Volume 6, No. 1, Art. 33 – Januar 2005
Das "C-TOC" zur Gliederung von Audiodaten. Ein Beispiel für die qualitative Analyse am Rohmaterial
Stefan Hauptmann
Zusammenfassung: Durch die gegenwärtig verfügbare Technologie wird es der qualitativen Sozialforschung erstmals ermöglicht, Daten ohne den Zwischenschritt über Transkriptionen bzw. Verschriftlichung von Beobachtungsnotizen vollständig analysieren zu können. Zu diesem Zweck wird üblicherweise eine Software für Qualitative Datenanalyse (QDA) eingesetzt. Dieser Beitrag zeigt, wie mit der Analysesoftware Atlas.ti aus digitalisiertem Rohmaterial in Form von Audiodaten ein Klickbares Inhaltsverzeichnis (C-TOC) erstellt wird, das einerseits einen Überblick liefert mit der Option, mittels Mausklick sofort auf Passagen des Materials zugreifen zu können, dessen Elemente sich andererseits als Basis für alle zukünftigen Analyseschritte innerhalb von Atlas.ti verwendet lassen. Für viele Themen innerhalb der qualitativen Sozialforschung kann ein derartiges "Herunterbrechen" des Rohmaterials auf ein handhabbares Format die Transkription ersetzen. Die Vorteile sind: Die Rohdaten sind immer bei der Hand (als mp3-Dateien auf dem PC oder Laptop bzw. auf CD-ROM oder gar einem PDA); die Analyse erfolgt an den Rohdaten selbst; diese sind vorstrukturiert und die Struktur bietet im Gegensatz zur Transkription einen schnellen Überblick über die Daten; mittels einfacher Navigation sind einzelne Elemente des Datenstroms schnell zugänglich; zu Zwecken der Sekundäranalyse kann auf ein solches Inhaltsverzeichnis – und somit auf die Daten selbst – jederzeit zurückgegriffen werden; der Verzicht auf Transkriptionen spart Kosten.
Keywords: Audiodaten, QDA-Software, Atlas.ti, Interviews, Effizienz, Forschungsmethode, Sekundäranalyse, Transkription, C-TOC, Sekundäranalyse
Inhaltsverzeichnis
1. Einleitung
2. Der Einsatz von digitalisierten Audiodaten
3. Die Generierung eines C-TOC
3.1 Die Vorbereitung des Datenmaterials
3.2 Das Segmentieren eines Interviews
3.3 Der Übertrag in Atlas.ti
3.4 Exkurs: Arbeiten mit mp3cutter und Winamp als Alternative
3.5 Arbeiten mit C-TOC Elementen
4. Fazit
Bislang gilt in den überwiegenden Fällen noch die Transkription, also die Verschriftlichung von Kommunikation, als das Medium, durch welches sich der qualitative Sozialforscher dem zu untersuchenden Phänomen nähert. Angesichts aktuell zur Verfügung stehender EDV-Technologien stellt sich allerdings die Frage, ob es nicht auch alternative Lösungen gibt. Denn das Analysieren von transkribierten Daten ist im Grunde nur die Lösung Zweiter Wahl und hat sich nur deshalb als Standardverfahren etabliert, weil es in der Vergangenheit aus technischen Gründen keine anderen Möglichkeiten gab. Der Prozess des Transkribierens ist ein Zwischenschritt, welcher, so die Argumentation in diesem Beitrag, mittels gegenwärtig zur Verfügung stehender Technik in vielen Feldern der qualitativen Sozialforschung vermieden werden kann. [1]
Da sowohl Audio als auch Videodaten zunehmend in digitalisierter Form aufgezeichnet werden, ist mit ihnen ein gänzlich anderer Umgang möglich, wie dies noch für die analogen Formate, also für Tonband- und Videokassetten, galt. Die Vervielfältigung und Lagerung der Daten wird erheblich vereinfacht, der Zugriff auf Datensätze und einzelne Passagen darin ist in Sekundenschnelle möglich und mittels Qualitativer Datenanalyse (QDA) Software kann die gesamte Analyse am Audio- bzw. Videomaterial, also an den Rohdaten selbst, erfolgen. [2]
Zur Analyse solcher Rohdaten ist es notwendig, die digitalisierten Datensätze, in diesem Beitrag an Interviews in Form von Audiodateien (im mp3-Format) exemplifiziert, in kleinere analytische Einheiten aufzuteilen. Dies soll ein Inhaltsverzeichnis leisten, das jeweils von einem Interview erstellt wird. Ein solches "Clickable Table of Content" (folgend C-TOC genannt) hat einerseits die Funktion, einen Überblick über den Inhalt des vorliegenden Interviews zu leisten und mittels Mausklick direkt eine gewünschte Passage abspielen zu können. Andererseits sollen die Elemente des C-TOC als Grundlage für jede weitere Analyse innerhalb von QDA Software Paketen dienen. Hierzu werden die "Kapitel", welche im weitesten Sinne vergleichbar sein dürften mit "Bedeutungseinheit[en]" nach TESCH (1992, S.46, zitiert nach KÜHN & WITZEL 2000, [14]), als elementare, nicht weiter aufteilbare Einheiten begriffen. Während der eigentlichen Analyse dienen diese Bedeutungseinheiten als Quelle für Kodierungen und Verweise einerseits, und, wie auch in der Übersichtsfunktion eines C-TOC, zum Zwecke des schnellen Zugriffs ("retrieval") auf die Daten andererseits. [3]
Ihren elementaren Charakter erlangen die Bedeutungseinheiten nur dann, wenn sie eine entsprechende Sequenzlänge nicht überschreiten. Wie lang eine solche Sequenz zu sein hat, muss im jeweiligen Fall entschieden werden.1) Überdies ist die gesamte Prozedur der Erstellung eines C-TOC eine Interpretation der Struktur des vorliegenden Materials. Welchen Maßgaben dieser Prozess zu folgen hat – also ob die Erstellung eines C-TOC entlang vorhandener Kategorien zu geschehen hat oder eher offen, welche Ebene des Materials sie tangieren soll2) usw. – muss sich am Zweck der Nutzung der jeweiligen Daten orientieren. [4]
Im Rahmen einer Archivierung von Audio- und Videomaterial liefern C-TOCs also einen Überblick über den Inhalt vorhandener Datensätze mit der Option, direkt auf Passagen des Rohmaterials zugreifen zu können. Darüber hinaus macht es die Nutzung der elementaren Bestandteile eines C-TOC – der Bedeutungseinheiten – möglich, die Datenanalyse ohne den bislang notwendigen Zwischenschritt der Transkription durchzuführen. In diesem Beitrag wird die Erstellung eines C-TOC detailliert dargestellt, einmal mit Atlas.ti, Version 4.2, einmal mit der Anwendung von zwei frei erhältlichen Software Programmen, wodurch jedoch lediglich die Überblicksfunktion eines C-TOC genutzt werden kann. [5]
2. Der Einsatz von digitalisierten Audiodaten
