Volume 6, No. 1, Art. 24 – Januar 2005
Sekundäranalyse von Audiodaten. Technische Verfahren zur faktischen Anonymisierung und Verfremdung
Henning Pätzold
Zusammenfassung: Qualitatives Material in Form von Audiodaten weist eine relativ geringe Anonymität auf, da zu dem verbalen Inhalt auch paraverbale Aspekte einschließlich individueller stimmlicher Merkmale hinzukommen. Das erschwert die Sekundäranalyse (und im Prinzip jede Auswertung durch Personen, die nicht an der Erhebung beteiligt waren) umso mehr, je höher die Wahrscheinlichkeit ist, dass Forschende und Befragte einander begegnen (bzw. miteinander sprechen). In diesem Beitrag werden zwei technische Verfahren vorgestellt, mit denen sich eine Audioquelle so weit gehend verfremden lässt, dass ein Wiedererkennen nicht viel leichter möglich ist als anhand eines sorgfältigen Transkriptes. Diese technischen Möglichkeiten und auch Grenzen der Anonymisierung qualitativer Daten werden im Folgenden diskutiert.
Keywords: Sekundäranalyse, Audiodaten, verbale Daten, Anonymisierung
Inhaltsverzeichnis
1. Einleitung
2. Aufgabe: Verfremdung
3. Vorgehensweise
3.1 Vorbereitung: Entfernen persönlicher Informationen
3.2 Variante 1: Verfremdung mit Vocodersoftware
3.2.1 Probleme
3.3 Variante 2: Verfremdung durch Tonhöhenveränderung (pitch shifting)
3.3.1 Probleme
4. Wie weit reicht die Anonymisierung?
5. Softwarehinweise
Für qualitativ arbeitende Forschende ist die Welt im ersten Zugriff zumeist nicht Text (vgl. GARZ & KRAIMER 1994) sondern Ton. In der überwiegenden Zahl der Fälle werden qualitative Daten mit einem Kassettenrekorder oder ähnlichem aufgenommen und dann in irgendeiner Weise weiter verarbeitet (natürlich sollen damit andere Quellen – vom Bild bis zur Videostudie – nicht gering geschätzt werden, sie werden jedoch vergleichsweise seltener ausgewertet). Die forschungsmethodische Literatur empfiehlt im Anschluss an die Erhebung nahezu unisono die Herstellung von Transkripten (vgl. z.B. BORTZ & DÖRING 2003; KOWAL & O'CONNELL 2003). An dieser Stelle soll nicht diskutiert werden, aus welchen – vermutlich großteils methodenhistorischen – Gründen dem Transkript eine so hohe Bedeutung beigemessen wird1); jedenfalls ist beobachtbar, dass – nicht zuletzt durch die Verwendung neuer Medien – die Möglichkeiten zunehmen, auf den Schritt der Transkription zu verzichten. Sind es zunächst vor allem solche Quellen, die besonders schwer und unter erheblichem Informationsverlust zu transkribieren sind (insbesondere Videoaufnahmen), so wird inzwischen vereinzelt darauf hingewiesen, dass auch rein auditives Material direkt entlang der Tonquelle ausgewertet werden könne (KUCKARTZ 2003, S.586). Das ist deshalb möglich, weil entsprechende Software viel leichter einen schnellen, nicht-sequenziellen Zugriff auf das Material erlaubt und so diejenigen Forschungsschritte vereinfacht, in denen Audioaufzeichnungen bislang gegenüber einem geschriebenen bzw. transkribierten Text wegen ihrer vergleichsweisen Umständlichkeit hoffnungslos unterlegen waren. Neuere Software zur qualitativen Sozialforschung erlaubt es, einen vollständigen Auswertungsprozess etwa in Form einer qualitativen Inhaltsanalyse (vgl. MAYRING 1999, S.91ff) rechnergestützt durchzuführen, Kategorien können dabei unmittelbar bestimmten Passagen im Audiodokument zugeordnet werden. [1]
