ ] [ ] |
Überlappungen und Simultansprechen |
|
°h / h° |
Ein- bzw. Ausatmen |
|
; |
mittelstark fallende Tonhöhenbewegung am Ende einer Intonationsphrase |
|
. |
tief fallende Tonhöhenbewegung am Ende einer Intonationsphrase |
|
, |
mittelstark steigende Tonhöhenbewegung am Ende einer Intonationsphrase |
|
(.) |
Mikropause, geschätzt, bis ca. 0,2 Sek. Dauer |
|
und_äh |
Verschleifung innerhalb von Einheiten |
|
= |
schneller, unmittelbarer Anschluss an vorgängige Äußerung |
|
(2.0) |
Angabe der Pausendauer mit einer Stelle hinter dem Komma |
|
:: |
Dehnung, Längung um ca. 0,5-0,8 Sek. |
|
Fettdruck |
Verweis auf im Text behandelten Transkriptauszug |
|
akZENT |
Fokusakzent |
|
ak!ZENT! |
Extra starker Akzent |
|
((Ergänzung)) |
para- und außersprachliche Handlungen u. Ereignisse |
|
(ja) |
vermuteter Wortlaut |
|
(xxx) |
unverständliche Silbe |
Tabelle 2: verwendete Transkriptionszeichen nach SELTING (2009)
1) In diesem und im folgenden Transkript wurde entsprechend den Transkriptionskonventionen zur Erstellung eines Minimaltranskripts nach dem Gesprächsanalytischen Transkriptionssystem 2 (SELTING et al. 2009) nicht den Rechtschreibregeln gefolgt, sondern es wurde alles klein geschrieben, was nicht besonders betont wurde. Weitere in diesem Beitrag gebrauchte Transkriptionszeichen sind im Anhang aufgeführt. Da für Transkripte aufgrund von eingeschränkten Formatierungsmöglichkeiten keine äquidistante Schriftart verwendet werden konnte, beginnen simultane Sprechbeiträge jeweils am Zeilenanfang. <zurück>
2) Dies trifft bei im Alltag angefertigten Aufnahmen mit dem Smartphone in Abhängigkeit vom Kontext auch zu, wenn auch mitunter in sehr unterschiedlicher Weise. Filmen bedeutet in unterschiedlichen Situationen Verschiedenes: Das Filmen von Unfällen auf Autobahnen, das Erstellen eines kurzen Grußes vom Urlaubsort per Videobotschaft auf einem öffentlichen Platz in Anwesenheit anderer oder das spontane Aufnehmen einer Polizeikontrolle sind vor allem aufgrund der weiteren Verwendung mehr oder weniger moralisch aufgeladen. Diese Aufladung ist im Kontext von Aufnahmen, die für wissenschaftliche Zwecke angefertigt werden, aufgrund der Zusicherung 1. des Ausschlusses negativer Folgen für die Gefilmten und 2. des Rechts der Gefilmten auf Einsicht und Löschung in die gesicherten Aufnahmen deutlich abgeschwächt. In öffentlichen Räumen dürften die Unterschiede zumindest nicht so deutlich sein. Wir beziehen uns hier ausschließlich auf Aufnahmetätigkeiten, die für die Beteiligten als Datengenerierung für wissenschaftliche Zwecke deutlich werden. <zurück>
3) Neben dem hier gebrauchten Sequenzbegriff mit seinen unterschiedlichen Erweiterungen nutzten besonders im deutschsprachigen Raum Forscher*innen Sequenzanalysen im Rahmen weiterer Verfahren, bei denen eine Sequenz entsprechend des Verfahrensziels definiert wurde. Siehe zur Sequenzanalyse der sozialwissenschaftlichen Hermeneutik REICHERTZ und ENGLERT (2011), der objektiven Hermeneutik OEVERMANN (2012) sowie SAMMET und ERHARD (2018), der dokumentarischen Methode BOHNSACK (2003) sowie BOHNSACK und NOHL (2001) für eine übersichtliche Illustration an einem empirischen Beispiel. <zurück>
4) Auch in diesem Transkriptausschnitt wurden für die verbalsprachliche Transkription die Konventionen des Gesprächsanalytischen Transkriptionssystems 2 (SELTING et al. 2009) verwendet, s. den Anhang. Bei der Annotation der Blickrichtung wurde die von MONDADA (2018) vorgeschlagene Erweiterung für multimodale Transkripte genutzt. Mit dem Ziel die Lesbarkeit für Leser*innen zu erhöhen, die mit dieser Annotationsweise nicht vertraut sind, sind wir von MONDADAs Vorschlägen leicht abgewichen, indem wir je Akteur*in eine Zeile für die Blickrichtung eingefügt und entsprechend benannt haben. Das Wort hinter der doppelten eckigen Klammer ">>Kamera-- >" gibt das Objekt an, auf das die Augen gerichtet sind, also die Blickrichtung. Mit "#" wird angegeben, welchem Moment des Videos das in das Transkript eingefügte Bild entnommen ist. <zurück>
Auer, Peter (1986). Kontextualisierung. Studium Linguistik, 19, 22-47.