Ein einziges transkribiertes Interview enthält etwa 50 bis 100 Seiten Text. Aufgrund dieser Datenbasis existiert noch keinerlei Ordnung im Material. Bevor ein Interview durchgelesen und mittels Notizen etc. strukturiert wurde, ist es ebenso ungeordnet wie die Audio-Aufzeichnung selbst. Hinzu kommt, dass die Transkription schon eine analytische Reduktion und erste Interpretation darstellt.3) Die Rohdaten in Form der Audio-Aufzeichnung sind nach der Transkription nicht oder nur mit großem Aufwand zugänglich, etwa wenn sie auf Minidisks oder gar auf Audio-Kassetten aufgezeichnet wurden. [6]
Der Zugriff auf authentisches Material ist demzufolge nur gewährleistet, wenn das digitalisierte Rohmaterial als Grundlage für den Auswertungsprozess im Forschungszusammenhang genutzt wird. Durch den Einsatz von QDA-Software ist dies möglich. Weitere Vorteile sind mit der Nutzung von digitalisierten Audio- und Videodaten verbunden. Die Rohdaten – dies ist auch für die Archivierung der Daten für eine spätere Sekundärnutzung interessant – können eventuell zusammen mit den Analysedaten auf einem Computer bzw. Server Platz sparend und leicht zugänglich gelagert werden. Sowohl im Prozess der Primär- als auch Sekundärforschung können die Mitglieder der jeweiligen Forschungsgruppen jederzeit und über räumliche Distanzen hinweg auf die digitalen Daten zugreifen. [7]
Eine Audiodatei, etwa von einem Interview, kann im digitalen Format mp3 auf nahezu jedem Computer und auch auf vielen PDAs oder gar Mobiltelefonen und natürlich auf den gegenwärtig populären mp3-Playern abgespielt werden. Dieses Format erlaubt es, die Größe einer Datei auf wenige Megabyte zusammenschrumpfen zu lassen. Auf einer einzigen CD-Rom finden bei entsprechender Komprimierung bis zu 100 Stunden Audiomaterial Platz. Das reicht aus, um Interviews eines ganzen Forscherlebens aufzuzeichnen. Diese Dateien können mit vielerlei unterschiedlicher Software angesteuert werden, so auch mit dem Audioplayer, der in aktuellen Microsoft-Windows Versionen installiert ist. Es kann auch entsprechend leicht darin navigiert werden, indem mit der Maus in die Zeitleiste geklickt wird. Dieser Vorgang ist bei allen verfügbaren Playern ähnlich. [8]
Allerdings ist auf diese Weise noch kein Retrieval im Rahmen einer qualitativen Analyse möglich. Hierzu dient die besagte QDA-Software. Atlas.ti ist in der Lage, neben Texten und Bildern auch Audio- und Videoformate handhaben zu können, so also auch das mp3-Format. Die Erstellung eines (Mouse-) Clickable Table of Contents (im Folgenden C-TOC genannt) ist ein Beispiel, wie diese Software genutzt werden kann, um das Rohmaterial zu strukturieren. Hierbei wird das gesamte Interview – es kann sich auch um anderes Audiomaterial handeln – in Sinnsegmente bzw. aufeinander folgende Bedeutungseinheiten unterteilt. Wie man es von einem Inhaltsverzeichnis eines Buches kennt, werden auf diese Weise die einzelnen Passagen gekennzeichnet und in einer Übersicht dargestellt. [9]
Darüber hinaus können die Sinnsegmente als Grundlage für alle weiteren Analysen dienen. Innerhalb von Atlas.ti beispielsweise können sie ebenso behandelt werden wie Absätze oder gar einzelne Sätze in Transkriptionen. Sie lassen sich also wie Textbausteine mit den in Atlas.ti verfügbaren Kodierungs- und Verknüpfungsmethoden bearbeiten. In einem Projekt können auf diese Weise verschiedene Datenquellen miteinander in Relation gebracht werden: eigene Notizen, Auszüge aus Zeitungen, Auszüge aus Interviews (nicht transkribiert, sondern in ihrer ursprünglichen Form als Audiodaten) usw. [10]
Da die Generierung eines C-TOC eine besondere Form der Kodierung ist, unterscheidet es sich je nach Vorwissen des Analysierenden bzw. je nach Forschungsinteresse, in dessen Rahmen es erstellt wird.4) Dies scheint auf den ersten Blick problematisch zu sein, ist es jedoch nur bedingt. Schon die Bezeichnung der Segmente birgt eine Art Wiedererkennungswert in sich, so dass durch wiederholtes Arbeiten mit dem Material ein Kontextwissen entsteht und schon hierdurch die ursprüngliche Komplexität des Materials reduziert wird. Dies eröffnet die Möglichkeit, solche Aufgaben fremd zu vergeben. Wie auch Transkriptionsarbeiten oftmals nicht vom Forscher übernommen werden, muss er solche C-TOCs ebenfalls nicht selbst erstellen. Er kann das C-TOC als erste Annäherung an das Material verwenden und in der eigenen Analyse darauf aufbauen. Ihm gehen dabei keine Daten verloren, wie es etwa bei einer Transkription häufig geschieht. [11]
3. Die Generierung eines C-TOC
3.1 Die Vorbereitung des Datenmaterials
Es ist anzunehmen, dass, wie im Konsumerbereich schon heute, so auch in der qualitativen Sozialforschung digitalisierte Daten die Erste Wahl sein werden. Formate wie das mp3-Format (ausführlich: MPEG 1 Layer 3), das am Fraunhofer Institut entwickelt wurde, würden dabei eine große Rolle spielen. Es handelt sich hierbei um ein Kompressionsverfahren, das Audiodateien auf einen Bruchteil ihrer ursprünglichen Größe reduziert. Dadurch wird der Umgang mit ihnen erheblich erleichtert. Es können viele Daten auf vergleichsweise kleinem Raum gespeichert werden. Bei guter Sprachqualität der Originalaufnahme kann eine Kompressionsrate so gewählt werden, dass die Größe der Datei nicht mehr als 14 Megabyte/Stunde betragen muss (STOCKDALE 2003, S.11). Dies erlaubt auch einen einfachen Transfer der Daten im Internet, mit Flashspeichern (USB-Sticks) oder mittels gebrannter CD-ROMs. Zwar gibt es mittlerweile bereits fortgeschrittene Kompressionsverfahren, die bei gleich bleibender Qualität noch kleinere Dateien produzieren können. Allerdings ist das mp3-Format nach wie vor am Weitesten verbreitet. Es empfiehlt sich also, einstweilen bei diesem Format zu bleiben. Dieses wird auch von der QDA Software Atlas.ti unterstützt. [12]
Auch solche Audiodaten, die auf Minidisks oder Kassetten aufgenommen worden sind, lassen sich mit vertretbarem Aufwand in mp3-Dateien umwandeln. Dazu wird eine Recoder-Software benötigt, welche das analoge Signal in ein digitales, eben in eine mp3-Datei umwandelt (encodiert). (Für einen Überblick über dazu verwendbare Software und eine Anleitung zur Aufnahme, siehe STOCKDALE 2003.) Die Daten auf Minidisks sind zwar schon digitalisiert, das Signal muss allerdings analog auf den Rechner überspielt werden. Dazu wird der Audioausgang vom Minidisk-Recorder wie auch vom Kassettenrecorder mit dem Eingang der Soundkarte am Computer verbunden. Die Recorder-Software zeichnet das Signal in Echtzeit auf und encodiert es sogleich in das mp3-Format. [13]
