Volume 12, No. 1, Art. 38 – January 2011
From the Past into the Future. How Technological Developments Change Our Ways of Data Collection, Transcription and Analysis
Jeanine C. Evers
Abstract: In the last fifty years, recording devices have taken a central position on stage in the empirical social sciences during data collection (tape and voice recorders, photo and video cameras). As Qualitative Data Analysis software (QDA software) enables us now to directly code digitalized media files, one might question the need for transcribing data files, thus transforming them into textual files. The central issue addressed in this article then, is whether or not QDA software enables us to skip the transcription of data (audio files and video files). To address this question, the why, what and how of transcription will first be explored. Secondly, manual transcription will be compared to transcription with voice recognition software. Thirdly, coding of textual transcripts will be compared to the direct coding of audio and/or video files. As QDA software is changing our analytic possibilities and to some extent our procedures, the conclusion will argue in favor of transcription, be it adapted to our research needs and integrated within QDA software.
Key words: transcription; QDA software; CAQDAS; voice recognition software; audio files; video files
Table of Contents
1. Introduction
2. What Kind of Data Files Do Researchers Transcribe?
2.1 Fieldnotes
2.2 Still and moving images
2.3 Audio recording
3. Influences of Technological Developments
3.1 Transcription methods
3.2 Technological developments in analyzing data
4. Why Transcribe Data?
5. How Do Researchers Transcribe? Four Types of Transcript
5.1 Transcription formats for verbal data
5.2 Transcription formats for visual data
6. Alternatives to Transcription
6.1 Voice recognition software
6.2 Direct coding on data segments in QDA software
7. Devising Your Own Transcript in Combination with QDA Software
8. Conclusion
8.1 Technical developments changing data collection and transcription
8.2 QDA software changing analysis procedures
1. Introduction1)
Over the last twenty years I have noticed what seems to be a trend towards a growing popularity of qualitative methods in The Netherlands, combined in the last ten years with an increased use of digital equipment and QDA software2). The central issue explored in this article then, relates to the question whether or not QDA software enables us to skip the transcription of data files. Several QDA software packages now offer the option of directly coding digital audio and video files3). Therefore, the question emerges whether or not one should be transcribing those files manually and convert them into textual files. [1]
This question is explored in Section 2 by looking at how technological developments have influenced data collection methods and what kind of data files are transcribed. Section 3 deals with what transcription is and how it is influenced by technological developments. Section 4 elaborates on why one would want to transcribe data in the first place, while Section 5 deals with the practicalities of transcription, i.e., how it is done. Section 6 explores two alternatives to laborious manual transcription, i.e., voice recognition software, and direct coding of audio or video files in QDA software. Section 7 develops some rules to apply in devising your own transcription format, assuming the use of QDA software. In the conclusive Section 8, I reflect on whether the format of transcripts might influence their interpretation. First, I will explore the integration of transcription in a CAQDAS-based project, looking for alternative procedures to optimize the use of QDA software. To that end, existing possibilities are discussed and wishes for adaptation of QDA software to ease the process, are brought forward. [2]
2. What Kind of Data Files Do Researchers Transcribe?
In this section, I will address the different types of data gathered that are susceptible to transcription: fieldnotes, visual and audio data. In my examples, experiences in anthropology, my area of training, will be my main focal point, although, of course, the data types mentioned in this section are also gathered in other disciplines. [3]
From the beginning of the 20th century, the collection of empirical data on social behavior became increasingly popular. Before this time, it was mostly travelers and missionaries who gathered such empirical material. However, their data collection was neither very systematic nor scientifically underpinned, as the social sciences were then only starting to develop. The development of qualitative empirical social sciences is closely linked to the influential Chicago School of Sociology (1915-1935), which developed innovative empirical data gathering and analysis methods (BULMER, 1986; LUTTERS & ACKERMAN, 1996), and the rise of anthropology as a scientific discipline, which occurred during the 19th century4), and was in some countries closely linked to colonialism (BARTH, GINGRICH, PARKIN & SILVERMAN, 2005; VERMEULEN, 1997). [4]
Anthropological data were and still are gathered mainly by taking notes "in the field" (now commonly referred to as fieldnotes), sometimes accompanied by drawings and collection of material objects (artifacts) from the culture under study (SANJEK, 1990; STOCKING, 2001). In early anthropology, transcription meant writing down a literal account of a story that the researcher was told (i.e., dictated) by an informant. [5]
Nowadays, the term transcription is mostly used for the verbatim transcript of a recorded interview or conversation. I will elaborate on different formats for transcription in Sections 3 and 6. The term fieldnotes is used to refer to various types of notes about observations during fieldwork and the reflection of the researcher on those events, and remains closely linked to the ethnographic method (EMERSON, FRETZ & SHAW, 1995; BOGDAN & KNOPP BIKLEN, 2007). As such, a first stage of analysis is embedded in fieldnotes, as the notes themselves are to a certain extent an analytic act, due firstly to the selection of what to write down during observation (jottings, initial notes) and secondly what to elaborate on when processing the jottings into full notes (EMERSON et al., 1995). Thirdly, the reflection of the researcher on the processes observed and their possible meaning is part of the first stage of analysis. [6]
Right from the discovery of photography in the mid-19th century, pictures started to become a supplementary source of information for anthropologists, serving as illustrations of the accounts in diaries and notebooks. For example, Felix REGNAULT, a French anthropologist, used serial photography as an early type of movie in 1895 (EL GUINDI, 2004). A well-known 20th century researcher is Margaret MEAD (1977), who structurally used photography to document her fieldwork. [7]
At the end of the 19th century, films were discovered as a means of capturing movement in action. This led to a new genre in Anthropology: the ethnographic documentary, known as ethno-cinematography5), which over time has become a research genre in its own right (HENLEY, 2010). Initially silent films were used, but from the 1960s films that included sound became available. [8]
Besides the more recent digitization of equipment, the effect of mobile phones with built-in cameras and microphones, and sites like YouTube, Hyves6) and Facebook in popularizing the use of visual and voice recording is not to be underestimated, as this is normalizing the use of digital media and as such, will presumably make recording easier for social research practice. [9]
It is no longer prohibited to the more specialized visual anthropologist or sociologist to collect visual data, although the genre ethno cinematography still remains quite specialist7). For further reading on visual data-collection and/or ethnographic film-making see e.g. El GUINDI (2004), GRASSINI (2007), ROSE (2007), STANCZAK (2007), BOHNSACK (2009), HEATH, HINDMARSH and LUFF (2010), SWINNEN (2010) and FQS 9(2) (JONES et al., 2008), FQS 9(3) (KNOBLAUCH, BAER, LAURIER, PETSCHKE & SCHNETTLER, 2008a) and FQS 11(2) (BALL & GILLIGAN, 2010). [10]
It became possible to record sounds around 1878. And the development of sound recording as a data collection method followed a similar pattern to that of still and moving imagery. Because of the option of direct recording in the "field," linguists and anthropologists started to replace their direct notation of dictated words or stories with audio recordings. Heavy and costly equipment was replaced, during the 1960s, by smaller analogue devices (at first the cassette recorder, later replaced by the Walkman), and more recently very small digital voice recorders have become relatively cheap and accessible. From the 1970s, the recorded interview became an increasingly popular and dominant research genre, as it meant research participants could speak for themselves and were heard "directly," instead of learning about them by way of researchers' notes or social surveys (GUBRIUM & HOLSTEIN, 2002). [11]
It seems obvious that wherever possible, data gathered should be recorded (digitally). Apart from the quality being significantly better compared to analogue recordings, thus improving the possible quality of the transcript (compare ASHMORE & REED, 2000 or ROSS, 2010), one can edit digital files quite easy, e.g., in anonymizing them with editing software. A rather new development related to digitalized data in qualitative research is storage in archives, giving other researchers a chance for secondary analysis8). For further reading on this, see HEATON (2004) and WITZEL, MEDJEDOVIĆ and KRETZER (2008), and FQS 6(1) (CORTI, WITZEL & BISHOP, 2005) on the subject. [12]
3. Influences of Technological Developments
Before turning to technological developments that improved and eased transcription methods over time, a short introduction of what is meant by transcription in this paper is required. Transcription in the sense discussed here, i.e., transforming audio files, video files or photographs into text, can take different formats, depending on analytical needs, theoretical or disciplinary background, and the time and money available for the process. Section 6 elaborates on these formats further. [13]
Since the hand-written records and journals of the travelers and missionaries mentioned before, several appliances were introduced that improved the process of creating transcripts. For example, the introduction of the mechanic (and later the electric) typewriter and carbon paper9), the availability of Tipp-Ex or such correcting devices, enormously improved possibilities for altering or correcting text10). The introduction of the transcription machine with a foot pedal made it even easier to create a verbatim transcript from recordings, as it eased listening, typing and rewinding significantly. With the introduction of the personal computer in 1981 a real revolution has taken place, and its full implications are yet to be discovered. From that time onwards it became even easier to change texts, thus having an enormous impact on the time needed for transcription and the ease of correction. [14]
When digital audio and video were introduced, the resulting digital files could be transferred onto the personal computer, and thus transcribed directly. Initially this was done by combining word processor software with some media player software, which was not very user-friendly, due to the separate windows and media players not being very adequate for the job as they could not manipulate the file enough to ease the transcription process. [15]
With the introduction of transcription software packages, starting from the 1990s onwards, word processor and media player were combined. Examples of such software packages11) are F4 and F5, HyperTRANSCRIBE, Express Scribe, Transcriber, and Transana. This enabled the researcher to both listen and write within one software and window, further easing the transcription process. Other built-in tools are designed to make the tedious task of transcribing easier. For example, the playback speed can usually be altered, and some include an automated spool back interval (e.g., five seconds), both making it less necessary to rewind the audio file. In addition, a foot pedal or keyboard function buttons can be used to speed up typing, and many packages include the possibility to synchronize the audio or video file with the transcript through the insertion of timestamps (see e.g., SILVER & PATASHNICK, 2011, as well as WOODS & DEMPSTER, 2011, this issue), which enables one to switch from transcript to audio seamlessly. This last feature adds new possibilities to analysis which is discussed below in Section 3.2 and in Section 6. [16]
3.2 Technological developments in analyzing data
Alongside the digitization of data collection, starting in the mid-1980s, QDA software was being developed12), altering our way of dealing with qualitative data. For example13):
it is a lot easier to see relations between parts of the dataset because certain tools in QDA software (hyperlinks, codes, families and network views) facilitate this;
the dataset can be more rigorously questioned because it is easily done and very fast. One does this by searching through our codes in creating all sorts of output and thus querying the dataset with hypotheses one would never have pursued earlier because of the work involved in doing so, and by automatic searching on words in text (cf. KONOPÁSEK, 2008, who describes this process beautifully);
researchers are able to work more transparently because the software automatically keeps track of some of what is going on in their project (packages vary in how much they automatically track), while certain tools (memos, annotation boxes, linking objects to one another) are facilitating that as well, by enabling the researcher to manually keep track of his/her developing thoughts, ideas and methodological decisions surrounding the project;
the discipline of the researcher in keeping track of her/his thoughts and analytic decisions and checking the dataset with regard to hypotheses that evolve during data collection and analysis is eased, because everything is in one place if one uses QDA software. This clearly facilitates transparency and working systematically, and as such, is adding to the quality of our research. The traceability and systematization enhances reliability, while having everything in one place eases validation of codes and hypotheses versus the dataset.