Beeli-Zimmermann, Sonja; Wannack, Evelyne & Staub, Sabina (2020). Videobasierte Unterrichtsforschung: Aufnahmen mit zwei Kameras – und dann?. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 21(2), Art. 20, http://dx.doi.org/10.17169/fqs-21.2.3298 [Zugriff: 20. Januar 2021].
Bergmann, Jörg R. (2007). Flüchtigkeit und methodische Fixierung sozialer Wirklichkeit – Aufzeichnungen als Daten der interpretativen Soziologie. In Heiko Hausendorf (Hrsg.), Gespräch als Prozess. Linguistische Aspekte der Zeitlichkeit verbaler Interaktion (S.22-68). Tübingen: Narr.
Billig, Michael (1999). Whose terms? Whose ordinariness? Rhetoric and ideology in conversation analysis. Discourse & Society, 10(4), 543-582.
Bohnsack, Ralf (2003). Dokumentarische Methode und sozialwissenschaftliche Hermeneutik. Zeitschrift für Erziehungswissenschaft, 6(4), 550-570.
Bohnsack, Ralf & Nohl, Arnd-Michael (2001). Exemplarische Textinterpretation: die Sequenzanalyse der dokumentarischen Methode. In Ralf Bohnsack, Iris Nentwig-Gesemann & Arnd-Michael Nohl (Hrsg.), Die dokumentarische Methode und ihre Forschungspraxis. Grundlagen qualitativer Sozialforschung (S.325-329). Opladen: Leske + Budrich.
Bühler, Karl (1982 [1934]). Sprachtheorie. Die Darstellungsfunktion der Sprache (2. Aufl.). Stuttgart: Fischer.
Corsten, Michael (2018). Videoanalyse – quo vadis?. In Christine Moritz & Michael Corsten (Hrsg.), Handbuch Qualitative Videoanalyse (S.799-817). Wiesbaden: Springer VS.
Deppermann, Arnulf (2013). Analytikerwissen, Teilnehmerwissen und soziale Wirklichkeit in der ethnographischen Gesprächsanalyse. In Arnulf Deppermann & Martin Hartung (Hrsg), Gesprochenes und Geschriebenes im Wandel der Zeit. Festschrift für Johannes Schwitalla (S.32-59). Mannheim: Verlag für Gesprächsforschung, https://ids-pub.bsz-bw.de/files/2971/Deppermann_Analytikerwissen_2013.pdf [Zugriff: 18. Januar 2021].
Dinkelaker, Jörg & Herrle, Matthias (2009). Erziehungswissenschaftliche Videographie: Eine Einführung. Wiesbaden: VS Verlag für Sozialwissenschaften.
Dreischenkämper, Christian & Stanik, Tim (2014). Die Reaktivitätsproblematik von Videographien. In Jochen Kade, Matthias Herrle, Sigrid Nolda & Jörg Dinkelaker (Hrsg.), Videographische Kursforschung. Empirie des Lehrens und Lernens Erwachsener (S.41-54). Stuttgart: Kohlhammer.