Es gibt mittlerweile viele Geräte, mit denen direkt auf mp3 aufgezeichnet werden kann. Zwar sind diese oftmals noch nicht recht ausgereift in ihrer Bedienung und der Qualität des Mikrofons, wie dies etwa für die in der Sozialforschung beliebten Minidisk-Player gilt. Es handelt sich zumeist um Konsumergeräte, so genannte mp3-Player, von denen nahezu täglich neue Modelle zu erschwinglichen Preisen auf den Markt kommen. In naher Zukunft dürften hier jedoch interessante Entwicklungen für professionelle Aufnahmen zu erwarten sein. Einige bereits verfügbare Profi-Modelle stellt STOCKDALE (2003) ebenfalls kurz vor. Mit solchen Geräten können die Audiodaten in Sekundenschnelle auf den Rechner übertragen werden. [14]
3.2 Das Segmentieren eines Interviews
Wenn die Audiodaten in das Format mp3 gebracht worden sind, können sie in Atlas.ti importiert werden. Allerdings empfiehlt es sich, die Segmentierung des Materials nicht sofort in der QDA-Software vorzunehmen, sondern die Struktur des Interviews zunächst auf einem Blatt Papier herauszuarbeiten. Zu diesem Zweck kann die Datei sowohl in Atlas.ti als auch mit alternativer mp3-Player-Software angespielt werden. Wichtig ist dabei nur, die jeweiligen Zeitpunkte von markanten Stellen festzuhalten. Ich selbst habe mir dazu jeweils das gesamte Interview ohne große Unterbrechungen angehört und währenddessen auf einem Blatt Papier die Gliederung vorgezeichnet: markante Wechsel von Themen oder Erzählstrukturen gekennzeichnet anhand des Zeitzählers in Atlas.ti (oder mit Winamp etc.) und eine erste ad hoc Bezeichnung verliehen für die jeweilige Sequenz (auf dem Blatt Papier mit Zeitangabe); im Laufe des Interviews bereits differenzierte Sequenzen zusammengefasst zu einem größeren Themenblock, der später die Erste Ebene oder, falls noch ein größerer zusammenhängender Themenblock ersichtlich wird, die Zweite Ebene bilden wird, wie dies in Form von Kapitelebenen in Büchern und Aufsätzen der Fall ist. Die Laufzeiten sollten hierzu schon recht genau auf Papier festgehalten werden. So erspart man sich weitere Suchprozesse bei der Eingabe dieser Merkmale in Atlas.ti. [15]
Mit etwas Übung kann auf diese Weise in lediglich zwei Durchläufen das gesamte Interview strukturiert werden – im ersten Durchlauf auf Papier, im zweiten durch die Eingabe dieser Daten in Atlas.ti. Je nach Anforderung an Genauigkeit und Länge der Sequenzen, nach der Verständnisschwierigkeit des Interviewmaterials selbst etc. ist die Erstellung eines C-TOC in der drei- bis vierfachen Zeit der Laufzeit eines Tondokuments möglich – gegenüber einer Transkription ein bedeutender zeitlicher Fortschritt. [16]
Diese Prozedur beruht auf einem vielfach höheren Maß an Interpretation als eine Transkription. Und dennoch sind die Konsequenzen einer Fehlinterpretation weniger negativ zu beurteilen als bei einer Transkription. Letztere stellt in ihrer Form das alleinige Datenmaterial dar, an dem der Sozialforscher sich orientiert. Falls hier also Fehler geschehen, sind diese kaum noch rückgängig zu machen. Mittlerweile können mit Programmen wie Transcriber parallel zum Transkriptionstext auch die Audiodaten nachvollzogen werden. Es stellt sich dabei allerdings die Frage, ob ein kontinuierlicher Abgleich von Transkriptionstext und Originalaufnahme nicht einer Doppelbelastung gleich kommt, und ob hier nicht in vielen Fällen auf den Text verzichtet werden kann. [17]
Interviews, zumindest ethnographische (im weitesten Sinne) und insbesondere narrativ biographische Interviews, weisen gewisse Charakteristika auf, die sich zum Erstellen eines C-TOC nutzen lassen. Merkmale wie Eröffnungen, Höhepunkte, erzählerische Klammern usw. dienen dabei der Strukturfindung. Die Form, in der Interviews durchgeführt werden, entscheidet wesentlich über die Art der beobachtbaren Strukturmerkmale. Aber auch in jeweils ähnlichen Forschungssettings bzw. -projekten gibt es verschiedene Strukturmerkmale in Interviews, etwa wenn die interviewten Personen unterschiedliche Fähigkeiten zur Narration aufweisen. So gibt es solche Interviewpartner, die sehr strukturiert erzählen, und andere, die dies nicht können. Diese Unterschiede wirken sich auf die Gliederung aus; im einen Falle ähnelt das C-TOC dem Inhaltsverzeichnis eines Dramas oder einer anderen Literaturform, im anderen ist es eher fragmentiert, weist weniger zusammenhängende Sinnsequenzen auf, hat viele erzählerische Klammern usw. [18]
Es gibt unterschiedliche Herangehensweisen an die Erstellung eines C-TOC. So wird es nicht immer erwünscht sein, den natürlichen Strukturen, wie sie sich aus der Narration ergeben, zu folgen. Insbesondere in professionellen Feldern wie Journalismus oder Medizin mag sich die Form der Struktur eher am Interesse des Forschers orientieren denn an der natürlichen narrativen Struktur, die der Erzähler selbst vorgibt. In solchen Fällen würde ein C-TOC weniger offen gestaltet werden, sondern eher orientiert an vorhandenen Kategorien (s. Anmerkung 4). [19]
Im Rahmen einer ersten Orientierung im Material durch ein C-TOC mag eine offene Strukturierung, die sich an der Narration orientiert bzw. der Proband letztlich selbst vorgibt (SCHÜTZE 1983), die Erste Wahl sein. Dies gilt insbesondere dann, wenn Daten mit den jeweiligen C-TOCs zu Zwecken der Sekundäranalyse einer größeren Forschergemeinde mit unterschiedlichen Forschungsorientierungen zur Verfügung gestellt werden sollen. Im Idealfall geht aus dem C-TOC sowohl der Inhalt der Narration, also über was gesprochen wurde, als auch die Intention der interviewten Person, also wie erzählt wurde, hervor. Gegebenenfalls sind jedoch ebenso abstraktere Formen der Strukturbildung denkbar, etwa wenn C-TOCs im methodischen Rahmen der Objektiven Hermeneutik eingesetzt werden sollen (OEVERMANN, ALLERT, KONAU & KRAMBECK 1979). [20]
In den grau unterlegten Kästen befinden sich konkrete Arbeitsanweisungen für den Umgang mit Atlas.ti. Ihre Lektüre kann sich erübrigen, wenn der Inhalt des Beitrags erst einmal ohne die konkrete Anwendung des Programms nachvollzogen werden möchte.