As such, it is still the researcher who will need to discipline him- or herself in using all the tools. Thus, although the tools facilitate a lot, the researcher in the end is the one responsible for the overall quality of the project. [17]
Why would a researcher want to transcribe a recording at all? One of the reasons is that transcription enables us to get a verbatim record of what is being said and as such is a more accurate way of representing the interview than taking notes. CLAYMAN and TEAS GILL, who work within the tradition of conversation analysis, remark
"Transcripts make features of the recording more transparent and accessible, enabling one [=the researcher, JE] to 'see' the vocal and nonvocal activities that unfold on the tape. A good transcript helps the analyst to get a purchase on the organization of the interaction, including its fleeting and momentary features. A transcript is not a substitute for the recording, but rather is an essential analytical tool to be used along with the recording" (2004, p.593). [18]
In the event of a video recording, transcription of the spoken word is mostly accompanied by a fairly accurate description14) of what is being done, the interaction taking place and the features of objects and other contextual information on the setting that is the object of interest15) (see SILVER & PATASHNICK, 2011, this issue). [19]
In addition, transforming audio and video into text makes it easier to search the data (by means of QDA software or a word processor if digital, or even on plain paper), read it and mark it. Currently, audio and video files cannot be searched for words by the software16), thus forcing you to play and replay the files over and over again in coding them. [20]
The act of transcribing (specifically the verbatim version of what is said) is in itself partly analytic; making us more conscious of what is going on, either in the interview or in a videotaped situation, assuming the researcher is doing the transcription him- or herself. This heightened consciousness of content and context will deepen our understanding of data. In this sense, verbatim transcription may be seen as a first stage of analysis; one in which there is no selection of data segments yet, as the latter will be taken up in QDA software by segmenting and coding the data according to things deemed relevant and interesting for the research question. [21]
The ability to uncover more details through transcribing is also a function of reflexivity; one sees more detail if continuously reflecting on the data and our role in generating them whilst transcribing. [22]
The increased accuracy of, and heightened consciousness about data enhances the quality of analysis in diverse ways. Analysis will be more complete and perhaps richer. The increased reflection by the researcher, induced by her/his transcription of the data and immersion in the data, may make the analysis liable to further scrutiny regarding issues of validity and reliability. As you proceed, you wonder for example what exactly is meant by certain utterances, how they coincide with what you are looking for, if you have steered the interview too much, whether you have been asking suggestively formulated questions, thus making the answers not very useful, and so on (EVERS, 2007). If the transcription is done within QDA software, these reflections can be annotated directly into comments and analytical memos. [23]
But there are dangers in transcribing as well. The detail of a transcript can make you drown; all of a sudden there is much more data to consider (COFFEY & ATKINSON, 1996; GIBBS, 2010). And of course, this will cost more time analyzing, not to mention the extra time needed for transcription. As such, transcription adds to project budgets. In a transcript, certain things may get lost as well. GIBBS (2010, referring to KVALE [1996]) mentions the loss of speed, pause, intonation, song, pace, hesitation and garbling as a result of the transformation from verbal utterances to text. Some of this is addressed by Jeffersonian transcript formats, discussed in more detail in Section 5. Nevertheless, transcripts remain "cleaned up" versions of the actual interview, as text can never fully reproduce all of the dimensions of the "live" interview or observed conduct. [24]
After reading all this, you might wonder: why transcribe at all? I will return to that question in the conclusive section, but first Section 5 considers different formats for transcription. [25]
5. How Do Researchers Transcribe? Four Types of Transcript
As the chosen format of a transcript depends on several factors mentioned above (research question, theoretical viewpoint, time and budget), there is no definite definition available. Roughly, one can distinguish between four types of transcription format used, i.e., pragmatic, Jeffersonian, Goodwinian, and gisted transcripts. In the sections below, these different types of transcript will be described further for verbal (Section 5.2) and visual data (Section 5.3). [26]
5.1 Transcription formats for verbal data
The practice of transcription in social sciences, which I believe is most widely used17), and which I term pragmatic transcription, is the one in which researchers devise their own transcription format, tailored to their needs for analysis and the time and money available. It can be used in any kind of study, if the researcher sees this to fit his/her needs. Mostly these transcripts are a verbatim (i.e., exact) reproduction of what is said, but less elaborated than Jeffersonian transcripts, which will be dealt with in the next section. [27]
As pragmatic transcription18) is a format of transcription which is not formalized, it will produce a verbatim text which may differ per project. It will exclude things not needed for the particular analysis at hand (e.g., every instance of stuttering) and include aspects thought interesting or relevant (overlapping speech, silences/hesitations without timing them), depending on the specific purpose of analysis and the time and budget available19). Typically, it will take between four to eight hours per hour of tape, depending on audio quality, pronunciation and typing speed (EVERS, 2007). As an example, here is a self-devised transcript format I have used in several projects (EVERS, 2010):
JOHN: isn't this a nice day.
PETER: yes indeed. I wish it would be like this always. I'm more a [?] for the tropics …................................................................................................................................[
JOHN:….....................................................................................................................[
you are?
PETER: ......................................................................................................................[I think. The sun shines all the time, it is hot and you never have to wear a coat. (..) No, I definitely belong in the tropics. (laughs)
JANE: you think so? Oh, I prefer the Dutch climate myself. [28]
When, for instance, stuttering does not need to be included, I will just add the first stutter and leave out the ones that follow, or instruct my transcribers to do so, as it is not always possible in my working practice to transcribe my data myself. I do have specific notations for words not understood properly or for external disturbances20). [29]
5.1.2 Jeffersonian transcription
The Jeffersonian transcription21) is probably the most famous standardized, verbal transcription format. It was developed within conversation analysis (CA) by Gail JEFFERSON (PUCHTA & POTTER, 2004), and tries to compensate for the loss of sound, pace, intonation and interaction in the conversation, which get lost during the conversion of sound into text. It was devised to overcome these voids as best as possible. This is done by adding time references and standardized symbols into the text (see the example below). It is mostly used in language or interaction focused studies. [30]
Jeffersonian transcription is the most time-consuming format of transcription for verbal data; it can take up to 20 hours of transcription time per recorded hour (POTTER, 2004), because of all the add-ons in the text. Next follows an example, taken from TEN HAVE (2007, p.103)22):
E: Oh honey that was a lovely luncheon I shoulda ca:lled you
…..s:soo[:ner but I:]l:[lo:ved it.
M:..........[((f)) Oh:::].. [( )
E: It w's just deli:ghtfu[:l. ]
M: …..........................[Well]=
M: I w‘s gla[d............you] (came).]
E: …..........[‘nd yer f:] friends] ‘re so da:rli:ng,=
M: =Oh:::...[: it w'z ]
E: …..........[e-that P]a:t isn'she a do:[ :ll?,]
M: ….........[iYeh]h isn't she pretty,
…............(.)
E: Oh: she's a beautiful girl.=
M: =Yeh I think she's a pretty gir[l.=
E: …...........................................[En' that Reinam'n::
…...............(.)
E: She SCA:RES me.