Obwohl also computergespeicherte Audiodateien als Material für die qualitativen Auswertung bereits an Bedeutung gewinnen und in Zukunft sicher weiter gewinnen werden, steht ihrer Sekundäranalyse gegenwärtig ein gewichtiges Argument entgegen: Sie bieten einen sehr oft nicht ausreichenden Grad an Anonymität. So wäre etwa bei einer Interviewserie mit Studierenden eine Sekundäranalyse von Daten, die ein/e Kollege/in erhoben hat, bei Wahrung der Anonymität der Befragten kaum möglich – zu groß ist die Wahrscheinlichkeit, dass Personen, denen man auch in anderen Zusammenhängen begegnet, an ihrer Stimme erkannt werden. Der vorliegende Beitrag soll Möglichkeiten aufzeigen, um mit diesem Problem umzugehen. [2]
Eine Audiodatei, die einer Auswertung zugänglich gemacht werden soll, lässt sich akustisch verfremden. Der Effekt ist aus anonymisierten Interviews aus dem Fernsehen allgemein bekannt: Man hört eine Stimme einschließlich paraverbaler Signale, gleichzeitig klingt die Stimme aber künstlich und man kann sicher sein, dass der Sprecher oder die Sprecherin anhand der Aufzeichnung nicht leicht erkannt werden können. Für den Forschungsprozess stellt sich allerdings das Problem, dass eine derartige Verfremdung einen erheblichen technischen Aufwand und vor allem tontechnisches Know-how erfordern, und so die Möglichkeiten der Forschenden leicht übersteigt. Als Alternative bieten sich heutzutage Software-Lösungen zur Bearbeitung von Tondateien an, die ein zufrieden stellendes Ergebnis für die Anonymisierung von Audiodaten bieten, auch wenn dabei Qualitätseinbußen in Kauf genommen werden müssen, die die Auswertung erschweren (dazu im Folgenden mehr). Die hier vorgeschlagenen Varianten verwenden zur Anonymisierung einen Vocoder bzw. eine Tonhöhenveränderung (pitch shifting), jeweils auf Grundlage frei verfügbarer Software. Ein Vocoder bildet – vereinfacht gesprochen – ein gegebenes Tonsignal auf ein anderes Signal ab, sodass das Resultat eine komplexe Mischung der Eigenschaften beider Signale ist. Die Tonhöhenveränderung ähnelt im Ergebnis dem Klang einer zu schnell oder zu langsam drehenden Schallplatte, allerdings ohne die entsprechende Geschwindigkeitsveränderung. [3]
Den Ausgangspunkt der Bearbeitung stellt die Tondatei des Originaldokumentes dar. Es liegt in der Natur der Sache, dass bei der Anonymisierung Klanginformation verloren geht, mithin also die Verständlichkeit der Signale abnimmt. Deshalb ist unabhängig vom Verfahren zu wünschen, dass die Ausgangsqualität der Datei möglichst gut ist. Eventuell kann es beispielsweise sinnvoll sein, bei leisen Tonquellen zunächst die Grundlautstärke anzuheben, falls möglich auch mit Softwarewerkzeugen Störgeräusche zu entfernen usw. Die unten vorgestellte Software Audacity (http://www.audacity.de/) bietet beispielsweise die Möglichkeit, Hintergrundrauschen zu entfernen. Laute Störgeräusche (etwa ein Stoß gegen das Mikrofon) können mit diesem Programm auch direkt herausgeschnitten werden. Die Datei muss hierzu in einem computerlesbaren und -editierbaren Format vorliegen. WAV-Dateien und MP3-Dateien2) stellen in diesem Zusammenhang kein Problem dar, andere Formate müssen ggf. konvertiert werden. Liegt eine solche Datei vor, kann mit der eigentlichen Bearbeitung begonnen werden. [4]