|
Die mp3-Dateien werden in Atlas.ti importiert wie dies mit Textdateien auch geschieht (siehe dazu, wie auch zu weiteren Beschreibungen bezüglich der Bedienung von Altlas.ti, das Manual der Software). Nach dem Importieren wird das PD (Primary Document) aufgerufen, wodurch der Audioplayer erscheint und die Audiodatei sogleich angespielt wird. Der Audioplayer bietet die Funktion, in der Zeitleiste Markierungen vorzunehmen (s. in Abbildung 1 die drei rot eingerahmten Buttons). Hiermit werden Start und Ende einer Sinnsequenz markiert und als "Quotation" festgehalten. Diese Quotation wird nun umbenannt mit Quotations>Miscellaneous>Rename List Entry (standartgemäß heißt jede Quotation bei Audiodateien wie das PD) in einen die Sequenz adäquat bezeichnenden Ausdruck. (Hierzu stehen in der Länge etwa 30 Zeichen zur Verfügung.) Das PD muss linear von vorne nach hinten sequenziert werden, da eine nachträgliche Sortierung nicht mehr möglich ist. Das heißt dann auch, dass bei einer Gliederung in verschiedenen Ebenen die Sequenzierung der höheren Gliederungsebene der niedereren vorausgehen muss. Was das bedeutet, wird bei Betrachtung von Abbildung 1 deutlich. Im Beispiel muss also das der höchsten Ebene angehörige Segment "Contract betw. rich and poor" zuerst erstellt werden, und erst danach die diese Sequenz genauer beschreibenden drei Segmente der zweiten Ebene. [21] |
Das gesamte Interview wird wie im grauen Kasten beschrieben anhand der Aufzeichnungen, die zuvor während des Zuhörens auf einem Blatt Papier festgehalten wurden, segmentiert. In Abbildung 1 handelt es sich um ein segmentiertes Interview mit einer Länge von etwa 7,5 Minuten. Es besteht insgesamt aus 12 Sinnsegmenten (s. im Fenster "Quotations" rechts unten), wobei Segment Nr. 2 und Segment Nr. 8 die jeweils höheren Ebenen von Nr. 3, 4, 5 einerseits und Nr. 9, 10, 11, 12 andererseits darstellen. Die Segmente der niedereren Ebene beschreiben also genauer, was es mit dem "Contract betw. rich and poor" einerseits und "The Role of Science" andererseits auf sich hat. Zum Beispiel äußert sich Jeffrey Sachs in Segment Nr. 10 ("Available Knowledge") über das verfügbare Wissen. Dieses Segment repräsentiert einen Teil des Segments (bzw. Kapitels) Nr. 8 ("The Role of Science"). Dass es sich dabei um eine niedrigere Ebene handelt, wird durch Bindestriche am Anfang der Bezeichnung deutlich gemacht. Falls es erforderlich wird, eine dritte Ebene hinzuzufügen, also die "Kapitel" der zweiten Ebene weiterhin zu differenzieren, werden entsprechend mehr Bindestriche eingefügt.5)
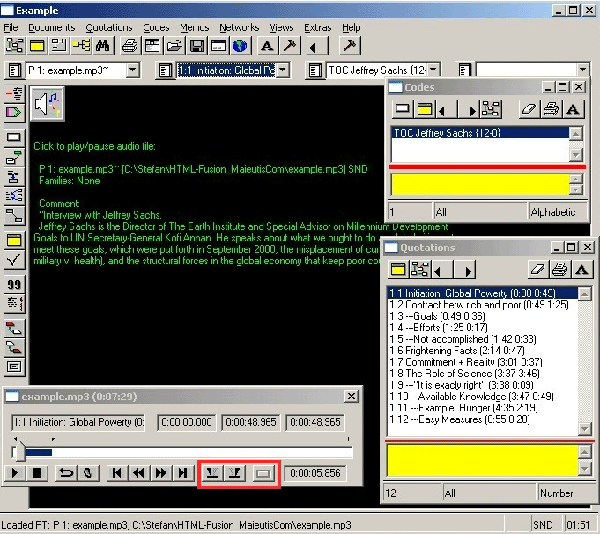
Abbildung 1: Das C-TOC in Atlas.ti [22]
Die Orientierung am reinen Inhalt kommt durch die Wahl der Kapitelbezeichnungen zum Ausdruck. Diese geben grob wieder, worum es sich in diesem Gespräch handelt. Lediglich das Segment Nr. 9 ("It is exactly right") bezeichnet weniger eine Inhaltsangabe dieser Passage denn eine markante Bemerkung seitens des Interviewpartners. Diese Passage so zu bezeichnen ist eine ad-hoc Interpretation während der Segmentierung gewesen. Im Prozess der Erstellung eines C-TOC gibt es sehr viele ad hoc Entscheidungen, ansonsten würde es zu lange dauern und ein entscheidende Vorteil gegenüber einer Transkription wäre dahin.6) Dieses Segment Nr. 9 hätte auch anders bezeichnet werden können, etwa "Entrüstung über Untätigkeit" oder so ähnlich. Denn der Interviewpartner gibt eben einer solchen Entrüstung Ausdruck. Hier wird nun deutlich, was es mit dem Kontextwissen auf sich hat, auf das der Analysierende während seiner zukünftigen Arbeit mit dem Material zurückgreifen kann. Denn wenn er ausreichend oft mit dieser Passage konfrontiert wurde, wird er im zukünftigen Analyseprozess sehr wohl wissen, dass es sich hierbei um einen Ausdruck der Entrüstung handelt (Erinnerungswissen). Er muss unter Umständen noch nicht einmal mehr in diese Passage reinhören (obwohl ihm dies durch einfachen Mausklick ermöglicht wird). [23]
Die einzelnen Segmente können nun also mit einem Doppelklick aufgerufen werden. Sofort werden sie dann angespielt. Ist ein Inhaltsverzeichnis auf diese Weise erstellt und die Segmente sowohl ausreichend kurz als auch aussagefähig, kann diese Struktur, und können vor allen Dingen die einzelnen Segmente, für alle weiteren Untersuchungen verwendet werden.7) Unter Umständen – je nach Forschungsinteresse und Bedürfnis nach Genauigkeit – müssen nun keine neuen Quotations (Segmente bzw. "Kapitel") mehr erstellt werden. Zur Analyse stellt Atlas.ti viele Möglichkeiten bereit. Die vorhandenen Quotations lassen sich miteinander verknüpfen. Des Weiteren können sie in den gelben Feldern detailliert kommentiert werden. Längere Traktate zu ihnen mögen als Memos erstellt werden, welche dann ebenfalls mit anderen Teilen (Quotations, Codes, Memos) innerhalb von Altas.ti in Relation gebracht werden können. Solcherart Verknüpfungen lassen sich graphisch in einer Netzwerksicht darstellen. Es können sowohl Elemente mehrer Audiodokumente (z.B. Segmente aus verschiedenen Interviews) miteinander auf diese Weise verknüpft werden, als auch andere Aufzeichnungen wie Texte, Bilder oder Videodateien. Altas.ti speichert die Relationen auf Wunsch in einer einzigen Datei. Auf diese Weise verweisen entsprechend erstellte Kodierungen und Relationen auf viele unterschiedliche Dokumenttypen, unter Umständen auf alle im Forschungsprojekt vorhandene Daten. Wenn nach einem Kode gefiltert wird, erscheinen also Segmente aus den verschiedensten Dokumenten in einem Fenster und können mit Doppelklick direkt angesteuert werden. [24]