Erichsen, Göntje (in Vorbereitung). Zweitsprachaneignung als Kokonstruktion. Zur Rekonstruktion von Zweitsprachaneignungsprozessen in Interaktion unter Berücksichtigung ihrer schulischen Situiertheit (Arbeitstitel der Dissertationsschrift). Bielefeld: Universität Bielefeld.
Fankhauser, Regula (2013). Videobasierte Unterrichtsbeobachtung: die Quadratur des Zirkels?. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 14(1), Art. 24, https://doi.org/10.17169/fqs-14.1.1868 [Zugriff: 21. Januar 2021].
Fankhauser, Regula (2016). Sehen und Gesehen Werden – Zum Umgang von Lehrpersonen mit Kamera und Videografie in einer Lehrerinnen- und Lehrerweiterbildung. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 17(3), Art. 9, https://doi.org/10.17169/fqs-17.3.2561 [Zugriff: 19. Februar 2021].
Garfinkel, Harold (1967). Studies in ethnomethodology. Englewood Cliffs, NJ: Prentice-Hall.
Goerigk, Paul (2018). Handwerkliche Berufsbildung in Aktion. Eine ethnomethodologische Annäherung. In Franz Erhard & Kornelia Sammet (Hrsg.), Sequenzanalyse praktisch (S.394-419). Weinheim: Beltz Juventa.
Goffman, Erving (1979). Footing. Semiotica, 25(1), 1-30.
Goodwin, Charles (1980). Restarts, pauses, and the achievement of a state of mutual gaze at turn-beginning. Social Inquiry, 50(3-4), 272-302.
Goodwin, Charles (1986). Gestures as a resource for the organization of mutual orientation. Semiotica, 62(1-2), 29-49.
Goodwin, Charles (2000). Action and embodiment within situated human interaction. Journal of Pragmatics, 32(10), 1489-1522.
Goodwin, Charles & Duranti, Alessandro (1992). Rethinking context: An introduction. In Alessandro Duranti & Charles Goodwin (Hrsg.), Rethinking context. Language as an interactive phenomenon (S.1-42). Cambridge: Cambridge University Press.
Goodwin, Marjorie H. (2000). Participation. Journal of Linguistic Antropology, 9(1/2), 177-180.
Goodwin, Marjorie H. & Goodwin, Charles (1986). Gesture and coparticipation in the activity of searching for a word. Semiotica, 62(1/2), 51-57.
Gumperz, John J. (1992). Contextualization and understanding. In Alessandro Duranti & Charles Goodwin (Hrsg.), Rethinking context. Language as an interactive phenomenon (S.229-252). Cambridge: Cambridge University Press.
Heath, Christian & Luff, Paul (1993). Kooperation, Kontrolle, Krisenmanagement. Multimedia-Technologie in der Londoner "Underground". In Ina Wagner (Hrsg.), Kooperative Medien. Informationstechnische Gestaltung moderner Organisationen (S.153-190). Frankfurt/M.: Campus.
Hee, Katrin (2018). Das Aufzeichnungsmedium als Interaktant. In Christine Moritz & Michael Corsten (Hrsg.), Handbuch Qualitative Videoanalyse (S.365-383). Wiesbaden: Springer VS.
Heritage, John (1984). Garfinkel and Ethnomethodology. Cambridge: Polity Press.
Krelle, Michael (2014). Videographie von Deutschunterricht – Methodische Anmerkungen und Hinweise. In Astrid Neumann & Isabelle Mahler (Hrsg.), Empirische Methoden der Deutschdidaktik. Audio- und videografierende Unterrichtsforschung (2. Aufl., S.78-97). Baltmannsweiler: Schneider Verlag Hohengehren.
Labov, William (1972). Sociolinguistic patterns (10. Aufl.). Philadelphia, PN: University of Pennsylvania Press.
Latour, Bruno (2007). Reassembling the social. An introduction to actor-network-theory. Oxford: Oxford University Press.