3.1 Vorbereitung: Entfernen persönlicher Informationen
Zunächst müssen – wie bei einem schriftlichen Transkript – alle persönlichen Daten entfernt werden, die Rückschlüsse auf die interviewte Person zulassen oder die Anonymität anderer genannter Personen, Einrichtungen etc. beeinträchtigen. Auch hierfür lässt sich die Software Audacity verwenden (siehe auch Abschnitt 3.3). In der ursprünglichen Audiodatei können einzelne Bereiche markiert und gelöscht oder verändert werden. Die hohe Auflösung der Wellenform der Datei am Bildschirm erlaubt dabei ohne weiteres, auch Wörter oder Teile von Wörtern zu bearbeiten. Im einfachsten Fall ersetzt man Wörter durch Stille, indem man den entsprechenden Abschnitt der Datei mit dem Cursor markiert und dann im Menü "Bearbeiten" die Funktion Stille wählt. Möchte man die Löschung akustisch kenntlich machen, so ist es sinnvoller, einen Ton von der Dauer der zu löschenden Stelle einzusetzen (Menü "Generieren" – "Ton") und dann die entsprechende Passage zu markieren und zu entfernen. [5]
Diese Verfahrensweise ist vergleichsweise einfach, birgt jedoch den Nachteil, dass damit Informationen verloren gehen (können), die für die Sekundäranalyse von großer Bedeutung sein können. Deshalb ist als Alternative eine "faktische Anonymisierung" in Betracht zu ziehen, bei der die Passagen, die unmittelbar Rückschlüsse auf die Interviewten (oder etwa die Einrichtungen, denen sie angehören) zulassen, nicht gelöscht, sondern ersetzt werden. Dieses Verfahren ist ein wenig aufwändiger; prinzipiell ist die Vorgehensweise die gleiche wie bei einem schriftlichen Transkript, d.h. alle relevanten Passagen (etwa "Firma Schmidt") werden durch einen Alternativtext (etwa "Unternehmen der Bekleidungsbranche") ersetzt. Im Unterschied zum schriftlichen Dokument muss hierzu jedoch der jeweilige Text zunächst aufgenommen werden. Diese Aufnahme kann direkt aus Audacity heraus erfolgen, wenn der Rechner mit einem Mikrofon ausgestattet ist. Hierzu klickt man auf den roten "Aufnahmeknopf" im oberen Bereich des Fensters und beendet die Aufnahme mit dem viereckigen "Stopp-Knopf".3) Die neu gesprochenen Teile werden nun an die Stelle der zu tilgenden Äußerungen in das Originaldokument eingefügt. Falls die Aufnahmen nicht mit Audacity gemacht wurden, wird nun zunächst das Originaldokument geöffnet. Dann werden ein oder mehrere Tondateien mit den Ersatzpassagen importiert. Nun können die jeweiligen Stellen im Originaldokument markiert und gelöscht werden (Menü "Bearbeiten – Schnitt") und aus dem neuen Dokument entsprechende Bereiche kopiert (Menü "Bearbeiten – Kopieren") und eingefügt ("Bearbeiten – einfügen") werden. Zum Auffinden der jeweiligen Stellen ist es hilfreich, auf die Zeitleiste am oberen Fensterrand zu achten und durch den Knopf "solo" links neben den Tonspuren jeweils nur die Spur hörbar zu machen, mit der man arbeiten möchte. [6]
3.2 Variante 1: Verfremdung mit Vocodersoftware
Für die hier beschriebene Aufgabe gibt es mehrere frei verfügbare Softwarewerkzeuge; eines der bekannteren Programme ist der Zerius Vocoder (http://www.zerius.com/), der dieser Beschreibung zugrunde liegt.