Die Kodierungsfunktion ist eines der wichtigsten Instrumente in Atlas.ti. Einen sehr einfachen, aber wichtigen Kode bildet in Abbildung 1 eben jener, der die Quotations als Inhaltsverzeichnis auszeichnet (s. im Code-Fenster rechts oben: "TOC Jeffrey Sachs"). Denn wenn erst einmal sehr viele verschiedene Audiodokumente in einem Forschungsprojekt vorhanden sind, können im Fenster Quotations schnell mehr als tausend solcher Segmente erscheinen. Der Rückgriff auf das Rohmaterial (retrieval) erfolgt im Rahmen von Filter- und Suchaktionen. Schon ein Doppelklick auf den Kode "TOC Jeffrey Sachs" ist eine Filteraktion. Es öffnet sich ein separates Fenster, in dem nur solche Segmente angezeigt werden, die ihm zugeordnet sind. In diesem Fenster können sie dann auch direkt angesteuert werden.
|
Um nun nur eine solche Gliederung anzuzeigen, welche zu einem speziellen Audiodokument gehört, wird, nachdem die Sequenzierung abgeschlossen ist, ein Code erstellt, der diese Gliederung ausdrückt (im Beispiel "TOC Jeffrey Sachs"). Dieser wird nun mit den entsprechenden Quotations verlinkt: Codes>Coding>Link Code to: >Quotations. Hier werden dann alle Quotations ausgewählt (mit Shift-Taste und Maus). Nun kann nach diesem Code gefiltert werden. Oder bei Doppelklick auf den Code im Codefenster erscheint ein kleines Fenster, in dem man schnell mit einfachem Mausklick die einzelnen Segmente anspielen kann. [25] |
Das Spulen von Kassetten und Tonbändern, oder auch nur das Stöbern in riesigen Regalen voller Akten mit transkribierten Texten erweist sich im Vergleich hierzu als antiquiert und umständlich. Hier ist das gesamte Projekt, unter Umständen mit allen erdenklichen Aufzeichnungen und Randbemerkung usw., auf einem Computer Platz sparend und sehr schnell zugänglich gelagert. Dieser muss noch nicht einmal ein Hochleistungsrechner sein. Schon mit einem heutzutage altertümlich anmutenden Notebook mit einem Pentium II Prozessor stellt diese Art der Analyse kein ernst zu nehmendes Problem dar. [26]
Die aktuelle Version 5 von Atlas.ti erlaubt auch erweiterte Suchoperationen in den eigenen Aufzeichnungen, welche unter Umständen als Memo oder Bemerkungen zu Quotations oder Codes gespeichert, ebenfalls ganze Aktenberge produzieren können. Es mag sinnvoll erscheinen, solche Aufzeichnungen auch in Papierform zur Verfügung zu haben. Hierzu stellt Atlas.ti einige Exportfunktionen zur Verfügung. Version 5 ist mit einer innovativen und universalen Schnittstelle – das XML-Format – versehen, was zukünftig noch weitere Anwendungsmöglichkeiten mit sich bringt – etwa die Publikation eines Inhaltsverzeichnisses im Inter- oder Intranet, wobei die Segmente in einem Internet-Browser dargestellt, angesteuert und abgespielt werden können. Dies wäre die ideale Form, wenn Audiodaten auf einem zentralen Server gelagert, oder mittels File-Sharing Systemen innerhalb der Forschergemeinde verteilt werden sollen. [27]
Die zu dem Beispiel in Abbildung 1 gehörigen Dateien können auf http://www.maieutis.de/ herunter geladen und mit der bei http://www.atlasti.com/ kostenlos verfügbaren Demoversion von Atlas.ti ausprobiert werden. [28]
3.4 Exkurs: Arbeiten mit mp3cutter und Winamp als Alternative
In Fällen, in denen sich die Übersichtsfunktion, welche ein C-TOC bietet, als ausreichend erweist, kann sich der Einsatz von QDA-Software erübrigen. Die Kombination der Freeware-Pogramme mp3cutter und Winamp mag für all jene eine Alternative sein, die sich in Altas.ti nicht einarbeiten wollen bzw. zeitliche und finanzielle Ressourcen knapp sind, und sie auf eine weitere Analyse auf Basis des C-TOC verzichten können. Man kann sich hier solch professionelle Felder wie Medizin oder Journalismus vorstellen, in denen zwar mit Interviews gearbeitet wird, diese jedoch lediglich als Informationsquelle dienen, ohne weiteren Bedarf einer Analyse. Allerdings gilt es, einige Nachteile in Kauf nehmen zu müssen. Die ursprüngliche mp3-Datei wird mit dem Programm mp3cutter auch "physikalisch" aufgeteilt, so dass, je komplexer die Gliederung ist, desto größer der Platzbedarf sein wird. Denn die Segmente werden von der ursprünglichen Originaldatei kopiert und in eigene Dateien geteilt (cut). Diese können daraufhin mit Winamp in entsprechender Reihenfolge als Gliederung dargestellt werden.