Laurier, Eric & Philo, Chris (2006). Natural problems of naturalistic video data. In Hubert Knoblauch, Bernt Schnettler, Hans-Georg Soeffner & Jürgen Raab (Hrsg.), Video analysis: Methodology and methods. Qualitative audiovisual data analysis in sociology (3. Aufl., S.181-190). Frankfurt/M.n: Peter Lang.
Levinson, Stephen C. (1983). Pragmatics. Cambridge: Cambridge University Press.
Levinson, Stephen C. (1988). Putting linguistics on a proper footing: Explorations in Goffman's concepts of participation. In Paul Drew & Tony Wootton (Hrsg.), Erving Goffman. Exploring the interaction order (S.161-227). Cambridge: Polity Press.
Maak, Diana & Ricart Brede, Julia (2014). Empirische Erfassung von Invasivität in videografierten Lehr-Lernsituationen: Entwicklung und Erprobung eines Beobachtungssystems. In Astrid Neumann & Isabelle Mahler (Hrsg.), Empirische Methoden der Deutschdidaktik. Audio- und videografierende Unterrichtsforschung (2. Aufl., S.151-173). Baltmannsweiler: Schneider Verlag Hohengehren.
Markle, D. Thomas; West, Richard E. & Rich, Peter J. (2011). Beyond transcription: Technology, change, and refinement of method. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(3), Art. 21, https://doi.org/10.17169/fqs-12.3.1564 [Zugriff: 19. Februar 2021].
Meyer, Christian (2018). Culture, practice, and the body. Conversational organization and embodied culture in North-Western Senegal. Stuttgart: Metzler.
Mohn, Bina Elisabeth (2008). Im Denkstilvergleich entstanden: Die Kamera-Ethnographie. In Birgit Griesecke & Erich-Otto Graf (Hrsg.), Ludwig Flecks vergleichende Erkenntnistheorie (S.211-234). Berlin: Parerga.
Mondada, Lorenza (2008). Using video for a sequential and multimodal analysis of social interaction: Videotaping institutional telephone calls. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(3), Art. 39, https://doi.org/10.17169/fqs-9.3.1161 [Zugriff: 24. Februar 2021].
Mondada, Lorenza (2018). Multiple temporalities of language and body in interaction: Challenges for transcribing Multimodality. Research on Language and Social Interaction, 51(1), 85-106.
Mondada, Lorenza (2019). Transcribing silent actions: A multimodal approach of sequence organization. Social Interaction. Video-Based Studies of Human Sociality, 2(1), https://tidsskrift.dk/socialinteraction/article/view/113150/161804 [Zugriff: 22. Januar 2021].
Mondada, Lorenza & Schmitt, Reinhold (2010). Zur Multimodalität von Situationseröffnungen. In Lorenza Mondada & Reinhold Schmitt (Hrsg.), Situationseröffnungen. Zur multimodalen Herstellung fokussierter Interaktion (S.7-52). Tübingen: Narr.
Moritz, Christine (2011). Die Feldpartitur. Multikodale Transkription von Videodaten in der Qualitativen Sozialforschung. Wiesbaden: VS Verlag für Sozialwissenschaften.
Oevermann, Ulrich (2012). Die Methode der Fallrekonstuktion in der Grundlagenforschung sowie der klinischen und pädagogischen Praxis. In Klaus Kraimer (Hrsg.), Die Fallrekonstruktion. Sinnverstehen in der sozialwissenschaftlichen Forschung (2. Aufl., S.58-156). Frankfurt/M.: Suhrkamp.
Petko, Dominik; Waldis, Monika; Pauli, Christine & Reusser, Kurt (2003). Methodologische Überlegungen zur videogestützten Forschung in der Mathematikdidaktik. Ansätze der TIMSS 1999 Video Studie und ihrer schweizerischen Erweiterung. ZDM Zentralblatt für Didaktik der Mathematik, 35(6), 265-280.
Reh, Sabine (2012). Mit der Videokamera beobachten. In Heike de Boer & Sabine Reh (Hrsg.), Beobachtung in der Schule – Beobachten lernen (S.151-169). Wiesbaden: Springer VS.