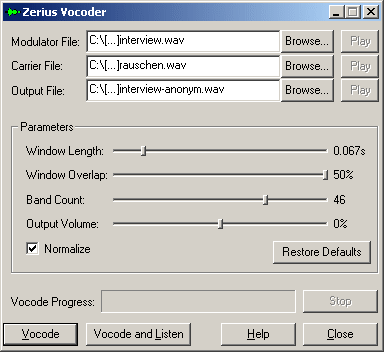
Abbildung 1: Bedienfenster des Zerius Vocoder [7]
Die Bedienung ist denkbar einfach: Das eigentliche Tondokument wird als "Modulator File" eingetragen. Als "Carrier File", also Trägersignal, wird für den vorliegenden Zweck ein Rauschsignal verwendet (üblicherweise verwendet man "weißes Rauschen", also ein Signal, dass theoretisch aus allen Frequenzen des hörbaren Spektrums gleichmäßig zusammengesetzt ist). Dem Programm liegt eine Datei mit weißem Rauschen namens "white.wav" bei. Nun kann ein Dateiname für das verfremdete Ergebnis angegeben werden ("Output File") und durch Klicken auf den Knopf "Vocode" beginnt die Verfremdung. Das Ergebnis ist eine Audiodatei, in der die Stimmmodulation der Sprechenden auf das Rauschsignal übertragen wird, sodass ein Wiedererkennen der Stimme nicht mehr möglich ist (auch das Geschlecht des Sprechenden lässt sich in der verfremdeten Version kaum identifizieren)4). Die weiteren Bedienelemente funktionieren in der Regel mit den Voreinstellungen gut. Wenn es Probleme mit der Verständlichkeit des Ergebnisses gibt, kann es sinnvoll sein, mit der "window length" (die Dauer der Abschnitte, die einzeln vom Programm bearbeitet werden) zu experimentieren. [8]
Das schwerwiegendste Problem bei der beschriebenen Vorgehensweise ist zweifellos die Qualität des verfremdeten Signals. Liegt eine sorgfältig aufgenommene Ausgangsquelle vor, so ist die verfremdete Quelle zwar etwas schwerer zu verstehen, bietet aber immer noch alle Möglichkeiten der Weiterverarbeitung. Zögern bzw. Sprechpausen bleiben unverändert bestehen, Betonungen und nonverbale Laute sind ebenfalls kenntlich, wenn auch mitunter mit geringer Klarheit als in einer unveränderten Datei. Ist hingegen das Ausgangssignal schon von minderer Qualität, so kann es sein, dass das Resultat nicht mehr in allen Teilen verständlich und damit auch nicht mehr auswertbar ist. [9]
Weiterhin tritt bei der Funktionsweise eines Vocoders das Rauschen gewissermaßen an die Stelle der Stimme des Sprechers. Dadurch ist die Zuordnung von Äußerungen anhand von Stimmen nicht möglich. Im Falle eines Interviews mit einer Person ist eine Stereoaufnahme von Vorteil. Hier können beide Spuren getrennt werden, dann werden sie entweder mit unterschiedlichen Parametern verfremdet oder – falls der/die Interviewte auf der Sprecher/innenspur gar nicht zu hören ist – kann diese auch im Originalton erhalten werden. Das Trennen und Zusammenführen der Spuren kann wiederum mit Audacity vollzogen werden. (Der Zerius Vocoder selbst bietet leider nicht die Möglichkeit einer unterschiedlichen Veränderung des linken und rechten Kanals einer Stereoaufnahme.) [10]
3.3 Variante 2: Verfremdung durch Tonhöhenveränderung (pitch shifting)
Bei der Tonhöhenveränderung wird das gesamte Frequenzspektrum der Originalquelle angehoben oder abgesenkt – Stimmen sind also in der veränderten Tondatei höher oder niedriger als im Original. Der Tonhöhenabstand zwischen verschiedenen Stimmen und weitere Charakteristika bleiben aber – im Gegensatz zum Vocoder – insgesamt in höherem Umfang erhalten. Auch für die Tonhöhenveränderung gibt es frei verfügbare Software; die folgenden Angaben beziehen sich auf das bereits erwähnte Programm Audacity.