Excerpt 1.1, from Heritage, 1984A:236 [NB:VII:2], taken from Paul TEN HAVE (2007, p.103) [31]
In reading this transcript, you can almost "hear" the text, if you know how to interpret all the added symbols23). The song and the pace of the text are "visible" in the transcript. [32]
A third way of transcribing is what GIBBS (2010) and DEMPSTER and WOODS (2011, this issue) call gisted transcription, a form of summarization, used whenever the researcher thinks this will be appropriate for his/her research. A gisted transcript can take several formats, just as the pragmatic transcript mentioned earlier. DEMPSTER and WOODS (2011, p.22) describe it as:
"The idea of gisting is to create a summary transcript that captures the essence of a media file's content without taking the same amount of time or resources as a verbatim transcript might require. Typically, a transcriber using Transana may take 4 or 5 hours to create a verbatim transcript of the spoken word in a typical hour-long media file, while such a file can be gisted in one to two hours." [33]
In my own research in Aruba in 1989 I did something similar, but worked the other way round. Having only a portable mechanical typewriter, Tipp-Ex and a Walkman available, I adopted the following procedure24). I taped my interviews, and undertook the following process:
Type detailed fieldnotes regarding my interviews and observations, based on my notes taken during the interview and my recollection of events and speech. For the typing up of my fieldnotes, I divided a page in two columns and only typed in the right column.
Afterwards, I would listen to my tape, and in the left column, correct mistakes I may have made in the right column, or add things that were not in my detailed notes, and as such created some sort of a gisted transcript. [34]
The left column was divided into two columns; one for corrections based on the tape and another one for further questions or points to take into consideration with analysis or ask subjects25). Table 1 shows an example about local custom surrounding the days after a woman has given birth26). Data are translated into English; interviews were done in the local language, Papiamento, and the original notes were in Dutch, with some citations in Papiamento. Underlined words in the fieldnotes in the right column resemble the citations which are in the same text. Otherwise I have translated the citations as well in "[..]".
|
Room for additional questions, analysis points |
Corrections based on tape |
Original elaborated fieldnotes |
|
|
You should keep your head covered because, due to the delivery "e nervio nan ta habri" [nerves are opening/playing up]. After 2-3 weeks she would go outside during daytime to hang laundry e.g., but not at nighttime and not outside of the premises. They thought you would get "friu" quickly. [friu is a word used for gynaecological illnesses, a common cold/flu, and temperature] |
D. told me that they [the women who had just given birth, JE] kept their head covered for 40 days ("kabez mará"), and that they got help around the house from a family member for 8 days. They were in bed for 5 days. After that, they were mobile and their belly was very tightly wrapped with a broad cloth, tied up in front "pa lomba sera" (=womb) [closing the womb], because otherwise there would be danger of "habrimentu di lomba" (=haemorrhage) [opening of the womb]. |
Table 1: Excerpt from gisted transcript EVERS (Dataset Aruba 1989) [35]
This pragmatically devised procedure, which is less precise than a verbatim transcript, added to the quality of my dataset: I did have taped interviews and included summaries and verbatim quotations in my detailed notes and corrections from those tapes. The disadvantage was that in working with detailed notes, I had already made selections from the material that struck me as interesting or fascinating. Although I added to those selective notes in listening back to the tape, they still focused my attention somewhat. In a full verbatim pragmatic transcript this would be less likely to happen. [36]
GIBBS (2010) in a video lecture illustrates a "gisted" transcript, created by listening to the audio file and leaving out all the utterings which do not seem relevant to the research question:
"90% of my communication is with ... the Sales Director. 1% of his communication is with me. I try to be one step ahead, I get things ready, ... because he jumps from one ... project to another. ... This morning we did Essex, this afternoon we did BT, and we haven't even finished Essex yet." (... indicates omitted speech)" [37]
It is obvious from these examples, that the gisted transcription format is developed by the researcher to meet specific needs, just as the pragmatic transcription format is. As such, both are bespoke, and can vary significantly between researchers and between projects. [38]
5.2 Transcription formats for visual data
When working with visual data, different transcription formats can also be utilized. As visual data entail even more layers of complexity than plain verbal (audio) data, these features may also require transcription (HEATH, HINDMARSH & LUFF, 2010). [39]
5.2.1 Pragmatic visual transcript combined with pragmatic verbatim transcript
DEMPSTER and WOODS (2011) describe how they dealt with the transcription of mostly visual data. A verbatim transcript alone was not sufficient, so they created "visual or descriptive transcripts," which
"reflected the visuals in the media file ... This in itself can be problematic as films and photographs are not neutral (BANKS, 2007). One of the difficulties of "capturing" the contents of a film or a series of photographs is understanding the additional properties associated with the image (CHAPLIN, 1994)" (p.14). [40]
Figure 1 is an example of a verbatim transcript combined with a separate visual transcript they created on the data from the KWALON experiment.
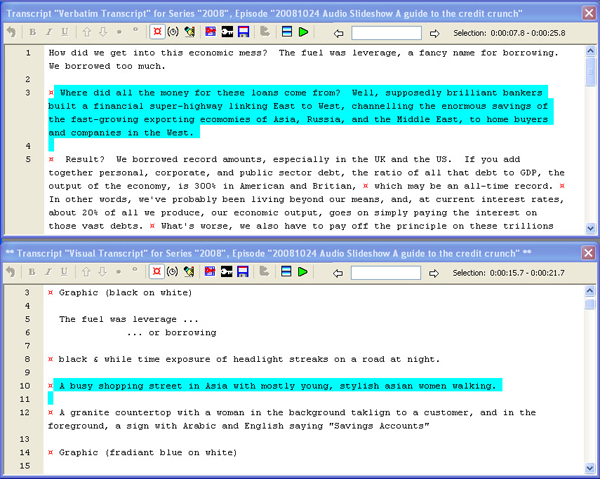
Figure 1: Screenshot of multiple pragmatic transcripts in Transana for the KWALON dataset (courteously made available by David
WOODS) [41]
In this example, both transcripts are of a pragmatic nature, but the visual transcript is far more elaborate than the pragmatic examples found for instance in SCHENSUL, LECOMPTE, NASTASI and BORGATTI (1999), or in SAUNDERS (2007). SCHENSUL et al. (1999, p.18) inserted the visual information in the verbal transcript, as opposed to the first example provided by DEMPSTER and WOODS. The heightened attention for visual aspects of conduct in SCHENSUL et al. (1999), in comparison to e.g. SAUNDERS (2007, p.158) might be determined by the quality of the observation and hence the notes, the research focus, or the availability of a video tape. In the next section, an even more elaborate example is provided, coming from the visual side of CA. [42]
5.2.2 Jeffersonian verbal transcript combined with Goodwinian visual transcript
The Jeffersionian type of transcription (which was directed towards speech) was later adapted by GOODWIN27) into Goodwinian transcription, to deal with visual information in a similar elaborated way by adding symbols into the text, as he was interested in the "gaze" as a means of where the attention of a participant of interaction was directed to (TEN HAVE, 2007, p.72). This is mostly used in studies interested in behavior and interaction. HEATH et al. (2010, pp.67-76) describe how they generate transcripts that cover several layers in the data, starting with verbal data (they use the Jeffersonian format, adding some contextual information), subsequently adding content that reflects layers of movement and interaction in different lines underneath28). They describe the difficulty in reporting these types of data using the verbatim format because of the multi-layered nature of the data (HEATH et al., 2010). The option to add several layers to a transcript, which are synchronized separately to the video file within QDA software, seems inevitable if one wishes to deal with video data this way. WOODS and DEMPSTER (2011, p.27f.) describe how they handled this in Transana where they had two video files and multiple layers of verbal data. They use a pragmatic transcription format, and at first they only seem to deal with the verbal utterances and online chat going on:
"... the two video files for this data set had largely independent audio tracks that sometimes converged and synchronized,
... and sometimes diverged, as when the observed player did talk-aloud for the camera and ignored the in-game chat going on
in the background ...