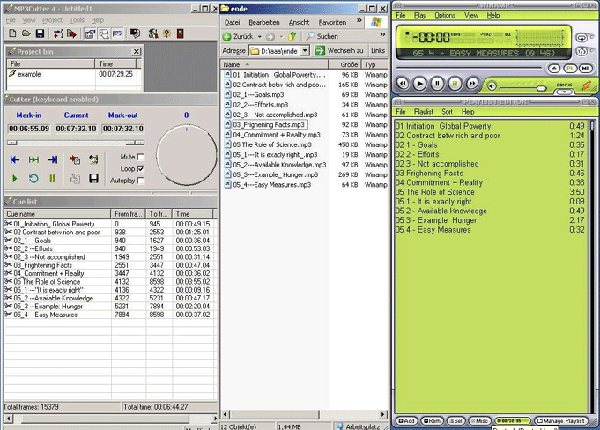
Abbildung 2: Das C-TOC in mp3cutter, Windows Explorer und Winamp [29]
Abbildung 2 zeigt im linken der drei Fenster das Programm mp3cutter. Hier wurde die eine mp3-Datei – das gleiche Interview wie zuvor in Atlas.ti dargestellt – in kleinere Dateien aufgeteilt (s. die "Cue List" unten), welche dann entsprechend bezeichnet wurden (zur Bedienung von mp3cutter siehe die Hilfedateien des Programms).
|
Nach Export dieser Segmente als mp3-Dateien (alle markieren und Exportfunktion aufrufen) ergeben diese in einem Ordner entsprechend verschiedene Einzeldateien (s. das mittlere Fenster, welches einen Ordner im Windows Explorer darstellt). Hierbei ist zu beachten, dass die Dateinamen so ausgewählt werden, dass die Gliederung in Winamp gewahrt bleibt. Die in der Abbildung dargestellten Namen sollen nur als Beispiel dienen. Die Dateien können auch anders bezeichnet werden. Wenn die Dateien erst einmal in einem Ordner abgelegt sind (dieser Ordner sollte dann entsprechend dem Interview bezeichnet sein), können sie alle markiert (im Windows Explorer mit <String> + <A>) und mit der rechten Maustaste in Winamp "eingereiht" werden. Falls die Gliederung nicht wie im Windows Explorer erscheint, muss mit der Funktion <Sort> <Path and File Name (oder ähnlich)> die Reihenfolge richtig sortiert werden. [30] |
Sogleich erhält man in Winamp die Struktur wie im rechten Fenster von Abbildung 2 dargestellt. Hier kann dann mittels Mausklick auf die einzelnen Segmente zugegriffen werden. Auch über die Zeitleiste kann mit der Maus (mit gedrückter linker Maustaste) navigiert werden. [31]
Playlisten lassen sich ausdrucken und auch abspeichern, so dass diese in Winamp nur noch aufgerufen werden müssen. Dazu dürfen die einzelnen Dateien allerdings nicht verschoben werden, weil die Funktion diese dann nicht mehr finden kann. Alles in allem ist dies ein sehr einfaches Verfahren, das ebenfalls einen guten Überblick über die Audiodateien und einen sehr schnellen Zugriff auf einzelne Teile bietet. Allerdings ist mit diesem Verfahren die weitere Analyse nur mit anderen Mitteln zu verwirklichen. Für viele Zwecke mag dies ausreichend sein. [32]
Die Programme können hier herunter geladen werden: mp3cutter (http://mp3cutter.cjb.net/); Winamp (http://www.winamp.com/). [33]
3.5 Arbeiten mit C-TOC Elementen
Die im Rahmen eines C-TOCs erstellten Sequenzen eignen sich über die Überblicksfunktion hinaus für viele Formen der Analyse mit QDA Programmen wie Atlas.ti. Sie können in dieser Form als Basiselemente von Analysen wieder verwendet werden. Abbildung 3 zeigt zum Beispiel die Netzwerkansicht einer Analyse in Atlas.ti, welche auf den Elementen von C-TOCs aufbaut. Die dargestellten Sequenzen, allesamt die Problematik von Nachbarschaften im Stadtquartier ansprechend, sind aus verschiedenen Experteninterviews entnommen und wurden einem Fragebogen-Item eines quantitativen Surveys zugeordnet, der ebenfalls diese Thematik erfragt. Dieser Fragebogen-Item "018-020_Nachbarschaft" wurde in Form eines Kodes innerhalb von Atlas.ti erstellt. Es handelt sich dabei um die Fragen 18 bis 20 eines Fragebogens. Die konkreten Fragen sind in das gelbe Feld für Notizen eingetragen worden (vgl. in Abb. 1 das gelbe Feld im Code-Fenster). Sobald in der Netzwerkansicht (Abb. 3) auf das Item geklickt wird, werden diese angezeigt. Die hiermit verknüpften Audiopassagen können mittels Doppelklick angesprochen werden (die erste Zahl in der Klammer gibt Auskunft darüber, um welches Interview innerhalb des Projekts es sich handelt, die zweite über die Position der Sequenz im Interview).