Abbildung 2: Hauptbildschirm von Audacity [11]
Auch hier ist die Bedienung recht einfach. Zunächst wird die Audioquelle geöffnet (Audacity verarbeitet mehrere Audioformate, u.a. WAV und MP3). Die Funktion "Tonhöhe (pitch) ändern" befindet sich im Menü "Effekte". Hier wird nun das Intervall eingestellt, um das die Tonhöhe verändert wird. Allgemein gültige Angaben lassen sich an dieser Stelle schwer machen, weil die Qualität des Ergebnisses hinsichtlich der Anonymisierung und Verständlichkeit stark von der Tonquelle abhängt. Eine starke Verfremdung bei guter Verständlichkeit erreicht man im Allgemeinen, wenn man die Tonhöhe zur Mitte hin verändert, also tiefe Stimmen erhöht und hohe absenkt. Oft lassen sich mit einer Veränderung um 3-5 Halbtonschritte gute Ergebnisse erzielen. Sind die aufgenommenen Stimmen in der Tonhöhe sehr unterschiedlich, so ist immer ein Kompromiss notwendig; im Zweifelsfall ist hier natürlich wichtiger, dass die Stimme des Interviewten hinreichend verfremdet ist. [12]
Audacity bietet eine Vielzahl weiterer Funktionen, die für die Vorbereitung von Audiodaten zur (Sekundär-)Analyse hilfreich sein können. Einige wurden bereits angesprochen (vgl. Abschnitt 3.1). Statt in diesem Artikel diese Funktionen im einzelnen zu beschreiben, sollen einige knappe Hinweise genügen: Zentral für die Arbeit mit dem Programm ist das Konzept des Markierens von Audioabschnitten mit der Maus. Damit der entsprechende Abschnitt markiert werden kann, auf den beispielsweise eine Veränderung angewandt wird, sollte er vollständig im Bildschirm zu sehen sein, hierzu dienen die Lupensymbole oben rechts, mit denen der angezeigte Ausschnitt verlängert oder (zur genaueren Auswahl) verkürzt werden kann. Soll die gesamte Tondatei verändert werden, kann diese mit der Tastenkombination "Strg-a" vollständig markiert werden. [13]
Das Resultat einer Veränderung lässt sich mit dem Knopf "Probehören" vor der Anwendung eines Effektes überprüfen. Veränderungen können aber – wie in anderen Programmen auch – auch nachträglich rückgängig gemacht werden (Menü "Bearbeiten"-"Rückgängig"). Sollen mehrere Spuren gleichzeitig bearbeitet werden (z.B. Teile aus einer Spur in eine andere eingefügt werden), so wird jede einzelne Spur importiert (Menü "Projekt" – "Audio importieren"). Gespeichert werden kann das Ergebnis, indem die entsprechende Spur komplett markiert ("Strg-a") und dann exportiert wird (Menü "Datei" – "Exportieren als WAV"). [14]
Die Anonymisierung mittels Tonhöhenveränderung ist "schwächer", weil mehr Charakteristika der Stimme erhalten bleiben; gleichzeitig erleichtert das allerdings die weitere Verwendung der Daten. Eine qualitativ schlechte Tondatei, aus der mittels Vocoder kaum noch verständliche Sprache zu gewinnen ist, ist nach einer Tonhöhenveränderung oft noch ohne weiteres benutzbar. Hier eine Entscheidung zu treffen, hängt letztlich von den Anforderungen an die Anonymisierung selbst ab. [15]
Ein Problem bei der Tonhöhenveränderungen können sehr unterschiedlich hohe Stimmen darstellen. Hilfreich ist auch in solchen Fällen eine Stereoaufnahme, bei der die Stimmen in unterschiedlichen Richtungen verändert werden. Überdies besteht prinzipiell die Möglichkeit, nur die Bereiche zu verändern, in denen der oder die Interviewte/n sprechen und die Stimme der Interviewenden unverändert zu lassen; das bedeutet freilich einen höheren Aufwand bei Bearbeitung der Originalquelle. [16]
4. Wie weit reicht die Anonymisierung?