To handle this, the researchers created multiple verbatim transcripts, one for each media file. ... transcripts can be linked
to media files so that a highlight in the transcript moves as the video plays, showing the interplay between transcripts and
media files." [43]
But this was not sufficient for their needs. As the gaming speed was incredibly fast, they were not able to follow the game, so they decided to make yet another transcript. This transcript was totally devoted to what was going on in the game and as such reflected the screen of the gamer. This last visual transcript was of a hybrid format in between gisted and pragmatic, as they did mention everything that went on in the game, but in very short sentences29). [44]
Another option for transcribing visual data would be to add the spoken word as subtitles into the video, e.g. InqScribe will do this. HEATH et al. (2010, p.97) do not consider this an alternative to transcription. Rather, they see this as an additional layer for foreign language data, much the same as subtitles in a movie. [45]
Having dealt with several formats of transcription and their advantages and disadvantages, one might wonder: could there be an alternative to transcription? [46]
6. Alternatives to Transcription
As verbatim transcription takes a lot of time (varying from 4-60 hours per hour of audio or video recording, depending on the format used for transcription), it is evident that people wonder about alternatives that maximize the strong points of a recording and yet are more time-efficient. On an IT level, there seem to be two alternative options available to manual transcription. The first is transcription using voice recognition software; the second is coding data segments directly on either audio or video using QDA software. [47]
6.1 Voice recognition software
Voice recognition software belongs to the bigger family of speech recognition software, which are directed towards converting spoken words into text (cf. Footnote 16). Whereas speech recognition software is able to convert speech that does not belong to a specified speaker, voice recognition software needs to be trained to a particular voice. At the moment, speech recognition software can only handle predefined commands such as in cell phones ("call home") or in navigation ("find address such and so"). As a result, for the transcription of interview data, one should turn to voice recognition software. [48]
I have experimented twice with Dragon Naturally Speaking30), Versions 7 (2005) and 10 (2010). In both experiments the interviewer trained the software and tried to have it transcribe individual, one-to-one interviews. The results contained so many mistakes, that there was not enough time gain to make this a serious replacement procedure for manual transcription. A similar experience is described by DEMPSTER and WOODS (2011) for the data on the KWALON Experiment, and by DRESING, PEHL and LOMBARDO (2008). [49]
From my experiments and the one mentioned by DEMPSTER and WOODS, it seems voice recognition software is at the moment more geared towards standardized speech-to-text transformation (as in correspondence, invoices and such within a company) than towards the complex world of qualitative interviewing. [50]
6.2 Direct coding on data segments in QDA software
Another alternative for transcription could be direct coding on audio or video files instead of transcribing those files. I have experimented with direct coding on audio files myself, and asked my students and researchers at a Computer Assisted Qualitative Research (CAQR) Conference in Lisbon (2010) about their experiences. [51]
6.2.1 An experiment with direct coding on audio in ATLAS.ti
My own experiment
I have experimented with direct coding on audio files for two focus groups31) in ATLAS.ti, versions 5 and 6. In both versions, it does not seem a real alternative to me, for technical as well as analytical reasons. Technically, it is not possible yet to see which codes are attached to which data segments (quotations) along a timeline of the media. The only way to approximate this is to open a network view32) on a quotation to see which codes are linked to it. Besides that, the creation of a quotation on a media file is divided into three separate steps, which is quite laborious and not very intuitive. For the moment then, this procedure is hardly inviting researchers to refrain from transcription. However, this whole procedure will be changed and made more visible and intuitive in the next version33). SILVER and PATASHNICK (2011, this issue), report that in NVivo 8, coding on audio and video directly is not a smooth process either, as precisely selecting audio or video segments to directly code is a difficult process. [52]
On an analytical level, direct coding did not appeal to me either. Being used to working with transcripts in analyzing, I felt directly coding audio went way too fast. I did not have time to reflect on what I heard, nor could I read what was being said. And although I am not a brain researcher or cognitive specialist, the elimination of the visual stimulus of reading does seem to have some effect on my analysis. It seems as if in reading and rereading the transcript, my brain gets time to process the text and decide how to code or analyze it. I missed this in coding directly on audio, and repetitive listening to the audio file did not solve my problem. This was partly due to the speed with which the audio file is played back and partly caused by the current difficulty in creating a segment within an audio file. [53]
My students' experiment34)
I wondered if my experiences may be understood as being related to a "generation effect"? Would my students, coming from a different era and not being used to analyzing transcripts, experience the same frustrations as I did with directly coding audio data? So I devised a small experiment, where I asked students to interview a subject twice, and then transcribe the first interview before coding it, and code the second interview directly on audio in ATLAS.ti. I made sure not to reveal during class what had been my own experiences and reflections I taught them the easiest way of direct coding on an audio file I was aware of, and asked them to reflect on the process in their papers. To my surprise, they seemed to have similar feelings to mine. One of the great advantages of direct coding on audio files for my students was the time gained in not transcribing, although they reported summarizing or transcribing data segments in the comment box alongside directly coding the audio35). Another advantage was that in analyzing the audio file, data segments that did not seem relevant, were excluded or summarized in a few words, so the "transcription" time of those segments was reduced. Some of my students wondered whether they had been selecting segments of data too quickly, due to the process of listening as compared to reading. Another advantage was the constant hearing of the voice of the respondent, which one student describes as "stay[ing] in touch with the respondent." And of course, hearing the intonation was helpful during analysis, as it aids the interpretation of what was said. [54]
Reported disadvantages of coding the audio directly mentioned by the students were for instance that one becomes sloppy easily in rephrasing the respondent. Another disadvantage was that students reported forgetting whole parts of the dataset after the initial analytic round, because they were never listened to again. Some mentioned that it took more effort to code directly than to read transcripts. Some students therefore chose to transcribe anyhow, because they did not like directly coding audio files and found it difficult to keep track of what they were doing. The searching of audio files is reported to be far more difficult and they thought it a lot easier to read back a transcript several times as compared to listening back to the audio several times. [55]
As all of this was quite surprising to me, I decided to ask some peers, attending a small CAQR Conference, about their experiences. This is reported in the next section. [56]
6.2.2 Researchers about their working procedures
In order to be able to compare the use of a transcript versus direct coding on an audio file, I devised a small questionnaire, which was distributed to attendees at a CAQR Conference. The questionnaire asked about the data collection methods they use, whether or not they transcribe their data, which system for transcription they use, whether they use QDA software, if they have had experience with coding directly on audio or video files, and how they would compare that with working on a transcript. From the 26 researchers who responded to the questionnaire, 22 could be used in the table below36). They are entered in the table according to their years of experience in qualitative research. Table 1 summarizes their answers
Table 1: Results from questionnaire distributed at CAQR Conference 2010 (click here to download) [57]
The sample is quite nicely dispersed regarding years of experience, the QDA software one uses (most use either ATLAS.ti, MAXQDA and/or NVivo), and whether or not they code media files directly. Just under half the sample (10 out of 22) have experience in direct coding. Most of these respondents have over 5 years of experience in qualitative research (8 out of 10), and most even 15 or more years of experience (6 out of 8). [58]
It seems as if NVivo users in this small sample are slightly more inclined to use direct coding as compared to ATLAS.ti users (6 "Yes" versus 3 "No" in NVivo, "6" Yes versus "5" No in ATLAS.ti). MAXQDA and Transana do not currently provide direct coding on media files, so those users are an obligatory "No." So here is a question, which fits the original ideas for the KWALON experiment nicely: what exactly is the role of user-friendliness of QDA software and tools available in that software for the development of qualitative research and qualitative analysis methods? That is a question we can pursue in our next experiment and conference! [59]
Another issue addressed above, the popularity of interviewing as a data collection method, which is being recorded and consecutively being transcribed in the pragmatic format, is again confirmed. All of the researchers in this sample transcribed their recorded interview data (20 out of 22), use the pragmatic transcription format, sometimes alongside another (Jeffersonian or gisted). The collection of visual data in this sample is confined to a small group, which is consistent with my experience in training researchers in The Netherlands. Interviewing is still the most popular method for qualitative data collection, but this is slowly changing into (adding) visual data (cf. KNOBLAUCH et al., 2008b). [60]
These results seem to be in favor of recorded data, which get transcribed in some way or another. The next sections will describe how researchers, attending the conference, evaluated transcription as a process and how they evaluated direct coding. [61]
6.2.3 Researchers about transcription and direct coding on media files
During the CAQR Conference, researchers were also asked to list on two separate flip charts factors they considered as "Complaints/Down sides of transcription" and "Cheers/Celebrating transcription." Once someone had listed a feeling about or experience with transcribing or working with transcripts, others would enter marks behind the experience, thus confirming this feeling or experience. The results are summarized in Table 2 below. The points mentioned are entered in the table according to the number of identification markers by other researchers.
|
Complaints about transcription |
Total |
Cheers about transcription |
Total |
|
Time consuming |
19 |
"Feeling" the data |
8 |
|
Accuracy/Audio quality |
8 |
Start analysis |
8 |
|
Dull |
7 |
Reflect on interview process (how I did it) |
5 |
|
Expensive |
4 |
"Know well" your data and subjects |
4 |
|
"Heart breaking and soul destroying" |
2 |
More complete/accurate record of event |
2 |
|
Hearing voices later on |
1 |
Make scanning data easier |
2 |
|
|
|
Reviewing is faster than listening to original audio file/needed for ... (?) |
2 |
|
|
|
Can't (?) apply my methodology without it |
1 |
|
|
|
Take in account non verbal information |
1 |
|
|
|
Jobs for students |
1 |
Table 2: Complaints and cheers about transcription during CAQR Conference 2010 [62]
It seems the diversity in positive aspects about transcribing and/or using transcripts quite exceeds the negative, the latter mainly dealing with the time required, the tediousness of the job, and the dependency on good quality recording. On the positive side, the aspects mentioned relate to immersion in data through transcribing and using this as a starting point for analysis, as well as making it easier to find things in the data, being a more accurate strategy, being more efficient to work with, and using transcription as a reflective tool for interview quality. [63]
One of the open questions on the questionnaire concerned the comparison of experiences with transcripts versus direct coding. With regard to direct coding, researchers working with NVivo 8 commented on the easiness of coding on audio/video files, as opposed to those working with ATLAS.ti 6. Both thought it is quite time consuming to directly code audio/video data, as it is complicated to choose the right segment for coding. There was a request for high-speed segmenting of video data, which is not possible with current QDA software. In NVivo, it seems the quality of the recording is an issue. Both ATLAS.ti and NVivo have problems with creating output of coded audio/video segments, so in the end it is cumbersome to get an overview of what is actually going on in the dataset. Direct coding on video is considered adequate for broad coding, whereas for fine coding on video it was felt that one would need a transcript. For audio files, it is assumed one would need a transcript always. Researchers in this sample think the value of direct coding lies in being able to hear what is said, that video is useful if the focus is on interaction (as well as on the content), but there is fear of losing pieces of data which are un-coded, much like my students reported. [64]
On the other hand, regarding the use of transcripts in comparison, the reading of transcripts is more time-efficient than listening to audio files. Besides that, transcripts are searchable. For conversation and discourse analysis, transcripts seem the better option. Refinement of the tools currently available in QDA software, combined with the opportunity to link transcript segments to audio/video segments as desired, is thought to enable one to skip transcription for video data. This would not be true for audio data which are thought to need transcription regardless, but would gain a lot in linking them to the transcript, as is currently possible in ATLAS.ti, MAXQDA, NVivo, and Transana. [65]
These results are quite interesting, if we compare them to the experiment of me and my students. One might ask whether experienced qualitative researchers are more inclined to experiment with new procedures? Or whether more experienced researcher are more inclined to work with QDA software? From my small experiments, of course these questions cannot be answered. Another angle for a hypothesis could be, if persons using QDA software (for some time) are keener to try out new things? These would be interesting questions to further pursue. [66]
So far, I have been looking at different experiences and feelings about the manual transcription of data, working with transcripts during analysis, direct coding of audio and video data and automated transcription via voice recognition software. What can be learnt from all these different experiences, working methods, and authors? In the next section some recommendations in devising your own transcription format, geared towards the use of QDA software, will be explicated. [67]
7. Devising Your Own Transcript in Combination with QDA Software
Having worked through the several options which technological developments have brought and will keep on bringing, until now there still seems to be a need for transcription. With the option of linking transcripts to media files and possibly even several transcripts alongside each other, other forms of pragmatic or gisted transcript might become feasible if one designs some kind of protocol for each project, stating things that need transcription. In this section, I will describe some tips to consider in making your own pragmatic transcript, whether or not this is used alongside a gisted transcript. [68]
McLELLAN, MacQUEEN and NEIDIG (2003) describe the development of a transcription protocol with special regard for the subsequent analysis using QDA software. As shown before, the format of the transcript is a function of the analysis the researcher is planning, and thus will be susceptible to those needs. Apart from the type of analysis one intends to apply to the data, the type of nonverbal contextual information needed for the analysis will be included in the transcript as well, either in separate transcripts or as annotations linked to the transcript. The nonverbal contextual information included in transcripts of recorded interviews might entail the following: including observations of facial expression and body language during the interview, intonation of things being said, timing silences, noting laughter and other sounds being made during the interview, and describing the setting where the interview took place and possible others being there. If visual data are used, which include even more layers of possible transcription, it is possible to imagine that the visible nonverbal contextual information gets described as well, as I described before. The theoretical stand one takes might also influence the transcript (e.g., conversation analysis versus market research). [69]
The transcript can thus represent the recorded data to different degrees. One of the most popular transcription formats is the pragmatic transcription, which I now would like to define as: a verbatim transcription format, with varying add-ons37) in contextual and nonverbal information, depending on the researchers' needs in analysis, and which excludes stuttering and timing of silences and pauses. As such, this can be seen as a light version of Jeffersonian transcription38), which if the transcript is seamlessly linked to the media file, might even be "rich" enough for conversation analysis and such linguistic type studies. In that regard, the adoption of QDA software-proof transcription will save time and yet keep the possibility of rigor within the analysis. [70]
In devising your own pragmatic transcription format, the seven rules of MERGENTHALER and STINSON (1992), cited by McLELLAN et al. (2003, p.65) can be useful:
"Preserve the morphologic naturalness of transcription. Keep word forms, the form of commentaries, and the use of punctuation as close as possible to speech presentation and consistent with what is typically acceptable in written text.