Reichertz, Jo & Englert, Carina Jasmin (2011). Einführung in die qualitative Videoanalyse. Eine hermeneutisch-wissenssoziologische Fallanalyse. Wiesbaden: VS Verlag für Sozialwissenschaften.
Sammet, Kornelia & Erhard, Franz (2018). Methodologische Grundlagen und praktische Verfahren der Sequenzanalyse. In Franz Erhard & Kornelia Sammet (Hrsg.), Sequenzanalyse praktisch (S.15-72). Weinheim: Beltz Juventa.
Schegloff, Emanuel A. (1997). Whose text? Whose context?. Discourse & Society, 8(2), 165-187.
Schegloff, Emanuel A.; Jefferson, Gail & Sacks, Harvey (1977). The preference for self-correction in the organization of repair in conversation. Language, 53(2), 361-382.
Schmitt, Reinhold (2005). Zur multimodalen Struktur von turn-taking. Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion, 6, 17-61, http://www.gespraechsforschung-online.de/fileadmin/dateien/heft2005/ga-schmitt.pdf [Zugriff: 13. Januar 2021].
Schmitt, Reinhold (2012). Gehen als situierte Praktik: "Gemeinsam gehen" und "hinter jemandem herlaufen". Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion, 13, 1-44, http://www.gespraechsforschung-online.de/fileadmin/dateien/heft2012/ga-schmitt.pdf [Zugriff: 13. Januar 2021].
Schneider, Wolfgang L. (2000). The sequential production of social acts in conversation. Human Studies, 23(2), 123-144.
Schnettler, Bernt & Knoblauch, Hubert (2009). Videoanalyse. In Stefan Kühl (Hrsg.), Handbuch Methoden der Organisationsforschung. Quantitative und qualitative Methoden (S.272–297). Wiesbaden: VS.
Selting, Margret; Auer, Peter; Barth-Weingarten, Dagmar; Bergmann, Jörg; Bergmann, Pia; Birkner, Karin; Couper-Kuhlen, Elizabeth; Deppermann, Arnulf; Gilles, Peter; Günthner, Susanne; Hartung, Martin; Kern, Friederike; Mertzlufft, Christine; Mayer, Christian; Morek, Miriam; Oberzaucher, Frank; Peters, Jörg; Quasthoff, Uta M.; Schütte, Wilfried; Stukenbrock, Anja & Uhmann, Susanne (2009). Gesprächsanalytisches Transkriptionssystem 2 (GAT 2). Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion, 10, 353-402, http://www.gespraechsforschung-online.de/fileadmin/dateien/heft2009/px-gat2.pdf [Zugriff: 03.05.2021].
Stukenbrock, Anja (2015). Deixis in der face-to-face-Interaktion. Berlin: De Gruyter.
Tuma, René & Schnettler, Bernt (2014). Videographie. In Nina Baur & Jörg Blasius (Hrsg.), Handbuch Methoden der empirischen Sozialforschung (S.875-886). Wiesbaden: Springer VS.
Tuma, René; Schnettler, Bernt & Knoblauch, Hubert (2013). Videographie. Einführung in die interpretative Videoanalyse sozialer Situationen. Wiesbaden: Springer VS.
Tuncer, Sylvaine (2016). The effects of video recording on office workers' conduct, and the validity of video data for the study of naturally-occurring interactions. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 17(3), Art. 7, https://doi.org/10.17169/fqs-17.3.2604 [Zugriff: 22. Januar 2021].
Voloshchuk, Olena & Grießhaber, Wilhelm (2010). Videographie und Transkriptionsverfahren in dem Projekt "Erwerb des Englischen als dritte Sprache bei zugewanderten Schülern und Schülerinnen mit Russisch als Muttersprache". In Karin Aguado (Hrsg.), Fremdsprachliches Handeln beobachten, messen, evaluieren. Neue methodische Ansätze der Kompetenzforschung und der Videographie (S.215-229). Frankfurt/M.: Peter Lang.