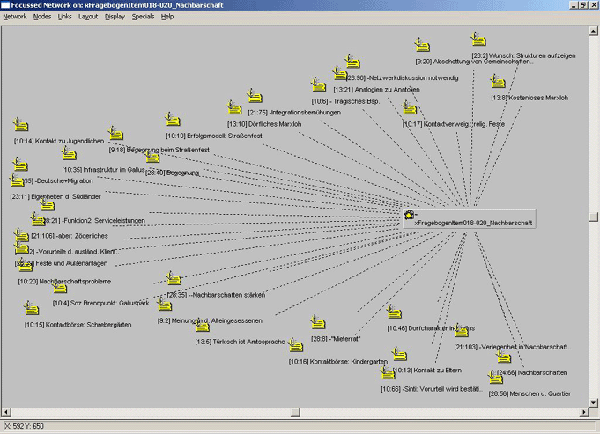
Abbildung 3: Network View in Atlas.ti. Ein Kode und seine Ausprägungen [34]
Auf diese Weise ist ein direkter Vergleich zwischen qualitativen Daten und dem Ergebnis eines quantitativen Surveys möglich. Es können also die Ergebnisse einer repräsentativen Umfrage mit den Aussagen einzelner Personen verglichen werden. Das Erstellen dieser Relation ist weniger zeitaufwendig als es zu vermuten wäre. Denn die einzelnen Interviews müssen weder nachgehört, noch ihre Vertextungen nachgelesen werden. Es reicht aus, die jeweiligen C-TOCs nach den entsprechenden Thematiken zu durchforsten8) und passende Segmente mit dem Kode zu verknüpfen (in diesem Fall mit dem Survey Item). Im Zweifelsfalle, also wenn sich aus der Betitelung der Segmente nicht genügend Information bezüglich der Adäquatheit einer potentiellen Verknüpfung ergibt, können die fraglichen Segmente durch Doppelklick angespielt werden. [35]
Nachdem also Relationen zwischen einzelnen Daten erstellt worden sind, ist der Zugriff auf die Daten selbst sehr schnell möglich. Wie beschrieben handelt es sich dabei um die Rohdaten. Fehlertoleranter als eine Transkription ist ein C-TOC also deshalb, weil die Analyse nicht auf dem C-TOC selbst beruht, sondern auf dem Rohmaterial. Das C-TOC dient dabei nur als Hilfsmittel, wenn auch als entscheidendes. Dem Forscher steht jedoch die gesamte Information als authentisches Forschungsmaterial ständig zur Verfügung. Das einzige, was ihn stören könnte, ist die unterschiedliche Interpretation, wie sie sich in der Gliederung selbst äußert. Diese Problematik ist allerdings überschaubar. Wenn die Gliederung nicht völlig fehlgeschlagen ist, sollte sie nach wie vor als Informationsbasis genügen, denn der Wiedererkennungswert der Sequenzen ist nach wie vor gegeben. Wenn der Forscher eine solche auch anders benannt und deren Zeitgrenzen anders gesetzt hätte, haben diese dennoch "Namen" und erinnern ihn, wie dies bei Kontextwissen der Fall ist. Er kann die entsprechende Sequenz auch einfach nach eigenem Gusto umbenennen. [36]
In eigenen Projekten kann mit der Sichtung des C-TOCs schnell auf den Inhalt schon in vergangenen Projekten durchgeführter Interviews oder aufgezeichneter Daten aller Art geschlossen werden. Noch aufschlussreicher mag ein C-TOC sein, wenn es als Teil einer Inhaltsangabe bei der Distribution von Audiodaten innerhalb einer Forschergemeinde dient, etwa mittels entsprechender File-Sharing Systeme oder durch Zugriff auf einen zentralen Server – eine Infrastruktur, die zwar in Ansätzen schon verfügbar ist (z.B. das SozioNet http://www.sozionet.org/ oder das UK Data Archive http://www.data-archive.ac.uk/), die jedoch noch in den Kinderschuhen steckt und auszubauen gilt (vgl. den "Traum" von FIELDING 2000, [25]), und was auch einige Schwierigkeiten in sich birgt, wie etwa die Anonymisierung von Daten (vgl. hierzu den Beitrag von PÄTZOLD). [37]
In diesem Beitrag wurde erläutert, wie sich mit einem "Clickable Table of Contents" (C-TOC) die Komplexität qualitativer Audiodaten so reduzieren lässt, dass sie in ihrer authentischen Beschaffenheit analysiert werden können, ohne auf die Hilfskonstruktion in Form von Transkriptionen zurückgreifen zu müssen. Die zur Verfügung stehende Technologie lässt eine solche Umorientierung innerhalb der Sozialwissenschaften zu. Die Analyse am Rohmaterial erweist sich in vielerlei Hinsicht als vorteilhaft. Durch Verzicht auf den Zwischenschritt der Transkription verringert sich die Fehlerquote in der Analyse. Durch Zugriff auf die Rohdaten kann ein Phänomen ausführlicher erfasst werden, als es in einer Transkription möglich wäre. In der Form, wie das Rohmaterial durch C-TOCs aufgearbeitet ist, werden Passagen innerhalb des Materials schneller zugänglich. Ihre Elemente können als Quelle für die Erstellung von Relationen und Kodierungsprozeduren mittels QDA-Software dienen, wobei die Übersichtsfunktion über das Material durch das C-TOC als Ganzes gegeben ist. Diese Vorteile sind verbunden mit der Möglichkeit, Kosten zu sparen, da die Erstellung eines C-TOC weniger Zeit in Anspruch nimmt als das Transkribieren. [38]
Angesichts einer solchen Umorientierung in der Methodik stellen sich nicht so sehr Fragen, inwiefern QDA-Software zur qualitativen Sozialforschung beitragen kann bzw. welche Gefahren ihre Verwendung mit sich bringt, und ob ihre Anwendung überhaupt sinnvoll ist (vgl. z.B. COFFEY, HOLBROOK & ATKINSON 1996; CARVAJAL 2002). Vielmehr scheint zweifelhaft, ob zukünftige qualitative Sozialforschung, möchte sie auf die Möglichkeit der Rohdatenanalyse nicht verzichten, noch ohne QDA-Software auskommen kann. Ebenso lässt sich über mögliche neue Professionalisierungsfelder im Rahmen dieser Umorientierung nachdenken. Denn wie die Möglichkeit der Tonbandaufnahme die Möglichkeit der Verschriftlichung, und somit die Profession des Transkribierens impliziert hat, so sind für die Handhabung qualitativer Audio-Rohdaten professionelle Tätigkeiten im Vorfeld der eigentlichen wissenschaftlichen Analyse notwendig. Professionell bedeutet in diesem Zusammenhang immer auch Spezialisierung, mithin also die Möglichkeit der Fremdvergabe. Als Beispiel für eine solche professionelle, im Wesentlichen nicht-wissenschaftliche Tätigkeit wurde in diesem Beitrag das Vorbereiten des Audio-Materials und das Erstellen eines C-TOC vorgeführt. [39]
Ich möchte zunächst Benito BERMEJO aus Madrid danken, der mir einst in der Atlas.ti-Mailingliste den Tipp gab, ein Inhaltsverzeichnis in der Kombination von Quotations und Codes zu erstellen – wenn sich diese Vorgehensweise damals auch noch auf verschriftlichte Interviews bezog. Mein Dank gilt vor allen Dingen dem damaligen Leiter des Projekts Mehrdimensionale Fremdfiguren und Einstellungsfigurationen: Qualitative Analyse der Integrationsbereitschaft in der allochthonen und der autochthonen Bevölkerung an der Universität Bielefeld, Dr. Fridrik HALLSSON. Er hat mir alle Freiheiten gewährt, mit der QDA Software zu experimentieren, um die biographisch-narrativen Interviews dieses Projekts in einen adäquaten Forschungsrahmen einzupassen. Des Weiteren hat er mich auf das Erscheinen dieser Schwerpunktausgabe aufmerksam gemacht und mich ermutigt, mit einem Beitrag meine Erfahrungen diesem Forum zur Verfügung zu stellen.