Preserve the naturalness of the transcript structure. Keep text clearly structured by speech markers (i.e., like printed versions of plays or movie scripts).
The transcript should be an exact reproduction. Generate a verbatim account. Do not prematurely reduce text.
The transcription rules should be universal. Make transcripts suitable for both human/researcher and computer use.
The transcription rules should be complete. Transcribers should require only these rules to prepare transcripts. Everyday language competence rather than specific knowledge (e.g., linguistic theories) should be required.
The transcription rules should be independent. Transcription standards should be independent of transcribers as well as understandable and applicable by researchers or third parties.
The transcription rules should be intellectually elegant. Keep rules limited in number, simple, and easy to learn." [71]
In this concluding section, I will look back at the different developments mentioned earlier, and reflect on what they mean for data collection and analysis procedures. In addition, I will try to look into the future, and consider how technological advancements could help the research community further. [72]
8.1 Technical developments changing data collection and transcription
8.1.1 Influence of technology on data collection
As discussed above, the possibility of recording during data collection, be it visual or verbal, has greatly influenced the process of data collection. According to GUBRIUM and HOLSTEIN (2002, p.9) the interview has become the predominant data collection strategy. They even speak of "the interview society," which has greatly enhanced the "democratization of opinion." In addition, there seems to be a "pictorial turn"39) in the last decades, making us more and more visually oriented. As such, this can be termed an era of self-disclosure, be it in an interview, in visual imagery, or both. [73]
8.1.2 Influence of technology on transcription procedures
The decision about whether to transcribe recorded data is a separate one, such that recording does not automatically imply transcription. The notion of transcription mirrors the idea of a transcript as a direct reflection of reality, because of the accuracy of the recording (SCHENSUL, SCHENSUL & LeCOMPTE, 1999; LAPADAT & LINDSAY, 1999), and it is widespread. As such, a recording does reflect the reality of what is said or done (if the quality of recording is adequate). But this idea of "transcription as reality" does not deal with the issue of language and conduct being multifaceted and multi-interpretable, amongst others because of the way it is represented. This effect might be intuitively clear for the reproduction of visual data in some transcript, but it can be as much an issue with verbal data. MISHLER (2003), who experimented with different formats of transcribing the same text, based on an audio file, illustrates quite interestingly what effect this might have on our interpretation of that text. As such, the format of the transcript can have strong consequences for the interpretation of it, which suggests that one would always need the recording alongside. And this is where the development of QDA software can play a decisive role, either by direct coding of media files or by synchronizing transcripts and media files such that in analyzing, the researcher has both available at the same time. I will deal with that issue in more detail below. For now it suffices to say that the separation of verbal and visual transcription into multiple transcripts, combined with seamless linking of transcripts and media file (synchronization) seems to be the procedure which will dominate into the future. [74]
In the working procedures of transcribing, technical developments have certainly eased the way and possibly have had an influence in expanding the formats used. Originally these developments were of a mechanical nature, but nowadays the digital revolution has found its way here as well, making transcription a lot easier with specialized software for the job. The total automation of transcription via voice recognition software has proven not to be feasible yet. We will therefore have to go on doing this manually, if indeed we wish to transcribe our data. Rules for devising your own pragmatic transcription format geared towards the use of QDA software were introduced. With regard to the former, it might be advisable to do the transcribing within the QDA software one will use for the analysis, as this enables seamless linkage and the possibility of entering annotations and analytical reflections whilst transcribing. [75]
As computers and software are spoiling us with their speed of doing certain tasks, and time becomes more and more of a commodity, researchers are questioning the necessity of transcription. An alternative to transcription might be found in the option of direct coding on audio or video files, which is currently offered by several QDA software packages. I will turn to this in the next section. [76]
8.2 QDA software changing analysis procedures
In general, analytic quality and rigor is enhanced by the automation of certain tasks (e.g., keeping track of all the objects that are created and linked with each other, searching the dataset, getting segments out of the dataset based on their coding), while the analysis itself can be greatly improved by the systematic use of certain tools (e.g., linking different objects in the dataset with one another for different purposes, visualizing relationships/links between objects, offering the possibility of annotating every object in the project for different purposes). [77]
Having worked both in the "manual analysis" era and in the current QDA software era, I have developed analysis strategies in different projects because certain tools became available in QDA software. As such, software has affected my methods of analysis. Most of my self-devised strategies evolve using the network view in ATLAS.ti, as a means of visualizing hypotheses I have about the data, or grounding them into the data. This helps me to understand more clearly what it is I am doing or what it is I am seeing in the data. So I develop a new way of using the network view every time that seems appropriate, given the data and my research question. [78]
Another tool in QDA software which has influenced my analysis is the ease of querying the dataset, once it has been coded. Because of the ease of constantly (re)organizing the dataset and codes differently using filtering options, I utilize the dataset in a far more rigorous way than I otherwise would have done. [79]
The annotation tools (comments and memos in ATLAS.ti) make it unnecessary to have a big file filled with bits and pieces of paper, reflecting ideas, hypotheses, things-to-do lists and such for my project. Because I can now have everything in one place, an overview of the project is greatly enhanced and there is less chance of losing things. Besides that, the traceability of what I have been doing has improved enormously, thus improving the transparency of the research project, thus adding to its reliability. SILVER and PATASHNICK (2011, this issue, Figure 9) show how word processing software can be used for visual annotation of still images, to draw attention to certain parts of the photo during analysis. This option adds another analytic possibility as it is different from the annotation tools currently available within QDA software. From an analytical point of view, this type of annotation for imagery would certainly be quite interesting. [80]
Hyperlinking is another tool in QDA software that opens new doors to analysis. It can be used either to link data based on chronological order (for instance, the description of some kind of event one is researching) or on an argumentative level, for instance the argumentation surrounding some kind of policy decision. Dario DA RE40) showed an example of hyperlinking chunks of video data in ATLAS.ti, and using this tool for creating the structure of his video report. DICKS et al. (2006) refer to hyperlinking and hypermedia, which is yet another form of working with your dataset, and DI GREGORIO (2010), in a presentation at the CAQR Conference, showed several new developments in QDA software and related them to future trends in qualitative research. [81]
With QDA software lately being able to deal with PDF files, a new world of research objects, which are downloadable from the Internet, becomes available. Other ways of QDA software influencing our analysis strategies will be dealt with below. [82]
8.2.1 Direct coding on media files
With the ability to directly code media files, there will likely be yet another shift in analytic procedures. The lack of real enthusiasm amongst my students, researchers at the conference mentioned above, and myself for such tools might be caused partly because current QDA software is not yet optimized for this task. It might just be a matter of time, as some of the problems mentioned regarding direct coding of media files can be solved or at least diminished with technical solutions. [83]
The possibility of slowing down the audio or video file while coding directly, thus having more time to listen to and reflect upon what is being said before deciding how to code it, is currently just available in NVivo and Transana, and would be on my ATLAS.ti wish list for sure, as it would add to the quality of analysis. Normal speed of media files is way too fast for direct coding. It would not solve the problem mentioned of becoming sloppy in rephrasing the respondent, in the reporting phase however, because of the lack of a transcript. It will be obvious that the analytic quality of direct coding on media files remains a point for further investigation as this indeed might add on too much interpretation on the side of the researcher. [84]
Some of the other tools currently available in transcription software (cf. Section 3.1) might fit in nicely as well, specifically if one wishes to transcribe directly within a QDA software. In addition, the option of seeing how an audio or video file has been coded in a similar way as is possible with text will be of great help, as will the possibility of coding directly in one go instead of having to perform multiple tasks before a code is linked to a segment. Another technical solution could be sought for the workaround that people apparently want to transcribe bits and pieces during direct coding. It could be made easier to do this in a place that can be searched, such that whatever had been transcribed (if the whole media file is not transcribed) would be searchable. [85]