Wagner-Willi, Monika (2004). Videointerpretation als mehrdimensionale Mikroanalyse am Beispiel schulischer Alltagsszenen. Zeitschrift für qualitative Bildungs-, Beratungs- und Sozialforschung, 5(1), 49-66.
Weiser-Zurmühlen, Kristin (im Erscheinen). Vergemeinschaftung und Distinktion. Eine gesprächsanalytische Studie über Positionierungspraktiken in Diskussionen über TV-Serien. Berlin: De Gruyter.
Wild, Kathrin (2020). Umgang mit unbeabsichtigten Sprachenwechseln im frühen gleichzeitigen Fremdsprachenunterricht. Zeitschrift für Interkulturellen Fremdsprachenunterricht, 25(1), 1049-1080.
Zum Autor und zu den Autorinnen
Paul GOERIGK ist als Soziologe wissenschaftlicher Mitarbeiter im Projekt Biprofessional sowie an der Bielefeld School of Education (BiSEd). Er promoviert zu Ordnungen der Interaktion im Kontext von handwerklicher Berufsbildung.
Kontakt:
Paul Goerigk
Universität Bielefeld
Bielefeld School of Education
Universitätsstraße 25, 33619 Bielefeld
Tel: +49 (0)521-106 4245
E-Mail: paul.goerigk@uni-bielefeld.de
Kristin WEISER-ZURMÜHLEN ist Akademische Rätin am Institut für Germanistik der Bergischen Universität Wuppertal. Sie hat zu Positionierungspraktiken von Schüler*innen im Kontext von Serienkommunikation promoviert. Ihre Forschungsschwerpunkte liegen in den Bereichen der Gesprächsforschung und Positionierungsanalyse, Medien und Interaktion sowie Sprach- und Mediendidaktik.
Kontakt:
Dr. Kristin Weiser-Zurmühlen
Bergische Universität Wuppertal
Fakultät für Geistes- und Kulturwissenschaften / Germanistik
Gaußstraße 20, 42119 Wuppertal
Tel: +49 (0)202-439-5333
E-Mail: weiser-zurmuehlen@uni-wuppertal.de
Göntje ERICHSEN ist wissenschaftliche Mitarbeiterin am Department Deutsch als Fremd- und Zweitsprache und Mehrsprachigkeit an der Universität Bielefeld. Sie promoviert zu Zweitsprachaneignungsprozessen in Unterrichtsinteraktion unter neuzugewanderten Schüler*innen und deren Beschulungssituation.
Kontakt:
Göntje Erichsen
Universität Bielefeld
Department Deutsch als Fremd- und Zweitsprache und Mehrsprachigkeit
Universitätsstraße 25, 33619 Bielefeld
Tel: +49 (0)521-106 3615
E-Mail: g.erichsen@uni-bielefeld.de
Kathrin WILD ist wissenschaftliche Koordinatorin des Projekts "Partners in Mobility / Lehramt.International" an der Europa-Universität Flensburg. Sie hat zu Aussprache und Musik promoviert und arbeitet derzeit an einem Forschungsprojekt zu frühem gleichzeitigen Fremdsprachenlernen. Ihre Forschungsschwerpunkte liegen in den Bereichen Ausspracheerwerb und -didaktik, individuelle Faktoren beim Sprachenlernen, früher gleichzeitiger Fremdsprachenunterricht, individuelle Mehrsprachigkeit, Mehrsprachigkeitsdidaktik und Unterrichtsinteraktion.
Kontakt:
Dr. Kathrin Wild
Europa-Universität Flensburg
Auf dem Campus 1b, 24943 Flensburg
Tel: +49 (0)461 805-2050
E-Mail: kathrin.wild@uni-flensburg.de
Goerigk, Paul; Weiser-Zurmühlen, Kristin; Erichsen, Göntje & Wild, Kathrin (2021). Zur Einschätzung von Reaktanz und Invasivität in videografischen Daten. Ein kontextsensibler Ansatz zur Beurteilung der Kamerarolle in Aufnahmesituationen [63 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 22(2), Art. 3, http://dx.doi.org/10.17169/fqs-22.2.3547.

Creative Commons Attribution 4.0 International License