1) Ein auf etwa 25 Interviews beruhender Erfahrungswert lässt die Länge der einzelnen Sequenzen zwischen 20 und 90 Sekunden pendeln. <zurück>
2) Es sei etwa gedacht an den Nachvollzug des konkreten Erzählstrangs einer Person einerseits, und an abstrahierende Perspektiven andererseits – z.B. eine solche, welche die Erzählmotivation einer Person festhalten möchte. <zurück>
3) Besonders negativ wirkt sich dies bei Transkriptionen aus, wenn sie nicht fachgerecht oder unter Zeitdruck erstellt werden. So werden etwa schwer verständliche Passagen schlicht ausgeklammert oder Vermutungen über den Inhalt angestellt, statt die Passage mehrere Male nachzuhören oder gar die Qualität des Materials zu verbessern. Letzteres ist bei digitalisierten Audioquellen mit vertretbarem Aufwand möglich. Im Prozess der Transkription ist es möglich wenn nicht wahrscheinlich, dass Information verloren geht oder, schlimmer noch, durch inkorrekte Transkription verfälscht wird. <zurück>
4) Genau genommen handelt es sich bei der Erstellung eines C-TOC nicht um einen Kodierungsprozess im eigentlichen Sinne. Zwar ist es denkbar, eine grobe Form des offenen Kodierens nach Anselm STRAUSS (1998) anzuwenden. Der umgekehrte Weg ist ebenfalls möglich, indem etwa schon vorhandene Kategorien dem Material zugeordnet werden (vgl. z.B. der Prozess des Erstellens von Datenbanken bei KÜHN & WITZEL 2000). Das C-TOC, wie es hier verstanden wird, ist allerdings weniger voraussetzungsreich. Erforderlich ist lediglich, das Material lückenlos zu segmentieren, so dass jede Passage des Materials auch eine Bezeichnung erhält. Durch diese Bezeichnung erlangt jede segmentierte Passage zugleich ein Alleinstellungsmerkmal, also ist diese Form der Analyse eher als Indexierung denn als Kodierung zu verstehen. Denn Kodes werden aufgrund gemeinsamer Merkmalsausprägungen verschiedener Passagen im Material erstellt. Auf welcher analytischen Ebene nun eine solche Indexierung, also die Segmentierung des Materials, geschieht, ist eine Frage, die jeweils im Forschungsprojekt geklärt werden muss. Bei reiner Orientierung am Inhalt, also im Verzicht auf analytisch-sozialwissenschaftliche Abstraktionen, ist die Erstellung eines C-TOC in relativ kurzer Zeit möglich. Die wichtige Funktion, das Material auf ein Niveau herunter zu brechen, in dem das Kontext- und Erinnerungswissen des Forschers wirken kann, bleibt dabei erhalten. <zurück>
5) Es wäre auch eine Zahlengliederung möglich. Da Altas.ti jedoch immer schon automatisch Zahlen der Quotation vorausstellt – die erste bezeichnet die PD Nummer, die zweite die Quotation Nummer –, würde dadurch ein Zahlengewirr entstehen. <zurück>
6) Es ist natürlich jedem frei gestellt, sich mit dieser Prozedur länger aufzuhalten. Wenn sie jedoch als Prä- oder Erst-Analyse verstanden werden soll, ist dies weniger ratsam. <zurück>
7) Eine Sequenzlänge von zwischen 20 und 90 Sekunden Länge hat sich zwar in Experteninterviews und narrativen Interviews als sinnvoll erwiesen. In Forschungsprojekten, die Interviews sehr differenziert analysieren, etwa im Rahmen linguistischer Forschung oder der Konversationsanalyse, kann sich dies jedoch als zu lang erweisen. <zurück>
8) Dies geschieht üblicherweise im Fenster "Quotations" (vgl. Abb. 1). <zurück>
Carvajal, Diógenes (2002). The Artisan's Tools. Critical Issues When Teaching and Learning CAQDAS [46 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research [Online Journal], 3(2), Art. 14. Verfügbar über: http://www.qualitative-research.net/fqs-texte/2-02/2-02carvajal-e.htm [Datum des Zugriffs: 22.08.2003].
Coffey, Amanda; Holbrook, Beverley & Atkinson, Paul (1996). Qualitative Data Analysis: Technologies and Representations. Sociological Research Online [Online Journal], 1(1). Verfügbar über: http://www.socresonline.org.uk/1/1/4.html [Datum des Zugriffs: 16.08.2003].
Fielding, Nigel (2000). The Shared Fate of Two Innovations in Qualitative Methodology: The Relationship of Qualitative Software and Secondary Analysis of Archived Qualitative Data [43 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research [Online Journal], 1(3), Art. 22. Verfügbar über: http://www.qualitative-research.net/fqs-texte/3-00/3-00fielding-e.htm [Datum des Zugriffs: 16.10.2004].
Kühn, Thomas & Witzel, Andreas (2000). Der Gebrauch einer Textdatenbank im Auswertungsprozess problemzentrierter Interviews [115 Absätze]. Forum Qualitative Sozialforschung/Forum Qualitative Social Research [Online-Journal], 1(3), Art. 18. Verfügbar über: http://www.qualitative-research.net/fqs-texte/3-00/3-00kuehnwitzel-d.htm [Datum des Zugriffs: 15.12.2004].
Oevermann, Ulrich; Allert, Tilmann; Konau, Elisabeth & Krambeck, Jürgen (1979). Die Methodologie einer "objektiven Hermeneutik" und ihre allgemeine forschungspraktische Bedeutung in den Sozialwissenschaften. In Hans-Georg Soeffner (Hrsg.), Interpretative Verfahren in den Sozial- und Textwissenschaften (S.352-433). Stuttgart: Metzler.
Schütze, Fritz (1983). Biographieforschung und narratives Interview. Neue Praxis, 13, 283-293.
Stockdale, Alan (2003). An Approach to Recording, Transcribing, and Preparing Audio Date for Qualitative Analysis. Verfügbar über: http://www2.edc.org/CAEPP/audio.html [Datum des Zugriffs:15.10.2003].
Strauss, Anselm L. (1998). Grundlagen qualitativer Sozialforschung. Datenanalyse und Theoriebildung in der empirischen soziologischen Forschung. München: Fink.
Tesch, Renate (1992). Verfahren der computerunterstützten qualitativen Analyse. In Günter L. Huber (Hrsg.), Qualitative Analyse. Computereinsatz in der Sozialforschung (S.43-69). München: Oldenbourg.
Stefan HAUPTMANN, Dipl. Soziologe (Schwerpunkt Wissenschaft + Technik, Qualitative Sozialforschung, diplomiert an der Universität Bielefeld). Graduiert als "M.Sc. in Technical Change and Industrial Strategy" am Institut PREST (Policy Research in Engineering, Science and Technology) an der University of Manchester / England.
Der Autor bietet das Generieren von C-TOCs als Service-Dienstleistung an.
Kontakt:
Stefan Hauptmann / MaiEUTiS
Dieffenbachstraße 36
1. HH
D-10967 Berlin
Tel.: +49 (0)30-868 701 917
Fax: +49 (0)721-151 388 494
E-Mail: stefan.hauptmann@maieutis.de
URL: http://www.maieutis.de/
Hauptmann, Stefan (2005). Das "C-TOC" zur Gliederung von Audiodaten. Ein Beispiel für die qualitative Analyse am Rohmaterial [39 Absätze]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), Art. 33, http://nbn-resolving.de/urn:nbn:de:0114-fqs0501331.
Revised 6/2008

Creative Commons Attribution 4.0 International License