Presumably not yet possible as it is quite complicated, but maybe for the future wish list would be the option of searching audio and video files for spoken words. Yet there is another issue regarding direct coding of media files. Researchers who have experimented with this complained that it is more time consuming and less systematic as compared to working with transcripts, which is quite surprising. As such, I am not convinced that this is a technological problem. It seems that the process of reading is conceived differently than is direct coding, and definitely not all researchers prefer the latter. [86]
To conclude this section on the direct coding of media files it is important to mention the problem of the multi-layeredness of video data. If non-verbal information is the research goal, then probably it would be okay to skip transcription and code directly on the media file. But if the verbal information is a focus (as well), then one would probably at least need a gisted transcript. [87]
8.2.2 Linking a transcript with its media file
The development mentioned earlier, is where transcript and media file are linked in such a way that one can jump between transcript and exact matching points in the media file, which is possible in ATLAS.ti, DRS, MAXqda, NVivo and Transana (see SILVER & PATASHNICK, 2011, this issue). This development opens new possibilities for combinations of pragmatic and gisted transcripts, or making all kinds of additional information in Jeffersonian or Goodwinian transcripts obsolete, as one can hear or see the intonation or non-verbal behavior right on the spot. This option can therefore save enormous amounts of transcription time, specifically in the Jeffersonian or Goodwinian format. [88]
I do not agree with CLAYMAN and TEAS GILL (2004, p.594, Transcripts 1 and 2) however, who suggest varying levels of detail in the (Jeffersonian) transcript41) and having the most detailed transcript for chunks of data that get the most analytic attention. This, I think, would be a decision made far too early in the process of analysis (during transcription), and as such, comparable with experiences mentioned on direct coding). It is exactly for this dilemma, that QDA software offers the option of linking transcript and media file. If one would make a elaborated gisted transcript (a la DEMPSTER & WOODS, 2011, see the example in Figure 1), linked to that exact spot in the media file for chunks of data that seem less important, and pragmatic transcripts for all the rest, one would have the original media file at hand every time one is dealing with either transcript. Insights about the data that occur later on in the analysis after being immersed in the data for a while (which is a very familiar phenomenon to me, and I am sure, to a lot of qualitative analysts), can be easily cross-referenced with the whole dataset, as everything is easily accessible in the transcript and in media file. [89]
8.2.3 Limitations of QDA software
Some things QDA software cannot do, however. For instance, many of those who attend my software training, seem to expect that one of the great advantages of using software is the speeding up of data analysis, by using automated word searches and maybe automated coding. Another idea people seem to have about QDA software is that it is going to do their analysis for them, which obviously is not the case. This, in my opinion, is not the main feature of qualitative analysis, nor is it the main purpose of QDA software. I will attend to both points below [90]
One of the main features of qualitative research and hence of qualitative data is the "richness," both in meaning and in volume. The richness in volume is an area, where automated QDA-software tools can be interesting, specifically on a textual dataset, as the search options in those software only handle that kind of data. The word searching tool of all the software will do this, and even automatically code some predefined area as well. And it is precisely this point that marks the weakness of automated coding until now. As people don't speak in predefined areas, nor in predefined words, automated tools will miss out on a lot of subtle meaning, which is "between the lines" or in other characteristics of the message (such as intonation, pace or similar words used differently in context, such as the word "friu" in my Aruba example, see Table 1). [91]
The richness in meaning of qualitative data then is not only represented by the way data are being collected (mostly open, in-depth and inductively, with mostly language or conduct as the conveyor of meaning, or both), but certainly by the analysis applied to them as well. To that end, the interpretation of qualitative data cannot be done by deductively organized automated tools, but needs the human eye and interpretative act, using an inductive and maybe even abductive approach (cf. EVERS, 2007; REICHERTZ, 2009). Most of the time, it will need intimate knowledge of the culture at hand as well. Immersion in the data is therefore, in my opinion, a prerequisite for qualitative data analysis. And to that end, what has been termed elsewhere "thick analysis" (EVERS & VAN STAA, 2010) may be a way of enhancing both the richness of analysis as the validity of it. [92]
It may be possible in the future for the researcher to be able to teach QDA software how to interpret in context. Interesting developments in this regard are the automated placement in context done by Cassandre (see LEJEUNE, 2011, this issue), which really facilitates halfway automated coding, or the "learning" abilities described for Veyor© (see ATKISSON, MONAGHAN & BRENT, 2010) which enable the researcher to teach the software to code automatically, based on a sample coding done prior by the researcher, and a testing procedure afterwards. [93]
Where developments like this will bring us in analyzing our data, however, needs to be further explored, as the emphasis now seems to be on quantifying the output. This then, I believe, is again ignoring the richness of qualitative data, as its meaning is not in quantities, but in describing and providing possible explanations of the diversity and range of the human experience. [94]
1) I would like to thank Marjan de BRUIN-MAXWELL (University of The West Indies, Jamaica) for helping me downsizing an earlier version of this paper. <back>
2) A similar trend is mentioned for the United Kingdom (DICKS, MASON, COFFEY & ATKINSON, 2006), for Germany (Katja MRUCK, personal communication) and Belgium (Bart PEETERS, personal communication). <back>
3) ATLAS.ti offered this option for quite some time, but the functionality is not yet optimized. Apparently this will change in the upcoming version. NVivo offers this option from 2008 onwards. <back>
4) It is hard, however, to pinpoint an exact point of the origin of anthropology as a scholarly discipline, because several authors use different criteria to do so. BARTH et al. (2005, p.4) place the beginning of scholarly anthropology in the UK at 1837, with the formation of the Aborigines Protection Society. GINGRICH (2005, p.84) sees the formation of the Berlin Society for Anthropology, Ethnology, and Prehistory in 1867 as institutionalization of "Völkerkunde" (Anthropology) in Germany, while PARKIN (2005, pp.167, 169) mentions several learned societies for France (starting with the short-lived Société des Observateurs de l'Homme in 1799) and the first chair of anthropology in 1855 in the Musée d'Histoire Naturelle. SILVERMAN (2005, pp.259-260) mentions the Bureau of American Ethnology, and the Anthropological Society of Washington, both established in 1879. VERMEULEN (1997, p.15) cites the first professorship in Anthropology at the University of Leiden in 1877, which originated from earlier educational institutions for military (Breda in 1836) and colonial administrators (Leiden, 1864-1877). <back>
5) Until the 1980s in Western Europe, this genre was only taught at Leiden University, The Netherlands, and the University of Nanterres, Paris 10 in France. Since then its use has spread into the United Kingdom, Germany, Spain, Portugal, and Norway and is now taught in these countries as well (personal communication Metje POSTMA). <back>
6) A Dutch online social network. <back>
7) It is important to distinguish between visual data collection and ethnographic film-making (or etno-cinema in France).The latter is oriented towards a comprehensive documentary film as the outcome of the research project, presenting knowledge gained in that format; the former is geared towards generating data in that format for analysis, without necessarily wanting to present the outcome in a cinematic format. I want to thank Metje POSTMA for sharpening my understanding in this regard. <back>
8) Examples of national initiatives in this respect are the UK Data Archive in England, DANS in The Netherlands, and ALLF in Germany. <back>
9) Although nowadays this may seem something from the far past, it was only 20 years ago that during my Master thesis' fieldwork in Aruba (1989), I had only a mechanic typewriter available, some Tipp-Ex, and a Walkman for a recording device. <back>
10) For analysis, the introduction of Xerox copying machines was quite useful, as it enabled one to copy the transcript several times in order to manipulate the hardcopy in analyzing it. <back>
11) Freewares are F4 and F5, Express Scribe, while Transana is relatively cheap open source software devised for video analysis, and Hypertranscribe is a commercial software. All of them are multiplatform (OS-X, Windows, and/or Linux) available. Transcriber has a button to indicate overlapping speech. Transana is a combination of a transcription software with specific buttons related to the Jeffersonian transcription format, used in Conversation Analysis (see Section 5.1.2). <back>
12) For example, ATLAS.ti and Winmax (now MAXQDA) in Germany, Ethnograph and HyperRESEARCH in the US, NUD*IST and NVivo in Australia, WinRelan in Austria and KWALITAN in The Netherlands. <back>
13) The names of tools mentioned are from ATLAS.ti, as this is the program I am most familiar with. <back>
14) I would want to thank Christina SILVER for making the distinction between transcription and description more explicit. It is a different conception from description in fieldnotes, as understood by CLIFFORD (1990, p.51). He describes it as "making a more or less coherent representation of an observed cultural reality," and as such uses the term description for elaborate fieldnotes, that include some interpretation and analytic reflections as well. <back>