Für die qualitative Sozialforschung existieren heutzutage ethische Standards, im Rahmen derer etwa die Anonymisierung von Daten völlig selbstverständlich ist. "Die Anonymität der befragten oder untersuchten Personen ist zu wahren" (Ethik-Kodex, B5), stellt etwa der Ethik-Kodex der deutschen Gesellschaft für Soziologie und des Berufsverbandes deutscher Soziologen fest. Was bei großen, überregionalen und womöglich quantitativ angelegten Studien aber leicht zu erfüllen scheint, kann sich bei kleinen, regionalen Erhebungen mit umfangreichen Daten pro Fall und einem qualitativen Zugang als problematisch erweisen (vgl. HOPF 2003). Dieses Problem stellt sich prinzipiell bei jeder Sekundärauswertung; so wäre etwa bei narrativen Interviews mit erheblichem biografischen Anteil das Tilgen von Namen und sonstigen unmittelbaren persönlichen Bezügen aus einem Transkript (oder aus einer Tonquelle) kaum ausreichend, um Anonymität zu gewährleisten, wenn nicht sicher ist, dass Interviewte und Auswertende einander nicht kennen. Gleichzeitig ist aber jeder Schritt der Anonymisierung mit einem Informationsverlust verbunden, der die Qualität der Daten beeinträchtigt. Die Forschenden befinden sich also in dem Dilemma, die Informationen so aufzubereiten, dass einerseits nicht auf die befragten Personen rückgeschlossen werden kann, andererseits aber der Informationsgehalt möglichst groß gehalten wird. Dieses Problem stellt sich bei schriftlichen (oder auch visuellen) Quellen ebenso wie bei Audioaufzeichnungen. [17]
Damit ist ein Grundproblem der Anonymisierung qualitativer Daten skizziert, dass hier zum Abschluss angesprochen werden soll. Bezogen auf Audioquellen verlangt ein ethisch verantwortbarer Umgang mit den Daten,
dass die untersuchten Personen wissen, dass ihre Daten unter Beachtung bestimmter Rahmenregelungen auch anderen als den interviewenden Personen zugänglich gemacht werden können (sei es als Tonquelle oder als Transkript) – die Einwilligung hierzu kann möglicherweise auch nachträglich eingeholt werden;
dass eine wirkungsvolle Anonymisierung erreicht wird; was unter wirkungsvoll zu verstehen ist, hängt wesentlich davon ab, wer das Material einer Sekundäranalyse unterziehen möchte. Handelt es sich um eine Person, die mit den Interviewten näher bekannt ist, so sind entsprechend sehr hohe Anforderungen an die technische Anonymisierung zu stellen (im hier beschriebenen Konzept würde die Anonymisierung durch Tonhöhenveränderung im Regelfall ausscheiden). Mitunter kann sich in diesem Fall aber auch eine Sekundäranalyse gänzlich verbieten – wie auch eine Auswertung schriftlicher qualitativer Daten unzulässig ist, wenn die Anonymität der Interviewten aufgrund einer zu großen Nähe zu der auswertenden Person nicht sicher gestellt werden kann. [18]
Damit ergibt sich auch für den Anspruch an die technische Seite der Anonymisierung eine Grauzone, die nur der oder die Forschende selbst verantwortungsvoll klären kann. Sollen Daten etwa einer den Untersuchten sicher fremden Person zur Verfügung gestellt werden, so wird in den meisten Fällen eine Tonhöhenveränderung ausreichende Anonymität gewährleisten – selbst wenn Auswertende und Interviewte sich später träfen, wäre ein Wiedererkennen auszuschließen, solange die Stimme und Artikulation der Interviewperson nicht sehr ungewöhnliche Merkmale aufweisen. Besteht hingegen die Möglichkeit, dass Auswertende und Interviewte einander (zumindest flüchtig) kennen, so ist ein höherer Grad an Anonymisierung – etwa durch den Einsatz des Vocoders wünschenswert, auch wenn hierbei die Textverständlichkeit unter Umständen stark leidet. [19]
Die Anonymisierung qualitativer Daten ist also ein Problem, dass letzten Endes nicht nur von technischen Möglichkeiten, sondern viel mehr von verantwortlichen Entscheidungen der Forschenden abhängt. Dies betrifft allerdings – wie angesprochen – den Umgang mit qualitativen Quellen jeder Art, also etwa auch Transkripte. Technische Mittel wie die hier beschriebenen erlauben es, Audiodaten in einem Umfang zu anonymisieren, der im Zweifelsfall kaum mehr Rückschlüsse auf die Interviewten zulässt als eine sorgfältig verschriftlichte und anonymisierte Quelle. Insofern bieten sie auch ohne den Aufwand der Herstellung von Transkripten sehr weitgehende Möglichkeiten der Sekundäranalyse. [20]