15) Of course, the neutrality of transcription and description is subject to debate, as it is a transformation of one medium (verbal, gestures, interaction) to another (text). As such, it will influence our understanding and hence our interpretation of the resulting text. For further reading on this with regard to interview data, see KVALE (1996) and MISHLER (2003). <back>
16) A Dutch project organized by DANS, which is an initiative of the Royal Netherlands Academy of Arts & Sciences (KNAW) and the Netherlands Organization for Scientific Research (NWO), digitalized 250 interviews with War veterans and made these available in a data archive for the Dutch research community. To enable searching on the occurrence of certain words within those interviews, an open source software, The Oral History Annotation Tool, is currently being developed by the University of Nijmegen. The audio files are divided into units of one sentence, so the word search will look through all of the sentences in the dataset. The precision and recall is not yet clear, as this is "work in progress." Purpose is, to have researchers search through and add annotations to the data, in order to enrich the dataset further. The annotation tool uses open source algorithms to translate Dutch voice into text (personal communication Rene van HORIK). The Oral History Annotation Tool as such, I think, can be regarded as a speech recognition software. <back>
17) Based on my experiences with research(ers) in The Netherlands and a small research project I did amongst researchers (EVERS, 2003), I believe the pragmatic format to be the most popular format of transcription in The Netherlands. When I asked researchers from different countries attending the CAQR Conference in Lisbon, October 2010, in a questionnaire if they used Jeffersonian, summarizing or self—devised verbatim transcription, 20 out of 26 researchers responded to do the latter. The transcript examples used in SCHENSUL, LeCOMPTE, NASTASI and BORGATTI (1999) seem to be of this nature as well, as are the transcript in WOODS and DEMPSTER (2011, this issue) and DEMPSTER and WOODS (2011, this issue). <back>
18) The term "pragmatic" does not refer to pragmatism within linguistics, but pragmatism in devising a transcription format that suits your needs best, is a verbatim format, and has the best cost and time efficiency possible. <back>
19) For example, a Dutch colleague, Harry VAN DEN BERG, told me that in a recent research project based on oral history interviews with veterans, a pragmatic format was used to transcribe the interviews in which pauses and repetitions were included. In hindsight, he would have preferred to include emphasis, intonation and changes in volume as well (VAN DEN BERG & WOELDERS, 2010). For further information see http://www.watveteranenvertellen.nl/. <back>
20) "[" is used for overlapping speech, "[?]" is used when something cannot be deciphered, "(...)" is used for silence/hesitation, external disturbances of the interview are entered between brackets (e.g., someone enters room, telephone rings). <back>
21) CLAYMAN and TEAS GILL (2004, pp.593-594) give an illuminating example of the same transcript in a detailed, Jeffersonian way and in a simplified way to illustrate the effect of all the details included in a Jeffersonian transcript. <back>
22) In Appendix A, pp.215-216, he explains the transcription conventions used. <back>
23) Some symbols included in this transcript are: underlining a word indicates some form of stress, via pitch and/or amplitude, "::" colons implicate prolongation of the immediately prior sound, "[" brackets indicate overlap of speech, "=" indicates no gap between prior line and this one (TEN HAVE, 2007, Appendix A). <back>
24) For ease of comprehension, I have numbered the consecutive steps. <back>
25) Which is not used in the excerpt in Table 1. <back>
26) Dataset Aruba 1989, taken from D. (initial of respondent), p.6. <back>
27) TEN HAVE (2007, p.72) speaks of the "video branch of CA," originated by GOODWIN, further represented by HEATH. <back>
28) It was not possible to get a good reproduction for this article, interested parties can have a look at page 89, transcript 1 of Fragment 5.1, in the book itself, which is a Jeffersionan transcript of the verbal utterings, followed by transcript 2 of the same fragment on page 90, which are some shots in a video with a description of the visual behavior accompanying those verbal utterings. If the book is not available to you, you can have a look at page 152 in Appendix 1, which is attainable via the webshops that sell the book, to get a feel of this type of transcription. <back>
29) Personal communication David WOODS. <back>
30) For Mac users on OS-X it used to be ViaVoice (until 2003). Now it is called Dragon for Mac as well. <back>
31) Both lasted approximately three hours. <back>
32) A network view in ATLAS.ti is a visual picture of the links between codes and data segments or other objects in the project file. <back>
33) Personal communication Thomas MUHR. <back>
34) I am grateful and indebted to my students at the University for Humanistics, The Netherlands, to share their thoughts and experiences with me. <back>
35) The comment box is an annotation tool in ATLAS.ti. <back>
36) Four of them could not be entered in this table, due to missing or inadequate information on the questionnaire. The total of attendees was 35. <back>
37) One of the interesting add-ons could be the entering of silences that occur in natural pauses during the interview, on separate lines, preceded by the symbol "->" and without identifying a speaker. As such, this line then makes visible that the floor is open to all speakers again. With the current possibility of timestamps in transcription software, it does not seem necessary to time the pause, as this is visible in the timestamps. For an example see CLAYMAN and TEAS GILL (2004, p.595). <back>
38) Different from the one mentioned by CLAYMAN and TEAS GILL (2004), see Section 4, as the analytic decision taken during transcription in their proposal is not applicable here as the transcript is synchronized to the data file, thus enabling the full data to be considered during analysis. <back>
39) Term stems from personal communication with Metje POSTMA and comes from MITCHELL. See his "Picture Theory" (1994) for a critical discussion of this concept, which he places against the "linguistic turn" in philosophy as anxiety for a world dominated by images. <back>
40) CAQDAS 07 Conference, London 2007, organized by the CAQDAS Networking Project, University of Surrey, UK. <back>
41) They speak of Jeffersonian "simplified" and Jeffersonian "detailed." <back>
Ashmore, Malcolm & Reed, Darren (2000). Innocence and nostalgia in conversation analysis: The dynamic relations of tape and transcript. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 1(3), Art. 3, http://nbn-resolving.de/urn:nbn:de:0114-fqs000335 [Accessed: January 28, 2011].
Atkisson, Curtis; Monaghan, Colin & Brent, Edward (2010). Using computational techniques to fill the gap between qualitative
data analysis and text analysis. KWALON, 15(3), 6-20.
Ball, Susan & Gilligan, Chris (Eds.) (2010). Visualising migration and social division: Insights from social sciences and
the visual arts. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, http://www.qualitative-research.net/index.php/fqs/issue/view/34 [Accessed: January 28, 2011].
Barth, Fredrik; Gingrich, Andre; Parkin, Robert & Silverman, Sydel (2005). One discipline, four ways: British, German, French and American anthropology. The Halle lectures. Chicago: University of Chicago Press.
Berg, Harry van den & Woelders, Susan (2010) Frames, metaforen en vertelposities in verhalen van Nederlandse veteranen over militaire gevechtsacties. In Harry van den Berg, Stef Scagliola & Fred Wester (Eds.), Wat veteranen vertellen. Verschillende perspectieven op biografische interviews over ervaringen tijdens militaire operaties (pp.85-125). Amsterdam: Pallas Publications, Amsterdam University Press.
Bogdan, Robert C. & Knopp Biklen, Sari (2007). Qualitative research for education. An introduction to theories and methods (5th ed.). Boston: Pearson Education, Inc.
Bohnsack, Ralf (2009). Qualitative Bild- und Videointerpretation. Opladen: Verlag Barbara Budrich.
Bulmer, Martin (1986). The Chicago School of Sociology. Institutionalization, diversity, and the rise of sociological research. Chicago: The University of Chicago Press.
Clayman, Steven E. & Teas Gill, Virginia (2004). Conversation analysis. In Melissa Hardy & Alan Bryman (Eds.), Handbook of data analysis (pp.589-606). London: Sage.
Clifford, James (1990). Notes on (field)notes. In Roger Sanjek (Ed.), Fieldnotes. The makings of anthropology (pp.47-70). Ithaca, NY: Cornell University Press.
Coffey, Amanda & Atkinson, Paul (1996). Making sense of qualitative data. Complementary research strategies. Thousand Oaks: Sage.
Corti, Louise; Witzel, Andreas & Bishop, Libby (Eds.) (2005). Secondary analysis of qualitative data. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 6(1), http://www.qualitative-research.net/index.php/fqs/issue/view/13 [Accessed: January 28, 2011].
Dempster, Paul G. & Woods, David K. (2011). The economic crisis though the eyes of Transana. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 16, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101169 [Accessed: January 28, 2011].
Di Gregorio, Silvana (2010). Qualitative data analysis software development and future trends in qualitative research. Paper presented at Computer-Aided Qualitative Research Europe, Lisbon, October 7 and 8.
Dicks, Bella; Mason, Bruce; Coffey, Amanda & Atkinson, Paul (2006). Qualitative research and hypermedia. Ethnography for the digital age (2nd ed.). London: Sage.
Dimmendaal, Gerrit J. (2010). Language description and "the new paradigm": What linguists may learn from ethnocinematographers. Language Documentation and Conservation, 4, 152-158.
Dresing, Thorsten; Pehl, Thorsten & Lombardo, Claudia (2008). Schnellere Transkription durch Spracherkennung?. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(2), Art. 17, http://nbn-resolving.de/urn:nbn:de:0114-fqs0802174 [Accessed: January 28, 2011].
El Guindi, Fadwa (2004). Visual anthropology. Essential method and theory. Walnut Creek: Altamira Press.
Emerson, Robert M.; Fretz, Rachel I. & Shaw, Linda L. (1995). Writing ethnographic fieldnotes. Chicago: The University of Chicago Press.
Evers, Jeanine (2003). Ethische professionaliteit in de rapportage. In Fred Wester (Ed.), Rapporteren over kwalitatief onderzoek (pp.99-128). Den Haag: Lemma.
Evers, Jeanine (Ed.) (2007). Kwalitatief interviewen. Kunst èn kunde. Den Haag: Boom/Lemma.
Evers, Jeanine (2010). Coursemanual introduction to ATLAS.ti 6. The Hague, n.p.
Evers, Jeanine C. & van Staa, AnneLoes (2010). Qualitative analysis in case study. In Albert J. Mills, Gabrielle Durepos & Elden Wiebe (Eds.), Encyclopedia of case study research (Vol. 2, pp.749-757). Los Angeles: Sage.
Gibbs, Graham (2010). Two short videos of lectures on issues of transcription, Part 1 and 2, http://onlineqda.hud.ac.uk/movies/transcription/index.php [Accessed: January 30, 2011].
Gingrich, Andre (2005). The German-speaking countries. In Fredrik Barth, Andre Gingrich, Robert Parking & Sydel Silverman, One discipline, four ways: British, German, French, and American anthropology. The Halle lectures (pp.61-153). Chicago: University of Chicago Press.
Grassini, Cristina (Ed.) (2007). Skilled visions. Between apprenticeship and standards. New York: Berghahn Books.
Gubrium, Jaber F. & Holstein, James A. (2002). From the individual interview to the interview society. In Jaber F Gubrium & James A. Holstein (Eds.), Handbook of interview research. Context & method (pp.3-32). Thousand Oaks: Sage.
Have, Paul ten (2007). Doing conversation analysis (2nd ed.). Los Angeles: Sage.
Heath, Christian; Hindmarsh, Jon & Luff, Paul (2010). Video in qualitative research. Analysing social interaction in everyday life. Thousand Oaks: Sage.
Heaton, Janet (2004). Reworking qualitative data. London: Sage.
Henley, Paul (2010). The adventure of the real. Jean Rouch and the craft of ethnographic cinema. Chicago: The University of Chicago Press.
Jones, Kip; Gergen, Mary; Guiney Yallop, John J.; Lopez de Vallejo, Irene; Roberts, Brian & Wright, Peter (Eds.) (2008). Performative social science. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(2), http://www.qualitative-research.net/index.php/fqs/issue/view/10 [Accessed: January 28, 2011].
Knoblauch, Hubert; Baer, Alejandro; Laurier, Eric; Petschke, Sabine & Schnettler, Bernt (2008a). Visual methods. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(3), http://www.qualitative-research.net/index.php/fqs/issue/view/11 [Accessed: January 28, 2011].
Knoblauch, Hubert; Baer, Alejandro; Laurier, Eric; Petschke, Sabine &Schnettler, Bernt (2008b). Visual analysis. New developments in the interpretative analysis of video and photography. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(3), Art. 14, http://nbn-resolving.de/urn:nbn:de:0114-fqs0803148 [Accessed: January 28, 2011].
Konopásek, Zdeněk (2008). Making thinking visible with Atlas.ti: Computer assisted qualitative analysis as textual practices. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(2), Art. 12, http://nbn-resolving.de/urn:nbn:de:0114-fqs0802124 [Accessed: January 28, 2011].
Kvale, Steinar (1996). Interviews. An introduction to qualitative interviewing. Thousand Oaks: Sage.
Lapadat, Judith C. & Lindsay, Anne C. (1999). Transcription in research and practice: From standardization of technique to interpretive positionings. Qualitative Inquiry, 5, 64-86.
Lejeune, Christophe (2011). From normal business to financial crisis ... and back again. An illustration of the benefits of Cassandre for qualitative analysis. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 24, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101247 [Accessed: January 28, 2011].
Lutters, Wayne G. & Ackerman, Mark S. (1996). An introduction to the Chicago School of Sociology, http://userpages.umbc.edu/~lutters/pubs/1996_SWLNote96-1_Lutters,Ackerman.pdf [Accessed: December 26, 2010].
McLellan, Eleanor; MacQueen, Kathleen M. & Neidig, Judith L. (2003). Beyond the qualitative interview: Data preparation and transcription. Field Methods, 15, 63-84.
Mead, Margaret (1977). Letters from the field (1925-1975). New York: Harper & Row.
Mishler, Elliot G. (2003 [1991]). Representing discourse: The rhetoric of transcription. In Nigel Fielding (Ed.), Interviewing (pp.12-37). London: Sage.
Mitchell, W.J.T. (1994). Picture theory. Essays on verbal and visual representation. Chicago: University of Chicago Press.
Parkin, Robert (2005) The French-speaking countries. In Fredrik Barth, Andre Gingrich, Robert Parking & Sydel Silverman, One discipline, four ways: British, German, French, and American anthropology. The Halle lectures (pp.157-253). Chicago: University of Chicago Press.
Potter, Jonathan (2004). Discourse analysis. In Melissa Hardy & Alan Bryman (Eds.), Handbook of data analysis (pp.607-624). London: Sage.
Puchta, Claudia & Potter, Jonathan (2004). Focus group practice. London: Sage.
Reichertz, Jo (2009). Abduction: The logic of discovery of grounded theory. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 11(1), Art. 13, http://nbn-resolving.de/urn:nbn:de:0114-fqs1001135 [Accessed: January 28, 2011].
Rose, Gilian (2007). Visual methodologies. An introduction to the interpretation of visual materials (2nd ed.). London: Sage.
Ross, Jen (2010). Was that infinity or affinity? Applying insights from translation studies to qualitative research transcription. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 11(2), Art. 2, http://nbn-resolving.de/urn:nbn:de:0114-fqs100223 [Accessed: January 28, 2011].
Sanjek, Roger (Ed.) (1990) Fieldnotes. The makings of anthropology. Ithaca: Cornell University Press
Saunders, Barry (2007). Visual apprenticeship in the age of the mechanical viewbox. In Christina Grasseni (Ed.), Skilled visions. Between apprenticeship and standards (pp. 145-165). New York: Berghahn Books.
Schensul, Jean J.; LeCompte, Margaret D.; Nastasi, Bonnie K. & Borgatti, Stephen P. (1999). Enhanced ethnographic methods. Audiovisual techniques, focused group interviews, and elicitation techniques. Ethnographers toolkit 3. Walnut Creek: Altamira Press.
Schensul, Stephen L.; Schensul, Jean J. & LeCompte, Margaret D. (1999). Essential ethnographic methods. Observations, interviews and questionnaires. Ethnographers toolkit 2. Walnut Creek: Altamira Press.
Silver, Christina & Patashnick, Jennifer (2011). Finding fidelity: Advancing audiovisual analysis using software. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 37, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101372 [Accessed: January 28, 2011].
Silverman, Sydel (2005). The United States. In Fredrik Barth, Andre Gingrich, Robert Parking & Sydel Silverman, One discipline, four ways: British, German, French, and American anthropology. The Halle lectures (pp. 257-347). Chicago: University of Chicago Press.
Stanczak, Gregory C. (Ed.) (2007). Visual research methods. Image, society and representation. Los Angeles: Sage.
Stocking, George W. Jr. (2001). The ethnographer's magic: Fieldwork in British anthropology from Tylor to Malinowski. In Alan Bryman (Ed.), Ethnography. Sage Benchmarks in research methods (Vol. I, pp.3-46). London: Sage.
Swinnen, Johan (Ed.) (2010). Anders zichtbaar. Zingeving en humanisering in de beeldcultuur. Brussel: VUB Press.
Vermeulen, Han F. (1997). Van Instituut voor CA en SNWV tot Vakgroep CA/SNWS (1955-1997): professionalisering van de antropo-sociologie in Leiden. In Henri J.M. Claessen & Han F. Vermeulen (Eds.), Veertig jaren onderweg. Lezingen gehouden op de eerste alumnidag van de vakgroep Culturele Antropologie en Sociologie der Niet-Westerse Samenlevingen te Leiden (pp.13-55). Leiden: DSWO Press, Studies in Social Anthropology.
Witzel, Andreas; Medjedović, Irena & Kretzer, Susanne (2008). Secondary analysis of qualitative data. Historical Social Research, 33(3).
Woods, David K. & Dempster, Paul G. (2011). Tales from the bleeding edge: The qualitative analysis of complex video data using Transana. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 17, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101172 [Accessed: January 28, 2011].
Jeanine EVERS is the founder and manager for the KWALON training division, which provides training in qualitative research methods and QDA software in The Netherlands from 2004 onwards. KWALON is the Dutch Platform for Qualitative Research, which promotes the use of qualitative research and strives to enhance the quality of qualitative research in The Netherlands. She has been an active member of KWALON from 1995 onwards. Besides that, she is a lecturer in qualitative research methods at the University for Humanistics in Utrecht, and she has her own company, Evers Research & Training, which provides training and consultancy services for groups and individual researchers.
Contact:
Jeanine C. Evers
University for Humanistics
P.O. Box 797
3500 AT Utrecht
The Netherlands
E-mail: j.evers@uvh.nl or jcevers@eversresearch.nl
URL: http://www.eversresearch.nl/
Evers, Jeanine C. (2011). From the Past into the Future. How Technological Developments Change Our Ways of Data Collection, Transcription and Analysis [94 paragraphs]. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 12(1), Art. 38, http://nbn-resolving.de/urn:nbn:de:0114-fqs1101381.

Creative Commons Attribution 4.0 International License