Im Folgenden ein Überblick über die Funktionen der im Text erwähnten Software:
Audacity: Audiobearbeitungsprogramm, dass sich im Rahmen der hier vorgestellten Anwendung für folgende Aufgaben eignet: Einlesen der Audiodaten in verschiedenen Formaten (ggf. Konvertierung); Tonhöhenveränderung (pitch shift); Entfernen/Verändern einzelner Abschnitte innerhalb der Tondatei. Quelle: http://www.audacity.de/
Zerius Vocoder: Verfremden einer Aufnahme nach der Funktionsweise eines Vocoders. Quelle: http://www.zerius.com/ [21]
1) So weist etwa KUCKARTZ darauf hin, dass prinzipiell eine "Auswertung nur auf Basis der Tonaufzeichnung" (2003, S. 586) möglich sei, schränkt jedoch ein, dass dies in der Forschungspraxis noch eine große Ausnahme sei – ohne jedoch Gründe hierfür anzugeben. <zurück>
2) Digitalisierte Tonaufnahmen liegen sehr häufig in einem dieser beiden Formate vor. WAV entspricht der Speicherung von Audiodaten auf CD, MP3 ist ein komprimiertes Format, bei dem die Daten bei nahezu gleichbleibender Qualität wesentlich weniger Speicherplatz benötigen. Eventuell liegen Daten aber auch in anderen Formaten vor, etwa wenn sie mit speziellen digitalen Aufnahmegeräten erhoben wurden. Dann ist die Umwandlung in WAV oder MP3 in der Regel mit Software möglich, die zum Lieferumfang des Aufnahmegerätes gehört, mitunter aber auch direkt vom Hersteller zu bekommen ist. <zurück>
3) Die Aufnahmen können auch mit anderen Geräten gemacht werden (z.B. mit einem MP3-Spieler mit Diktiergerätfunktion). Dann muss allerdings darauf geachtet werden, dass beide Dokumente die gleiche Samplingrate (etwa: Auflösung/Geschwindigkeit) aufweisen, damit Daten aus der Ersetzungsdatei in die Originaldatei eingefügt werden können, ohne dass sich dabei Geschwindigkeit und Tonhöhe verändern. <zurück>
4) Die Stimme des Sprechenden wird bei diesem Verfahren tatsächlich völlig unkenntlich – das bedeutet jedoch nicht, dass ein Wiedererkennen nicht möglich wäre; es erfolgt dann allerdings nicht anhand der Stimme, sondern durch andere sprachliche Besonderheiten von Betonungen über Sprechpausen bis zu einer charakteristischen Wortwahl (siehe auch Abschnitt 4). <zurück>
Bortz, Jürgen & Döring, Nicola (2003). Forschungsmethoden und Evaluation für Human- und Sozialwissenschaftler. Berlin: Springer.
Ethik-Kodex (1992). Ethik-Kodex der Deutschen Gesellschaft für Soziologie und des Berufsverbandes Deutscher Soziologen, http://www.bds-soz.de/Ethik.pdf [17.12.2004].
Garz, Detlef & Kraimer, Klaus (1994). Die Welt als Text. Frankfurt/M.: Suhrkamp.
Hopf, Christel (2003). Forschungsethik und qualitative Forschung. In Uwe Flick, Ernst von Kardorff & Steinke, Ines (Hrsg.), Qualitative Forschung (S.588-600). Reinbek: Rowohlt.
Kowal, Sabine & O'Connell, Daniel (2003). Zur Transkription von Gesprächen. In Uwe Flick, Ernst von Kardorff & Ines Steinke (Hrsg.), Qualitative Forschung. Ein Handbuch (S.437-447). Reinbek: Rowohlt.
Kuckartz, Udo (2003). Qualitative Daten computergestützt auswerten: Methoden, Techniken, Software. In Barbara Friebertshäuser & Annedore Prengel (Hrsg.), Handbuch Qualitative Forschungsmethoden in der Erziehungswissenschaft (S.584-595). Weinheim: Juventa.
Mayring, Philipp (1999). Einführung in die qualitative Sozialforschung. Weinheim: Beltz.
Dr. Henning PÄTZOLD, Juniorprofessor für Erwachsenenbildung. Arbeitsschwerpunkte: Didaktik der Erwachsenenbildung, Pädagogische Beratung, Medienpädagogik, Lehrerbildung.
Kontakt:
Dr. Henning Pätzold
TU Kaiserslautern
FG Pädagogik
Postfach 3049
D-67653 Kaiserslautern
E-Mail: paetzold@rhrk.uni-kl.de
URL: http://www.uni-kl.de/paedagogik/
Pätzold, Henning (2005). Sekundäranalyse von Audiodaten. Technische Verfahren zur faktischen Anonymisierung und Verfremdung [21 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 24, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501249.
Revised 6/2008

Creative Commons Attribution 4.0 International License